
Для
оценки точности полученной модели будем
использовать показатель относительной
ошибки аппроксимации, который вычисляется
по формуле:
![]() ,
,
где
![]()
Расчет
относительной ошибки аппроксимации
Таблица
4.4
|
t |
Y |
Предсказанное |
|
|
|
|
1 |
5 |
4,58 |
0,42 |
0,08 |
|
|
2 |
7 |
7,21 |
-0,21 |
0,03 |
|
|
3 |
10 |
9,84 |
0,16 |
0,02 |
|
|
4 |
12 |
12,48 |
-0,48 |
0,04 |
|
|
5 |
15 |
15,11 |
-0,11 |
0,01 |
|
|
6 |
18 |
17,74 |
0,26 |
0,01 |
|
|
7 |
20 |
20,38 |
-0,38 |
0,02 |
|
|
8 |
23 |
23,01 |
-0,01 |
0,00 |
|
|
9 |
26 |
25,64 |
0,36 |
0,01 |
|
|
Сумма |
45 |
136 |
0,00 |
0,23 |
|
|
Среднее |
5 |
15,11 |
![]()
Если
ошибка, вычисленная по формуле, не
превосходит 15%, точность модели считается
приемлемой.
5)
По построенной модели
осуществить прогноз спроса на следующие
две недели (доверительный интервал
прогноза рассчитать при доверительной
вероятности р = 70%).
![]()
![]()
Воспользуемся
функцией Excel
СТЬЮДРАСПОБР. (рис. 4.10)
t
= 1,12
Рис.
4.6

Для
построения интервального прогноза
рассчитаем доверительный интервал.
Примем значение уровня значимости
![]() ,
,
следовательно, доверительная вероятность
равна 70 %, а критерий Стьюдента при![]() равен 1,12.
равен 1,12.
Ширину
доверительного интервала вычислим по
формуле:
 ,
,
где

![]()
![]()
![]() (находим
(находим
из таблицы 4.1)
![]() ,
,
![]() .
.
Вычисляем
верхнюю и нижнюю границы прогноза (таб.
4.11).
Таблица
4.5
Таблица
прогноза
-
n
+kU
(k)Прогноз
Формула
Верхняя
границаНижняя
граница10
U(1)
=0.8428.24
Прогноз
+ U(1)29.сен
27.40
11
U(2)
=1.0230.87
Прогноз
— U(2)31.89
29.85
6) Фактические значения показателя, результаты моделирования и прогнозирования представить графически.
Преобразуем
график подбора (рис. 4.5), дополнив его
данными прогноза.
Рис.
4.7

Соседние файлы в предмете Методы оптимизации
- #
- #
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
Для этого:
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу <F2>, а затем на комбинацию клавиш <Ctrl>+<Shift>+<Enter>.
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов
|
Остаточная сумма квадратов
|



Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Оценка точности модели кривой роста, выбор наилучшей кривой роста
Точность модели характеризуется разностью между фактическими и расчетными значениями исследуемого показателя Y. Мерой точности является стандартная ошибка модели
.
Точность модели удобнее оценивать с помощью средней относительной ошибки аппроксимации
,
которая показывает, на сколько процентов в среднем модельные значения отличаются от фактических yt. Если
, то считается, что модель имеет достаточно высокую точность, при
точность модели хорошая, при
— удовлетворительная, а при
— неудовлетворительная.
Если одновременно исследуются несколько моделей, то лучшей считается модель, имеющая наименьшую Sмод или Еотн.
Продолжение примера 9. Проверить точность модели.
Решение. Стандартная ошибка линейной модели может быть определена с помощью функции Excel «СТОШYX»: млн. руб.
Средняя относительная ошибка аппроксимации
%.
Предсказанные моделью значения спроса на кредитные ресурсы отличаются от фактических в среднем на 4,54 млн руб., или на 6,5 %. Модель имеет хорошую точность.
18 Янв Ошибка прогнозирования: как рассчитать и применять.
Posted at 11:37h
in Статьи
Основной задачей при управлении запасами является определение объема пополнения, то есть, сколько необходимо заказать поставщику. При расчете этого объема используется несколько параметров — сколько будет продано в будущем, за какое время происходит пополнение, какие остатки у нас на складе и какое количество уже заказано у поставщика. То, насколько правильно мы определим эти параметры, будет влиять на то, будет ли достаточно товара на складе или его будет слишком много. Но наибольшее влияние на эффективность управления запасами влияет то, насколько точен будет прогноз. Многие считают, что это вообще основной вопрос в управлении запасами. Действительно, точность прогнозирования очень важный параметр. Поэтому важно понимать, как его оценивать. Это важно и для выявления причин дефицитов или неликвидов, и при выборе программных продуктов для прогнозирования продаж и управления запасами.
В данной статье я представила несколько формул для расчета точности прогноза и ошибки прогнозирования. Кроме этого, вы сможете скачать файлы с примерами расчетов этого показателя.
Статистические методы
Для оценки прогноза продаж используются статистические оценки Оценка ошибки прогнозирования временного ряда. Самый простой показатель – отклонение факта от прогноза в количественном выражении.
В практике рассчитывают ошибку прогнозирования по каждой отдельной позиции, а также рассчитывают среднюю ошибку прогнозирования. Следующие распространенные показатели ошибки относятся именно к показателям средних ошибок прогнозирования.
К ним относятся:
MAPE – средняя абсолютная ошибка в процентах

