
2.6.1
Коэффициент детерминации.
Для оценки качества построенной модели
регрессии можно использовать коэффициент
детерминации
![]() .
.
Коэффициент детерминации может быть
вычислен по формуле:
 .
.
С другой стороны,
для парной линейной регрессии верно
равенство:
![]() .
.
При
близости значения коэффициента
детерминации к 1 говорят, что уравнение
регрессии статистически значимо и
фактор
![]() оказывает сильное воздействие на
оказывает сильное воздействие на
результирующий признак![]() .
.
При анализе модели
парной линейной регрессии по значению
коэффициента детерминации можно сделать
следующие предварительные выводы о
качестве модели:
-
Если
 ,
,
то будем считать, что использование
регрессионной модели для аппроксимации
зависимости между переменными и
и статистически необоснованно.
статистически необоснованно. -
Если
 ,
,
то использование регрессионной модели
возможно, но после оценивания параметров
модель подлежит дальнейшему многостороннему
статистическому анализу. -
Если
 ,
,
то будем. считать, что у нас есть основания
для использования регрессионной модели
при анализе поведения переменной.
2.6.2 Средняя ошибка аппроксимации.
Другой
показатель качества построенной модели
–– среднее относительное отклонение
расчетных значений от фактических или
средняя
ошибка аппроксимации:
![]() .
.
Построенное
уравнение регрессии считается
удовлетворительным, если значение
![]() не превышает 10% – 12% .
не превышает 10% – 12% .
3. Пример.
По
21 региону страны изучается зависимость
розничной продажи телевизоров (![]() )
)
от среднедушевого денежного дохода в
месяц (![]() ).
).
|
Номер региона |
Среднедушевой |
Объем |
|
1 |
2 |
28 |
|
2 |
2,4 |
21,3 |
|
3 |
2,1 |
21 |
|
4 |
2,6 |
23,3 |
|
5 |
1,7 |
15,8 |
|
6 |
2,5 |
21,9 |
|
7 |
2,4 |
20 |
|
8 |
2,6 |
22 |
|
9 |
2,8 |
23,9 |
|
10 |
2,6 |
26 |
|
11 |
2,6 |
24,6 |
|
12 |
2,5 |
21 |
|
13 |
2,9 |
27 |
|
14 |
2,6 |
21 |
|
15 |
2,2 |
24 |
|
16 |
2,6 |
24 |
|
17 |
3,3 |
31,9 |
|
18 |
3,9 |
33 |
|
19 |
4 |
35,4 |
|
20 |
3,7 |
34 |
|
21 |
3,4 |
31 |
Необходимо
найти зависимость, наилучшим образом
отражающую связь между переменными
![]()
и
![]() .
.
Рассмотрим вопрос
применения модели линейной регрессии
в этой задаче.
Построим
поле корреляции, т.е. нанесем исходные
данные на координатную плоскость. Для
этого воспользуемся, например,
возможностями MS
Excel
2003.
Подготовим таблицу
исходных данных.

Нанесем на
координатную плоскость исходные данные:

Характер
расположения точек на графике дает нам
основание предположить, что искомая
функция регрессии линейная:
![]() .
.
Для оценки коэффициентов уравнения
регрессии необходимо составить и решить
систему нормальных уравнений ( ).
По исходным данным
рассчитываем необходимые суммы:
|
Номер региона |
|
|
|
|
|
|
1 |
2 |
28 |
56 |
4 |
784 |
|
2 |
2,4 |
21,3 |
51,12 |
5,76 |
453,69 |
|
3 |
2,1 |
21 |
44,1 |
4,41 |
441 |
|
4 |
2,6 |
23,3 |
60,58 |
6,76 |
542,89 |
|
5 |
1,7 |
15,8 |
26,86 |
2,89 |
249,64 |
|
6 |
2,5 |
21,9 |
54,75 |
6,25 |
479,61 |
|
7 |
2,4 |
20 |
48 |
5,76 |
400 |
|
8 |
2,6 |
22 |
57,2 |
6,76 |
484 |
|
9 |
2,8 |
23,9 |
66,92 |
7,84 |
571,21 |
|
10 |
2,6 |
26 |
67,6 |
6,76 |
676 |
|
11 |
2,6 |
24,6 |
63,96 |
6,76 |
605,16 |
|
12 |
2,5 |
21 |
52,5 |
6,25 |
441 |
|
13 |
2,9 |
27 |
78,3 |
8,41 |
729 |
|
14 |
2,6 |
21 |
54,6 |
6,76 |
441 |
|
15 |
2,2 |
24 |
52,8 |
4,84 |
576 |
|
16 |
2,6 |
24 |
62,4 |
6,76 |
576 |
|
17 |
3,3 |
31,9 |
105,27 |
10,89 |
1017,61 |
|
18 |
3,9 |
33 |
128,7 |
15,21 |
1089 |
|
19 |
4 |
35,4 |
141,6 |
16 |
1253,16 |
|
20 |
3,7 |
34 |
125,8 |
13,69 |
1156 |
|
21 |
3,4 |
31 |
105,4 |
11,56 |
961 |
|
Сумма |
57,4 |
530,1 |
1504,46 |
164,32 |
13926,97 |
Составляем систему
уравнений:

Имеем систему
линейных алгебраических уравнений,
которая может быть решена, например, по
формулам Крамера. Для этого вычислим
следующие определители:
![]()
![]()
![]()
Тогда, согласно
теореме Крамера,
![]()
![]()
Получаем уравнение
регрессии:
![]()
Величина
коэффициента регрессии
![]() означает, что увеличение среднедушевого
означает, что увеличение среднедушевого
месячного дохода на 1 тыс. руб. приведет
к увеличение объема розничной продажи
в среднем на 7 540 телевизоров. Коэффициент![]() в данном случае не имеет содержательной
в данном случае не имеет содержательной
интерпретации.
Оценим тесноту
линейной связи между переменными и
качество построенной модели в целом.
Для оценки тесноты
линейной зависимости рассчитаем
коэффициент детерминации. Для этого
необходимо провести ряд дополнительных
вычислений.
Прежде
всего, найдем выборочное
среднее
![]() по формуле:
по формуле:
![]() .
.
Для рассматриваемого
примера имеем:
![]()
Теперь произведем
расчет остальных вспомогательных
величин:
|
Номер региона |
|
|
|
|
|
|
|
|
1 |
2 |
28 |
19,76 |
8,24 |
67,89 |
2,76 |
7,60 |
|
2 |
2,4 |
21,3 |
22,75 |
-1,45 |
2,11 |
-3,94 |
15,55 |
|
3 |
2,1 |
21 |
20,51 |
0,49 |
0,24 |
-4,24 |
18,00 |
|
4 |
2,6 |
23,3 |
24,25 |
-0,95 |
0,90 |
-1,94 |
3,77 |
|
5 |
1,7 |
15,8 |
17,52 |
-1,72 |
2,95 |
-9,44 |
89,17 |
|
6 |
2,5 |
21,9 |
23,50 |
-1,60 |
2,56 |
-3,34 |
11,17 |
|
7 |
2,4 |
20 |
22,75 |
-2,75 |
7,57 |
-5,24 |
27,49 |
|
8 |
2,6 |
22 |
24,25 |
-2,25 |
5,04 |
-3,24 |
10,52 |
|
9 |
2,8 |
23,9 |
25,74 |
-1,84 |
3,39 |
-1,34 |
1,80 |
|
10 |
2,6 |
26 |
24,25 |
1,75 |
3,08 |
0,76 |
0,57 |
|
11 |
2,6 |
24,6 |
24,25 |
0,35 |
0,13 |
-0,64 |
0,41 |
|
12 |
2,5 |
21 |
23,50 |
-2,50 |
6,24 |
-4,24 |
18,00 |
|
13 |
2,9 |
27 |
26,49 |
0,51 |
0,26 |
1,76 |
3,09 |
|
14 |
2,6 |
21 |
24,25 |
-3,25 |
10,54 |
-4,24 |
18,00 |
|
15 |
2,2 |
24 |
21,26 |
2,74 |
7,53 |
-1,24 |
1,54 |
|
16 |
2,6 |
24 |
24,25 |
-0,25 |
0,06 |
-1,24 |
1,54 |
|
17 |
3,3 |
31,9 |
29,48 |
2,42 |
5,86 |
6,66 |
44,32 |
|
18 |
3,9 |
33 |
33,96 |
-0,96 |
0,93 |
7,76 |
60,17 |
|
19 |
4 |
35,4 |
34,71 |
0,69 |
0,47 |
10,16 |
103,17 |
|
20 |
3,7 |
34 |
32,47 |
1,53 |
2,34 |
8,76 |
76,69 |
|
21 |
3,4 |
31 |
30,23 |
0,77 |
0,60 |
5,76 |
33,14 |
|
Сумма |
57,4 |
530,1 |
130,68 |
545,73 |
Здесь
столбец «![]() »
»
– это значения![]() ,
,![]() рассчитанные с помощью построенного
рассчитанные с помощью построенного
уравнения регрессии, столбцы «![]() »
»
и![]() – это столбцы, так называемых, «остатков»:
– это столбцы, так называемых, «остатков»:
разностей между исходными значениями![]() ,
,![]() и рассчитанными с помощью уравнения
и рассчитанными с помощью уравнения
регрессии![]() ,
,
а также их квадратов, а в последних двух
столбцах – разности между исходными
значениями![]() ,
,
выборочным средним![]() ,
,
а также их квадраты.
Для
вычисления коэффициента детерминации
воспользуемся формулой ( ):
![]()
Значение
коэффициента детерминации позволяет
сделать предварительный вывод о том,
что у нас имеются основания использовать
модель линейной регрессии в данной
задаче, поскольку
![]() .
.
Построим
линию регрессии на корреляционном поле,
для чего добавим на координатной
плоскости точки, соответствующие
уравнению регрессии (![]() ).
).

Нанесем
теперь уравнение регрессии на диаграмму,
используя специальные средства Excel.
Для этого необходимо выделить правой
кнопкой мыши исходные точки и выбрать
опцию Добавить
линию тренда.

В
открывшемся меню Параметры
линии тренда
выбрать Линейную
аппроксимацию.
Далее поставить флажок напротив полей
Показывать
уравнение на диаграмме
и Поместить
на диаграмму величину достоверности
аппроксимации ![]() .
.

Нажав
на ОК, получаем еще одну прямую на
диаграмме, которая совпадает с построенными
ранее точками линии регрессии:

Сплошная
черная линия на диаграмме – это линия
регрессии, рассчитанная средствами
Excel.
Линия регрессии, построенная нами ранее,
совпала с данной линией регрессии.
Нетрудно убедиться, что уравнение
регрессии и коэффициент детерминации
тоже совпадают с полученными ранее
вручную.
Найдем
теперь среднюю ошибку аппроксимации
для оценки погрешности модели. Для этого
нам потребуется вычислить еще ряд
промежуточных величин:
|
Номер региона |
|
|
|
|
|
|
1 |
2 |
28 |
19,76 |
8,24 |
0,29 |
|
2 |
2,4 |
21,3 |
22,75 |
-1,45 |
0,07 |
|
3 |
2,1 |
21 |
20,51 |
0,49 |
0,02 |
|
4 |
2,6 |
23,3 |
24,25 |
-0,95 |
0,04 |
|
5 |
1,7 |
15,8 |
17,52 |
-1,72 |
0,11 |
|
6 |
2,5 |
21,9 |
23,50 |
-1,60 |
0,07 |
|
7 |
2,4 |
20 |
22,75 |
-2,75 |
0,14 |
|
8 |
2,6 |
22 |
24,25 |
-2,25 |
0,10 |
|
9 |
2,8 |
23,9 |
25,74 |
-1,84 |
0,08 |
|
10 |
2,6 |
26 |
24,25 |
1,75 |
0,07 |
|
11 |
2,6 |
24,6 |
24,25 |
0,35 |
0,01 |
|
12 |
2,5 |
21 |
23,50 |
-2,50 |
0,12 |
|
13 |
2,9 |
27 |
26,49 |
0,51 |
0,02 |
|
14 |
2,6 |
21 |
24,25 |
-3,25 |
0,15 |
|
15 |
2,2 |
24 |
21,26 |
2,74 |
0,11 |
|
16 |
2,6 |
24 |
24,25 |
-0,25 |
0,01 |
|
17 |
3,3 |
31,9 |
29,48 |
2,42 |
0,08 |
|
18 |
3,9 |
33 |
33,96 |
-0,97 |
0,03 |
|
19 |
4 |
35,4 |
34,71 |
0,69 |
0,02 |
|
20 |
3,7 |
34 |
32,47 |
1,53 |
0,05 |
|
21 |
3,4 |
31 |
30,23 |
0,77 |
0,02 |
Здесь
столбец «![]() »
»
– это значения![]() ,
,![]() рассчитанные с помощью построенного
рассчитанные с помощью построенного
уравнения регрессии, столбец «![]() »
»
– это столбец так называемых «остатков»:
разностей между исходными значениями![]() ,
,
и рассчитанными с помощью уравнения
регрессии![]() ,
,![]() и, наконец, последний столбец «
и, наконец, последний столбец «![]() »
»
– это вспомогательный столбец для
вычисления элементов суммы по формуле
( ). Просуммируем теперь элементы
последнего столбца и разделим полученную
сумму на 21 – общее количество исходных
данных:
![]() .
.
Переведем это
число в проценты и запишем окончательное
выражение для средней ошибки аппроксимации:
![]() .
.
Итак,
средняя ошибка аппроксимации оказалась
около 8%, что говорит о небольшой
погрешности построенной модели. Данную
модель, с учетом неплохих характеристик
ее качества, вполне можно использовать
для прогноза – одной из основных целей
эконометрического анализа. Предположим,
что среднедушевой месячный доход в
одном из регионов составит 4,1 тыс. руб.
Оценим, каков будет уровень продаж
телевизоров в этом регионе согласно
построенной модели? Для этого необходимо
выбранное значение фактора
![]() подставить в уравнение регрессии (
подставить в уравнение регрессии (
):
![]() (тыс.
(тыс.
руб.),
т.е. при таком
уровне дохода, розничная продажа
телевизоров составит, в среднем, 35 480
телевизоров.
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
Пример нахождения статистической значимости коэффициентов регрессии
Числитель в этой формуле может быть рассчитан через коэффициент детерминации и общую дисперсию признака-результата:  .
.
Для параметра a критерий проверки гипотезы о незначимом отличии его от нуля имеет вид:
,
где — оценка параметра регрессии, полученная по наблюдаемым данным;
μa – стандартная ошибка параметра a.
Для линейного парного уравнения регрессии: .
Для проверки гипотезы о незначимом отличии от нуля коэффициента линейной парной корреляции в генеральной совокупности используют следующий критерий: , где ryx — оценка коэффициента корреляции, полученная по наблюдаемым данным; mr – стандартная ошибка коэффициента корреляции ryx.
Для линейного парного уравнения регрессии: .
В парной линейной регрессии между наблюдаемыми значениями критериев существует взаимосвязь: t ( b =0) = t (r=0).
Пример №1 . Уравнение имеет вид y=ax+b
1. Параметры уравнения регрессии.
Средние значения
Связь между признаком Y фактором X сильная и прямая
Уравнение регрессии
Коэффициент детерминации
R 2 = 0.73 2 = 0.54, т.е. в 54% случаев изменения х приводят к изменению y . Другими словами — точность подбора уравнения регрессии — средняя.
| x | y | x 2 | y 2 | x ∙ y | y(x) | (y-y cp ) 2 | (y-y(x)) 2 | (x-x p ) 2 |
| 69 | 124 | 4761 | 15376 | 8556 | 128.48 | 491.36 | 20.11 | 367.36 |
| 83 | 133 | 6889 | 17689 | 11039 | 141.4 | 173.36 | 70.56 | 26.69 |
| 92 | 146 | 8464 | 21316 | 13432 | 149.7 | 0.03 | 13.71 | 14.69 |
| 97 | 153 | 9409 | 23409 | 14841 | 154.32 | 46.69 | 1.73 | 78.03 |
| 88 | 138 | 7744 | 19044 | 12144 | 146.01 | 66.69 | 64.21 | 0.03 |
| 93 | 159 | 8649 | 25281 | 14787 | 150.63 | 164.69 | 70.13 | 23.36 |
| 74 | 145 | 5476 | 21025 | 10730 | 133.1 | 1.36 | 141.68 | 200.69 |
| 79 | 152 | 6241 | 23104 | 12008 | 137.71 | 34.03 | 204.21 | 84.03 |
| 105 | 168 | 11025 | 28224 | 17640 | 161.7 | 476.69 | 39.74 | 283.36 |
| 99 | 154 | 9801 | 23716 | 15246 | 156.16 | 61.36 | 4.67 | 117.36 |
| 85 | 127 | 7225 | 16129 | 10795 | 143.25 | 367.36 | 263.91 | 10.03 |
| 94 | 155 | 8836 | 24025 | 14570 | 151.55 | 78.03 | 11.91 | 34.03 |
| 1058 | 1754 | 94520 | 258338 | 155788 | 1754 | 1961.67 | 906.57 | 1239.67 |
2. Оценка параметров уравнения регрессии
Значимость коэффициента корреляции
По таблице Стьюдента находим Tтабл
Tтабл (n-m-1;a) = (10;0.05) = 1.812
Поскольку Tнабл > Tтабл , то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициента корреляции статистически — значим.
Анализ точности определения оценок коэффициентов регрессии
S a = 0.2704
Доверительные интервалы для зависимой переменной
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X = 88,16
(128.06;163.97)
Проверка гипотез относительно коэффициентов линейного уравнения регрессии
1) t-статистика
Статистическая значимость коэффициента регрессии a подтверждается (3.41>1.812).
Статистическая значимость коэффициента регрессии b подтверждается (2.7>1.812).
Доверительный интервал для коэффициентов уравнения регрессии
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими (tтабл=1.812):
(a — tтабл·S a; a + tтабл·Sa)
(0.4325;1.4126)
(b — tтабл·S b; b + tтабл·Sb)
(21.3389;108.3164)
2) F-статистики
Fkp = 4.96
Поскольку F > Fkp, то коэффициент детерминации статистически значим.
Пример №2 . По территориям региона приводятся данные за 199Х г.;
| Среднедневная заработная плата, руб., у | ||
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Требуется:
1. Построить линейное уравнение парной регрессии у от х.
2. Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации.
3. Оценить статистическую значимость параметров регрессии и корреляции.
4. Выполнить прогноз заработной платы у при прогнозном значении среднедушевого прожиточного минимума х , составляющем 107% от среднего уровня.
5. Оценить точность прогноза, рассчитав ошибку прогноза и его доверительный интервал.
Решение находим с помощью калькулятора.
Использование графического метода .
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
На основании поля корреляции можно выдвинуть гипотезу (для генеральной совокупности) о том, что связь между всеми возможными значениями X и Y носит линейный характер.
Линейное уравнение регрессии имеет вид y = bx + a + ε
Здесь ε — случайная ошибка (отклонение, возмущение).
Причины существования случайной ошибки:
1. Невключение в регрессионную модель значимых объясняющих переменных;
2. Агрегирование переменных. Например, функция суммарного потребления – это попытка общего выражения совокупности решений отдельных индивидов о расходах. Это лишь аппроксимация отдельных соотношений, которые имеют разные параметры.
3. Неправильное описание структуры модели;
4. Неправильная функциональная спецификация;
5. Ошибки измерения.
Так как отклонения εi для каждого конкретного наблюдения i – случайны и их значения в выборке неизвестны, то:
1) по наблюдениям xi и yi можно получить только оценки параметров α и β
2) Оценками параметров α и β регрессионной модели являются соответственно величины а и b, которые носят случайный характер, т.к. соответствуют случайной выборке;
Тогда оценочное уравнение регрессии (построенное по выборочным данным) будет иметь вид y = bx + a + ε, где ei – наблюдаемые значения (оценки) ошибок εi, а и b соответственно оценки параметров α и β регрессионной модели, которые следует найти.
Для оценки параметров α и β — используют МНК (метод наименьших квадратов).
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
12a+1027b=1869
1027a+89907b=161808
Из первого уравнения выражаем а и подставим во второе уравнение. Получаем b = 0.92, a = 76.98
Уравнение регрессии: y = 0.92 x + 76.98 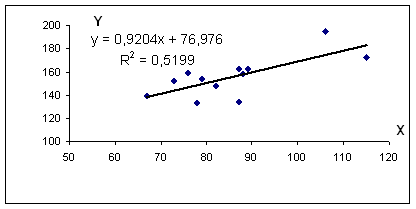
1. Параметры уравнения регрессии.
Выборочные средние.
Коэффициент корреляции
Рассчитываем показатель тесноты связи. Таким показателем является выборочный линейный коэффициент корреляции, который рассчитывается по формуле:
Линейный коэффициент корреляции принимает значения от –1 до +1.
Связи между признаками могут быть слабыми и сильными (тесными). Их критерии оцениваются по шкале Чеддока:
0.1 0 – прямая связь, иначе — обратная). В нашем примере связь прямая.
Коэффициент эластичности.
Коэффициенты регрессии (в примере b) нежелательно использовать для непосредственной оценки влияния факторов на результативный признак в том случае, если существует различие единиц измерения результативного показателя у и факторного признака х.
Для этих целей вычисляются коэффициенты эластичности и бета — коэффициенты. Коэффициент эластичности находится по формуле:
Он показывает, на сколько процентов в среднем изменяется результативный признак у при изменении факторного признака х на 1%. Он не учитывает степень колеблемости факторов.
Коэффициент эластичности меньше 1. Следовательно, при изменении среднедушевого прожиточного минимума в день на 1%, среднедневная заработная плата изменится менее чем на 1%. Другими словами — влияние среднедушевого прожиточного минимума Х на среднедневную заработную плату Y не существенно.
Бета – коэффициент показывает, на какую часть величины своего среднего квадратичного отклонения изменится в среднем значение результативного признака при изменении факторного признака на величину его среднеквадратического отклонения при фиксированном на постоянном уровне значении остальных независимых переменных:
Т.е. увеличение x на величину среднеквадратического отклонения этого показателя приведет к увеличению средней среднедневной заработной платы Y на 0.721 среднеквадратичного отклонения этого показателя.
1.4. Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Поскольку ошибка меньше 15%, то данное уравнение можно использовать в качестве регрессии.
Коэффициент детерминации.
Квадрат (множественного) коэффициента корреляции называется коэффициентом детерминации, который показывает долю вариации результативного признака, объясненную вариацией факторного признака.
Чаще всего, давая интерпретацию коэффициента детерминации, его выражают в процентах.
R 2 = 0.72 2 = 0.5199, т.е. в 51.99 % случаев изменения среднедушевого прожиточного минимума х приводят к изменению среднедневной заработной платы y. Другими словами — точность подбора уравнения регрессии — средняя. Остальные 48.01% изменения среднедневной заработной платы Y объясняются факторами, не учтенными в модели.
| y 2 | x·y | y(x) | (y i — y ) 2 | (y-y(x)) 2 | (x i — x ) 2 | |y-y x |:y | |||
| 78 | 133 | 6084 | 17689 | 10374 | 148,77 | 517,56 | 248,7 | 57,51 | 0,1186 |
| 82 | 148 | 6724 | 21904 | 12136 | 152,45 | 60,06 | 19,82 | 12,84 | 0,0301 |
| 87 | 134 | 7569 | 17956 | 11658 | 157,05 | 473,06 | 531,48 | 2,01 | 0,172 |
| 79 | 154 | 6241 | 23716 | 12166 | 149,69 | 3,06 | 18,57 | 43,34 | 0,028 |
| 89 | 162 | 7921 | 26244 | 14418 | 158,89 | 39,06 | 9,64 | 11,67 | 0,0192 |
| 106 | 195 | 11236 | 38025 | 20670 | 174,54 | 1540,56 | 418,52 | 416,84 | 0,1049 |
| 67 | 139 | 4489 | 19321 | 9313 | 138,65 | 280,56 | 0,1258 | 345,34 | 0,0026 |
| 88 | 158 | 7744 | 24964 | 13904 | 157,97 | 5,06 | 0,0007 | 5,84 | 0,0002 |
| 73 | 152 | 5329 | 23104 | 11096 | 144,17 | 14,06 | 61,34 | 158,34 | 0,0515 |
| 87 | 162 | 7569 | 26244 | 14094 | 157,05 | 39,06 | 24,46 | 2,01 | 0,0305 |
| 76 | 159 | 5776 | 25281 | 12084 | 146,93 | 10,56 | 145,7 | 91,84 | 0,0759 |
| 115 | 173 | 13225 | 29929 | 19895 | 182,83 | 297,56 | 96,55 | 865,34 | 0,0568 |
| 1027 | 1869 | 89907 | 294377 | 161808 | 1869 | 3280,25 | 1574,92 | 2012,92 | 0,6902 |
2. Оценка параметров уравнения регрессии.
2.1. Значимость коэффициента корреляции.
По таблице Стьюдента с уровнем значимости α=0.05 и степенями свободы k=10 находим tкрит:
tкрит = (10;0.05) = 1.812
где m = 1 — количество объясняющих переменных.
Если tнабл > tкритич, то полученное значение коэффициента корреляции признается значимым (нулевая гипотеза, утверждающая равенство нулю коэффициента корреляции, отвергается).
Поскольку tнабл > tкрит, то отклоняем гипотезу о равенстве 0 коэффициента корреляции. Другими словами, коэффициент корреляции статистически — значим.
В парной линейной регрессии t 2 r = t 2 b и тогда проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
2.3. Анализ точности определения оценок коэффициентов регрессии.
Несмещенной оценкой дисперсии возмущений является величина:
S 2 y = 157.4922 — необъясненная дисперсия (мера разброса зависимой переменной вокруг линии регрессии).
12.5496 — стандартная ошибка оценки (стандартная ошибка регрессии).
S a — стандартное отклонение случайной величины a.
Sb — стандартное отклонение случайной величины b.
2.4. Доверительные интервалы для зависимой переменной.
Экономическое прогнозирование на основе построенной модели предполагает, что сохраняются ранее существовавшие взаимосвязи переменных и на период упреждения.
Для прогнозирования зависимой переменной результативного признака необходимо знать прогнозные значения всех входящих в модель факторов.
Прогнозные значения факторов подставляют в модель и получают точечные прогнозные оценки изучаемого показателя.
(a + bxp ± ε)
где
Рассчитаем границы интервала, в котором будет сосредоточено 95% возможных значений Y при неограниченно большом числе наблюдений и X p = 94
(76.98 + 0.92*94 ± 7.8288)
(155.67;171.33)
С вероятностью 95% можно гарантировать, что значения Y при неограниченно большом числе наблюдений не выйдет за пределы найденных интервалов.
2.5. Проверка гипотез относительно коэффициентов линейного уравнения регрессии.
1) t-статистика. Критерий Стьюдента.
Проверим гипотезу H0 о равенстве отдельных коэффициентов регрессии нулю (при альтернативе H1 не равно) на уровне значимости α=0.05.
tкрит = (10;0.05) = 1.812
Поскольку 3.2906 > 1.812, то статистическая значимость коэффициента регрессии b подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Поскольку 3.1793 > 1.812, то статистическая значимость коэффициента регрессии a подтверждается (отвергаем гипотезу о равенстве нулю этого коэффициента).
Доверительный интервал для коэффициентов уравнения регрессии.
Определим доверительные интервалы коэффициентов регрессии, которые с надежность 95% будут следующими:
(b — tкрит Sb; b + tкрит Sb)
(0.9204 — 1.812·0.2797; 0.9204 + 1.812·0.2797)
(0.4136;1.4273)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
(a-ta)
(76.9765 — 1.812·24.2116; 76.9765 + 1.812·24.2116)
(33.1051;120.8478)
С вероятностью 95% можно утверждать, что значение данного параметра будут лежать в найденном интервале.
2) F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=10, Fkp = 4.96
Поскольку фактическое значение F > Fkp, то коэффициент детерминации статистически значим (Найденная оценка уравнения регрессии статистически надежна).
Проверка на статистическую значимость коэффициентов уравнения регрессии и корреляции.
Качество подбора функции регрессии можно оценить с помощью стандартных ошибок или оценок параметров регрессии. Для оценки статистической значимости коэффициентов регрессии и корреляции рассчитывается t-критерий Стьюдента и доверительные интервалы каждого из показателей. Выдвигается гипотеза Н0 о случайной природе показателей, т.е. о незначимом их отличии от нуля. Оценка значимости коэффициентов регрессии и корреляции с помощью t-критерия Стьюдента проводится путем сопоставления их значений с величиной стандартного отклонения, т.е.:
Стандартные ошибки параметров линейной регрессии и коэффициента корреляции определяются по формулам:
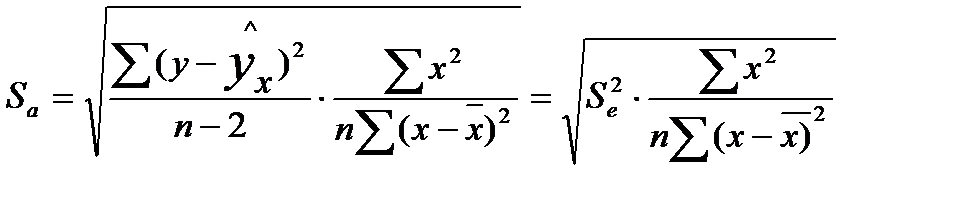

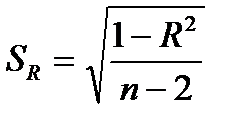
где 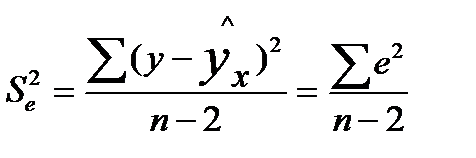 — мера разброса зависимой переменной вокруг линии регрессии (необъясненная дисперсия) или
— мера разброса зависимой переменной вокруг линии регрессии (необъясненная дисперсия) или 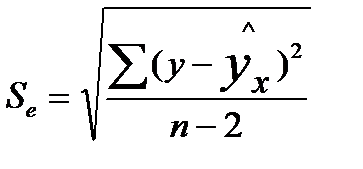 — стандартная ошибка регрессии.
— стандартная ошибка регрессии.
Сравнивая фактическое (расчетное) и критическое (табличное) значения t-статистики, т.е. tфакт и tкрит = t n-1;α — отвергаем или не отвергаем гипотезу Н0:
—если tкрит tфакт,то Н0 не отклоняется и признается случайная природа формирования a, b и R..
Фактическое значение t-критерия Стьюдента определяется как
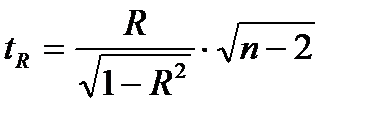
Данная формула свидетельствует, что в парной регрессии 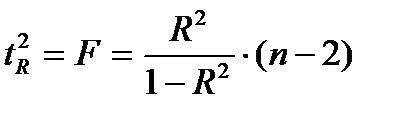 . Кроме того
. Кроме того 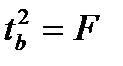 . Следовательно,
. Следовательно, 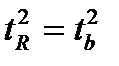
Таким образом, проверка гипотез о значимости коэффициентов регрессии и корреляции равносильна проверке гипотезы о существенности линейного уравнения регрессии.
Формулы для расчета доверительных интервалов a, b имеют следующий вид:
Если в границы доверительного интервала попадает ноль, т.е. нижняя граница отрицательна, а верхняя положительна, то оцениваемый параметр принимается нулевым, т.к. он не может одновременно принимать и положительное, и отрицательное значения.
8.Проверка общего качества уравнения регрессии. Для оценки качества построенной модели используют коэффициент (индекс) детерминации — R 2 , а также среднюю ошибку аппроксимации — А.
F-тест — оценивание качества уравнения регрессии – состоит в проверке гипотезы H0 о статистической не значимости уравнения регрессии и показателя тесноты связи. Для этого выполняется сравнение фактического Fфакт и критического (табличного) Fтабл значений F-критерия Фишера. Fтабл определяется из соотношения значения объясненной и остаточной дисперсии, рассчитанных на одну степень свободы:

где n — объем выборки (объем статистической информации).
Fтабл – это максимально возможное значение критерия под влиянием случайных факторов при данных степенях свободы и уровне значимости a. Уровень значимости a — вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно a принимается равной 0,05 или 0,01.
Если Fтабл Fфакт, то гипотеза H0 не отклоняется и признаётся статистическая незначимость, ненадёжность уравнения регрессии.
9.Интервалы прогноза по линейному уравнению регрессии.В прогнозных расчетах по уравнению регрессии определяется предсказываемое (расчетное) упрог значение как точечный прогноз  при хпрог=хк, т.е. путем подстановки в уравнение регрессии
при хпрог=хк, т.е. путем подстановки в уравнение регрессии 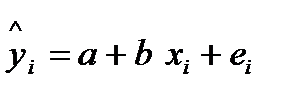 соответствующего прогнозного значения xпрог. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки и соответственно интервальной оценкой прогнозного значения gпрогноз. Фактические значения у варьируют около среднего значения . Индивидуальные значения у могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается какостаточная дисперсии на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку
соответствующего прогнозного значения xпрог. Однако точечный прогноз явно не реален. Поэтому он дополняется расчетом стандартной ошибки и соответственно интервальной оценкой прогнозного значения gпрогноз. Фактические значения у варьируют около среднего значения . Индивидуальные значения у могут отклоняться от на величину случайной ошибки e, дисперсия которой оценивается какостаточная дисперсии на одну степень свободы S 2 . Поэтому ошибка предсказываемого индивидуального значения у должна включать не только стандартную ошибку
S , но и случайную ошибку Se.
Средняя стандартная ошибка прогноза Sпрогноз вычисляется по формуле:
 ,
,
а доверительный интервал прогноза строится по формуле:
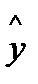 прогноз — tкрит Sпрогноз ≤ gпрогноз ≤
прогноз — tкрит Sпрогноз ≤ gпрогноз ≤  прогноз + tкрит Sпрогноз
прогноз + tкрит Sпрогноз
При прогнозировании на основе уравнения регрессии следует помнить, что величина прогноза зависит не только от стандартной ошибки индивидуального значения у, но и от точности прогноза значения фактора х. Его величина может задаваться на основе анализа других моделей исходя из конкретной ситуации, а также из анализа динамики данного фактора.
10.Таблица дисперсионного анализа. Задача дисперсионного анализа состоит в анализе дисперсии зависимой переменной:å  = å (
= å (  ) 2 + å (
) 2 + å (  ) 2 ,
) 2 ,
где 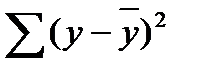 — общая сумма квадратов отклонений;
— общая сумма квадратов отклонений;
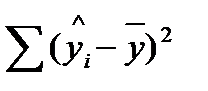 — сумма квадратов отклонений, обусловленная регрессией («объясненная», «факторная»);
— сумма квадратов отклонений, обусловленная регрессией («объясненная», «факторная»);
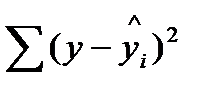 — остаточная сумма квадратов отклонений (“необъясненная”).
— остаточная сумма квадратов отклонений (“необъясненная”).
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Дисперсия на одну степень свободы |
| Общая | |
n-1 | — |
| Факторная | |
m | 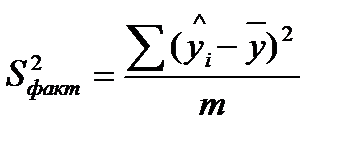 |
| Остаточная | 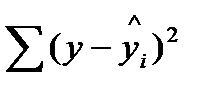 |
n-m-1 |  |
Нелинейная регрессия
Нелинейная регрессия -частный случай регрессионного анализа, в котором рассматриваемая регрессионная модель есть функция, зависящая от параметров и от одной или нескольких свободных переменных. Во многих практических случаях моделирование экономических зависимостей линейными уравнениями дает вполне удовлетворительный результат и может использоваться для анализа и прогнозирования. Однако в силу однообразия и сложности экономических процессов ограничиться рассмотрением лишь линейных регрессионных моделей невозможно. Многие экономические зависимости не являются линейными по своей сути, и поэтому их моделирование линейными уравнениями регрессии, безусловно, не даст положительного результата. Например, при рассмотрении спроса Y на некоторый товар от цены X данного товара в ряде случаев можно ограничиться линейным уравнением регрессии: Y=β0+β1X . Здесь β1 характеризует абсолютное изменение Y (в среднем) при единичном изменении X. Если же мы хотим проанализировать эластичность спроса по цене, то приведенное уравнение не позволит это осуществить. В этом случае целесообразно рассмотреть так называемую логарифмическую модель
При анализе издержек Y от объема выпуска X наиболее обоснованной является полиноминальная (точнее, кубическая) модель При рассмотрении производственных функций линейная модель является нереалистичной. В этом случае обычно используются степенные модели. Например, широкую известность имеет производственная функция Кобба-Дугласа Y=AK α L β (здесь Y – объем выпуска; K и L – затраты капитала и труда соответственно; A, α и β – параметры модели).
Достаточно широко применяются в современном эконометрическом анализе и многие другие модели, в частности обратная и экспоненциальная модели.
Построение и анализ нелинейных моделей имеют свою специфику. Приведенные выше примеры и рассуждения дают основания более детально рассмотреть возможные нелинейные модели.
Оценка существенности нелинейной регрессии
Если нелинейное по факторным переменным уравнение регрессии с помощью метода замен можно свести к парному линейному уравнению регрессии, то на это уравнение будут распространяться все методы проверки гипотез для парной линейной зависимости.
Проверка гипотезы о значимости нелинейной регрессионной модели в целом осуществляется через F-критерий. Выдвигается основная гипотеза Но о незначимости коэффициента детерминации для нелинейных форм связи, т.е. о незначимости полученного уравнения регрессии:
Альтернативной является обратная гипотеза Н1 о значимости построенного уравнения регрессии:
Наблюдаемое значение F-критерия вычисляется по формуле
где п — объем выборочной совокупности; l — число оцениваемых параметров по выборочной совокупности.
Критическое значение рассматриваемого критерия Fкрит вычисляется по таблице распределения Фишера в зависимости от уровня значимости α и числа степеней свободы k1 = l-1 и k2 = п-l. Если наблюдаемое значение F-критерия больше критического Fнабл > Fкрит , то основная гипотеза отклоняется, следовательно уравнение нелинейной регрессии является значимым. Если наблюдаемое значение F-критерия меньше критического (Fнабл 2 и индекса детерминации для нелинейных форм связи R 2 .
Выдвигается основная гипотеза Но о линейной зависимости между переменными. Альтернативной является гипотеза о их нелинейной связи. Проверка этих гипотез осуществляется с помощью t-критерия Стьюдента. Наблюдаемое значение t-критерия
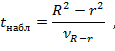
где  — величина ошибки разности (R 2 — r 2 ), вычисляемая по формуле
— величина ошибки разности (R 2 — r 2 ), вычисляемая по формуле
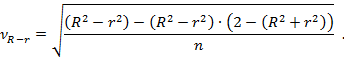
Критическое значение рассматриваемого критерия tкрит определяется по таблице распределения Стьюдента в зависимости от уровня значимости α и числа степеней свободы (п – l – 1), где l — число оцениваемых параметров βi в регрессионной модели. Если наблюдаемое значение t-критерия больше критического (tнабл > tкрит ), то основная гипотеза отклоняется и между изучаемыми переменными существует нелинейная взаимосвязь. Если наблюдаемое значение t-критерия меньше критического (tнабл
Дата добавления: 2015-10-05 ; просмотров: 1268 ; ЗАКАЗАТЬ НАПИСАНИЕ РАБОТЫ
http://poisk-ru.ru/s51764t1.html
http://helpiks.org/5-52727.html
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов
|
Остаточная сумма квадратов
|



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Для того чтобы модель линейной регрессии можно было применять на практике необходимо сначала оценить её качество. Для этих целей предложен ряд показателей, каждый из которых предназначен для использования в различных ситуациях и имеет свои особенности применения (линейные и нелинейные, устойчивые к аномалиям, абсолютные и относительные, и т.д.). Корректный выбор меры для оценки качества модели является одним из важных факторов успеха в решении задач анализа данных.
«Хорошая» аналитическая модель должна удовлетворять двум, зачастую противоречивым, требованиям — как можно лучше соответствовать данным и при этом быть удобной для интерпретации пользователем. Действительно, повышение соответствия модели данным как правило связано с её усложнением (в случае регрессии — увеличением числа входных переменных модели). А чем сложнее модель, тем ниже её интерпретируемость.
Поэтому при выборе между простой и сложной моделью последняя должна значимо увеличивать соответствие модели данным чтобы оправдать рост сложности и соответствующее снижение интерпретируемости. Если это условие не выполняется, то следует выбрать более простую модель.
Таким образом, чтобы оценить, насколько повышение сложности модели значимо увеличивает её точность, необходимо использовать аппарат оценки качества регрессионных моделей. Он включает в себя следующие меры:
- Среднеквадратичная ошибка (MSE).
- Корень из среднеквадратичной ошибки (RMSE).
- Среднеквадратичная ошибка в процентах (MSPE).
- Средняя абсолютная ошибка (MAE).
- Средняя абсолютная ошибка в процентах (MAPE).
- Cимметричная средняя абсолютная процентная ошибка (SMAPE).
- Средняя абсолютная масштабированная ошибка (MASE)
- Средняя относительная ошибка (MRE).
- Среднеквадратичная логарифмическая ошибка (RMSLE).
- Коэффициент детерминации R-квадрат.
- Скорректированный коэффициент детеминации.
Прежде чем перейти к изучению метрик качества, введём некоторые базовые понятия, которые нам в этом помогут. Для этого рассмотрим рисунок.
Рисунок 1. Линейная регрессия
Наклонная прямая представляет собой линию регрессии с переменной, на которой расположены точки, соответствующие предсказанным значениям выходной переменной widehat{y} (кружки синего цвета). Оранжевые кружки представляют фактические (наблюдаемые) значения y . Расстояния между ними и линией регрессии — это ошибка предсказания модели y-widehat{y} (невязка, остатки). Именно с её использованием вычисляются все приведённые в статье меры качества.
Горизонтальная линия представляет собой модель простого среднего, где коэффициент при независимой переменной x равен нулю, и остаётся только свободный член b, который становится равным среднему арифметическому фактических значений выходной переменной, т.е. b=overline{y}. Очевидно, что такая модель для любого значения входной переменной будет выдавать одно и то же значение выходной — overline{y}.
В линейной регрессии такая модель рассматривается как «бесполезная», хуже которой работает только «случайный угадыватель». Однако, она используется для оценки, насколько дисперсия фактических значений y относительно линии среднего, больше, чем относительно линии регрессии с переменной, т.е. насколько модель с переменной лучше «бесполезной».
MSE
Среднеквадратичная ошибка (Mean Squared Error) применяется в случаях, когда требуется подчеркнуть большие ошибки и выбрать модель, которая дает меньше именно больших ошибок. Большие значения ошибок становятся заметнее за счет квадратичной зависимости.
Действительно, допустим модель допустила на двух примерах ошибки 5 и 10. В абсолютном выражении они отличаются в два раза, но если их возвести в квадрат, получив 25 и 100 соответственно, то отличие будет уже в четыре раза. Таким образом модель, которая обеспечивает меньшее значение MSE допускает меньше именно больших ошибок.
MSE рассчитывается по формуле:
MSE=frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y}_{i})^{2},
где n — количество наблюдений по которым строится модель и количество прогнозов, y_{i} — фактические значение зависимой переменной для i-го наблюдения, widehat{y}_{i} — значение зависимой переменной, предсказанное моделью.
Таким образом, можно сделать вывод, что MSE настроена на отражение влияния именно больших ошибок на качество модели.
Недостатком использования MSE является то, что если на одном или нескольких неудачных примерах, возможно, содержащих аномальные значения будет допущена значительная ошибка, то возведение в квадрат приведёт к ложному выводу, что вся модель работает плохо. С другой стороны, если модель даст небольшие ошибки на большом числе примеров, то может возникнуть обратный эффект — недооценка слабости модели.
RMSE
Корень из среднеквадратичной ошибки (Root Mean Squared Error) вычисляется просто как квадратный корень из MSE:
RMSE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(y_{i}-widehat{y_{i}})^{2}}
MSE и RMSE могут минимизироваться с помощью одного и того же функционала, поскольку квадратный корень является неубывающей функцией. Например, если у нас есть два набора результатов работы модели, A и B, и MSE для A больше, чем MSE для B, то мы можем быть уверены, что RMSE для A больше RMSE для B. Справедливо и обратное: если MSE(A)<MSE(B), то и RMSE(A)<RMSE(B).
Следовательно, сравнение моделей с помощью RMSE даст такой же результат, что и для MSE. Однако с MSE работать несколько проще, поэтому она более популярна у аналитиков. Кроме этого, имеется небольшая разница между этими двумя ошибками при оптимизации с использованием градиента:
frac{partial RMSE}{partial widehat{y}_{i}}=frac{1}{2sqrt{MSE}}frac{partial MSE}{partial widehat{y}_{i}}
Это означает, что перемещение по градиенту MSE эквивалентно перемещению по градиенту RMSE, но с другой скоростью, и скорость зависит от самой оценки MSE. Таким образом, хотя RMSE и MSE близки с точки зрения оценки моделей, они не являются взаимозаменяемыми при использовании градиента для оптимизации.
Влияние каждой ошибки на RMSE пропорционально величине квадрата ошибки. Поэтому большие ошибки оказывают непропорционально большое влияние на RMSE. Следовательно, RMSE можно считать чувствительной к аномальным значениям.
MSPE
Среднеквадратичная ошибка в процентах (Mean Squared Percentage Error) представляет собой относительную ошибку, где разность между наблюдаемым и фактическим значениями делится на наблюдаемое значение и выражается в процентах:
MSPE=frac{100}{n}sumlimits_{i=1}^{n}left ( frac{y_{i}-widehat{y}_{i}}{y_{i}} right )^{2}
Проблемой при использовании MSPE является то, что, если наблюдаемое значение выходной переменной равно 0, значение ошибки становится неопределённым.
MSPE можно рассматривать как взвешенную версию MSE, где вес обратно пропорционален квадрату наблюдаемого значения. Таким образом, при возрастании наблюдаемых значений ошибка имеет тенденцию уменьшаться.
MAE
Cредняя абсолютная ошибка (Mean Absolute Error) вычисляется следующим образом:
MAE=frac{1}{n}sumlimits_{i=1}^{n}left | y_{i}-widehat{y}_{i} right |
Т.е. MAE рассчитывается как среднее абсолютных разностей между наблюдаемым и предсказанным значениями. В отличие от MSE и RMSE она является линейной оценкой, а это значит, что все ошибки в среднем взвешены одинаково. Например, разница между 0 и 10 будет вдвое больше разницы между 0 и 5. Для MSE и RMSE, как отмечено выше, это не так.
Поэтому MAE широко используется, например, в финансовой сфере, где ошибка в 10 долларов должна интерпретироваться как в два раза худшая, чем ошибка в 5 долларов.
MAPE
Средняя абсолютная процентная ошибка (Mean Absolute Percentage Error) вычисляется следующим образом:
MAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{left | y_{i} right |}
Эта ошибка не имеет размерности и очень проста в интерпретации. Её можно выражать как в долях, так и в процентах. Если получилось, например, что MAPE=11.4, то это говорит о том, что ошибка составила 11.4% от фактического значения.
SMAPE
Cимметричная средняя абсолютная процентная ошибка (Symmetric Mean Absolute Percentage Error) — это мера точности, основанная на процентных (или относительных) ошибках. Обычно определяется следующим образом:
SMAPE=frac{100}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y_{i}} right |}{(left | y_{i} right |+left | widehat{y}_{i} right |)/2}
Т.е. абсолютная разность между наблюдаемым и предсказанным значениями делится на полусумму их модулей. В отличие от обычной MAPE, симметричная имеет ограничение на диапазон значений. В приведённой формуле он составляет от 0 до 200%. Однако, поскольку диапазон от 0 до 100% гораздо удобнее интерпретировать, часто используют формулу, где отсутствует деление знаменателя на 2.
Одной из возможных проблем SMAPE является неполная симметрия, поскольку в разных диапазонах ошибка вычисляется неодинаково. Это иллюстрируется следующим примером: если y_{i}=100 и widehat{y}_{i}=110, то SMAPE=4.76, а если y_{i}=100 и widehat{y}_{i}=90, то SMAPE=5.26.
Ограничение SMAPE заключается в том, что, если наблюдаемое или предсказанное значение равно 0, ошибка резко возрастет до верхнего предела (200% или 100%).
MASE
Средняя абсолютная масштабированная ошибка (Mean absolute scaled error) — это показатель, который позволяет сравнивать две модели. Если поместить MAE для новой модели в числитель, а MAE для исходной модели в знаменатель, то полученное отношение и будет равно MASE. Если значение MASE меньше 1, то новая модель работает лучше, если MASE равно 1, то модели работают одинаково, а если значение MASE больше 1, то исходная модель работает лучше, чем новая модель. Формула для расчета MASE имеет вид:
MASE=frac{MAE_{i}}{MAE_{j}}
MASE симметрична и устойчива к выбросам.
MRE
Средняя относительная ошибка (Mean Relative Error) вычисляется по формуле:
MRE=frac{1}{n}sumlimits_{i=1}^{n}frac{left | y_{i}-widehat{y}_{i}right |}{left | y_{i} right |}
Несложно увидеть, что данная мера показывает величину абсолютной ошибки относительно фактического значения выходной переменной (поэтому иногда эту ошибку называют также средней относительной абсолютной ошибкой, MRAE). Действительно, если значение абсолютной ошибки, скажем, равно 10, то сложно сказать много это или мало. Например, относительно значения выходной переменной, равного 20, это составляет 50%, что достаточно много. Однако относительно значения выходной переменной, равного 100, это будет уже 10%, что является вполне нормальным результатом.
Очевидно, что при вычислении MRE нельзя применять наблюдения, в которых y_{i}=0.
Таким образом, MRE позволяет более адекватно оценить величину ошибки, чем абсолютные ошибки. Кроме этого она является безразмерной величиной, что упрощает интерпретацию.
RMSLE
Среднеквадратичная логарифмическая ошибка (Root Mean Squared Logarithmic Error) представляет собой RMSE, вычисленную в логарифмическом масштабе:
RMSLE=sqrt{frac{1}{n}sumlimits_{i=1}^{n}(log(widehat{y}_{i}+1)-log{(y_{i}+1}))^{2}}
Константы, равные 1, добавляемые в скобках, необходимы чтобы не допустить обращения в 0 выражения под логарифмом, поскольку логарифм нуля не существует.
Известно, что логарифмирование приводит к сжатию исходного диапазона изменения значений переменной. Поэтому применение RMSLE целесообразно, если предсказанное и фактическое значения выходной переменной различаются на порядок и больше.
R-квадрат
Перечисленные выше ошибки не так просто интерпретировать. Действительно, просто зная значение средней абсолютной ошибки, скажем, равное 10, мы сразу не можем сказать хорошая это ошибка или плохая, и что нужно сделать чтобы улучшить модель.
В этой связи представляет интерес использование для оценки качества регрессионной модели не значения ошибок, а величину показывающую, насколько данная модель работает лучше, чем модель, в которой присутствует только константа, а входные переменные отсутствуют или коэффициенты регрессии при них равны нулю.
Именно такой мерой и является коэффициент детерминации (Coefficient of determination), который показывает долю дисперсии зависимой переменной, объяснённой с помощью регрессионной модели. Наиболее общей формулой для вычисления коэффициента детерминации является следующая:
R^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}}
Практически, в числителе данного выражения стоит среднеквадратическая ошибка оцениваемой модели, а в знаменателе — модели, в которой присутствует только константа.
Главным преимуществом коэффициента детерминации перед мерами, основанными на ошибках, является его инвариантность к масштабу данных. Кроме того, он всегда изменяется в диапазоне от −∞ до 1. При этом значения близкие к 1 указывают на высокую степень соответствия модели данным. Очевидно, что это имеет место, когда отношение в формуле стремится к 0, т.е. ошибка модели с переменными намного меньше ошибки модели с константой. R^{2}=0 показывает, что между независимой и зависимой переменными модели имеет место функциональная зависимость.
Когда значение коэффициента близко к 0 (т.е. ошибка модели с переменными примерно равна ошибке модели только с константой), это указывает на низкое соответствие модели данным, когда модель с переменными работает не лучше модели с константой.
Кроме этого, бывают ситуации, когда коэффициент R^{2} принимает отрицательные значения (обычно небольшие). Это произойдёт, если ошибка модели среднего становится меньше ошибки модели с переменной. В этом случае оказывается, что добавление в модель с константой некоторой переменной только ухудшает её (т.е. регрессионная модель с переменной работает хуже, чем предсказание с помощью простой средней).
На практике используют следующую шкалу оценок. Модель, для которой R^{2}>0.5, является удовлетворительной. Если R^{2}>0.8, то модель рассматривается как очень хорошая. Значения, меньшие 0.5 говорят о том, что модель плохая.
Скорректированный R-квадрат
Основной проблемой при использовании коэффициента детерминации является то, что он увеличивается (или, по крайней мере, не уменьшается) при добавлении в модель новых переменных, даже если эти переменные никак не связаны с зависимой переменной.
В связи с этим возникают две проблемы. Первая заключается в том, что не все переменные, добавляемые в модель, могут значимо увеличивать её точность, но при этом всегда увеличивают её сложность. Вторая проблема — с помощью коэффициента детерминации нельзя сравнивать модели с разным числом переменных. Чтобы преодолеть эти проблемы используют альтернативные показатели, одним из которых является скорректированный коэффициент детерминации (Adjasted coefficient of determinftion).
Скорректированный коэффициент детерминации даёт возможность сравнивать модели с разным числом переменных так, чтобы их число не влияло на статистику R^{2}, и накладывает штраф за дополнительно включённые в модель переменные. Вычисляется по формуле:
R_{adj}^{2}=1-frac{sumlimits_{i=1}^{n}(widehat{y}_{i}-y_{i})^{2}/(n-k)}{sumlimits_{i=1}^{n}({overline{y}}_{i}-y_{i})^{2}/(n-1)}
где n — число наблюдений, на основе которых строится модель, k — количество переменных в модели.
Скорректированный коэффициент детерминации всегда меньше единицы, но теоретически может принимать значения и меньше нуля только при очень малом значении обычного коэффициента детерминации и большом количестве переменных модели.
Сравнение метрик
Резюмируем преимущества и недостатки каждой приведённой метрики в следующей таблице:
| Мера | Сильные стороны | Слабые стороны |
|---|---|---|
| MSE | Позволяет подчеркнуть большие отклонения, простота вычисления. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. Сложность интерпретации из-за квадратичной зависимости. |
| RMSE | Простота интерпретации, поскольку измеряется в тех же единицах, что и целевая переменная. | Имеет тенденцию занижать качество модели, чувствительна к выбросам. |
| MSPE | Нечувствительна к выбросам. Хорошо интерпретируема, поскольку имеет линейный характер. | Поскольку вклад всех ошибок отдельных наблюдений взвешивается одинаково, не позволяет подчёркивать большие и малые ошибки. |
| MAPE | Является безразмерной величиной, поэтому её интерпретация не зависит от предметной области. | Нельзя использовать для наблюдений, в которых значения выходной переменной равны нулю. |
| SMAPE | Позволяет корректно работать с предсказанными значениями независимо от того больше они фактического, или меньше. | Приближение к нулю фактического или предсказанного значения приводит к резкому росту ошибки, поскольку в знаменателе присутствует как фактическое, так и предсказанное значения. |
| MASE | Не зависит от масштаба данных, является симметричной: положительные и отрицательные отклонения от фактического значения учитываются одинаково. Устойчива к выбросам. Позволяет сравнивать модели. | Сложность интерпретации. |
| MRE | Позволяет оценить величину ошибки относительно значения целевой переменной. | Неприменима для наблюдений с нулевым значением выходной переменной. |
| RMSLE | Логарифмирование позволяет сделать величину ошибки более устойчивой, когда разность между фактическим и предсказанным значениями различается на порядок и выше | Может быть затруднена интерпретация из-за нелинейности. |
| R-квадрат | Универсальность, простота интерпретации. | Возрастает даже при включении в модель бесполезных переменных. Плохо работает когда входные переменные зависимы. |
| R-квадрат скорр. | Корректно отражает вклад каждой переменной в модель. | Плохо работает, когда входные переменные зависимы. |
В данной статье рассмотрены наиболее популярные меры качества регрессионных моделей, которые часто используются в различных аналитических приложениях. Эти меры имеют свои особенности применения, знание которых позволит обоснованно выбирать и корректно применять их на практике.
Однако в литературе можно встретить и другие меры качества моделей регрессии, которые предлагаются различными авторами для решения конкретных задач анализа данных.
Другие материалы по теме:
Отбор переменных в моделях линейной регрессии
Репрезентативность выборочных данных
Логистическая регрессия и ROC-анализ — математический аппарат