где Z(t) – фактическое значение временного ряда, а  – прогнозное.
– прогнозное.
Данная оценка применяется для временных рядов, фактические значения которых значительно больше 1. Например, оценки ошибки прогнозирования энергопотребления почти во всех статьях приводятся как значения MAPE.
Если же фактические значения временного ряда близки к 0, то в знаменателе окажется очень маленькое число, что сделает значение MAPE близким к бесконечности – это не совсем корректно. Например, фактическая цена РСВ = 0.01 руб/МВт.ч, a прогнозная = 10 руб/МВт.ч, тогда MAPE = (0.01 – 10)/0.01 = 999%, хотя в действительности мы не так уж сильно ошиблись, всего на 10 руб/МВт.ч. Для рядов, содержащих значения близкие к нулю, применяют следующую оценку ошибки прогноза.
MAE – средняя абсолютная ошибка
 .
.
Для оценки ошибки прогнозирования цен РСВ и индикатора БР корректнее использовать MAE.
После того, как получены значения для MAPE и/или MAE, то в работах обычно пишут: «Прогнозирование временного ряда энергопотребления с часовым разрешение проводилось на интервале с 01.01.2001 до 31.12.2001 (общее количество отсчетов N ~ 8500). Для данного прогноза значение MAPE = 1.5%». При этом, просматривая статьи, можно сложить общее впечатление об ошибки прогнозирования энергопотребления, для которого MAPE обычно колеблется от 1 до 5%; или ошибки прогнозирования цен на электроэнергию, для которого MAPE колеблется от 5 до 15% в зависимости от периода и рынка. Получив значение MAPE для собственного прогноза, вы можете оценить, насколько здорово у вас получается прогнозировать.
Кроме указанных методов иногда используют другие оценки ошибки, менее популярные, но также применимые. Подробнее об этих оценках ошибки прогноза читайте указанные статьи в Википедии.
ME – средняя ошибка

Встречается еще другое название этого показателя — Bias (англ. – смещение) демонстрирует величину отклонения, а также — в какую сторону прогноз продаж отклоняется от фактической потребности. Этот индикатор показывает, был ли прогноз оптимистичным или пессимистичным. То есть, отрицательное значение Bias говорит о том, что прогноз был завышен (реальная потребность оказалась ниже), и, наоборот, положительное значение о том, что прогноз был занижен. Цифровое значение показателя определяет величину отклонения (смещения).
MSE – среднеквадратичная ошибка
 .
.
RMSE – квадратный корень из среднеквадратичной ошибки
 .
.
.
SD – стандартное отклонение
 где ME – есть средняя ошибка, определенная по формуле выше.
где ME – есть средняя ошибка, определенная по формуле выше.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже.
Связь точности и ошибки прогнозирования
В начале этого обсуждения разберемся с определениями.
Ошибка прогноза — апостериорная величина отклонения прогноза от действительного состояния объекта. Если говорить о прогнозе продаж, то это показатель отклонения фактических продаж от прогноза.
Точность прогнозирования есть понятие прямо противоположное ошибке прогнозирования. Если ошибка прогнозирования велика, то точность мала и наоборот, если ошибка прогнозирования мала, то точность велика. По сути дела оценка ошибки прогноза MAPE есть обратная величина для точности прогнозирования — зависимость здесь простая.
Точность прогноза в % = 100% – MAPE, встречается еще название этого показателя Forecast Accuracy. Вы практически не найдете материалов о прогнозировании, в которых приведены оценки именно точности прогноза, хотя с точки зрения здравого маркетинга корректней говорить именно о высокой точности. В рекламных статьях всегда будет написано о высокой точности. Показатель точности прогноза выражается в процентах:
- Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно. Нужно сразу оговориться, что такого показателя никогда не будет, основное свойство прогноза в том, что он всегда ошибочен.
- Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда. Говоря о высокой точности, мы говорим о низкой ошибки прогноза и в этой области недопонимания быть не должно. Не имеет значения, что именно вы будете отслеживать, но важно, чтобы вы сравнивали модели прогнозирования или целевые показатели по одному показателю – ошибка прогноза или точность прогнозирования.
Ранее я использовала оценку MAPE, до тех пор пока не встретила формулу, которую рекомендует Валерий Разгуляев.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже.
Оценка ошибки прогноза – формула Валерия Разгуляева (сайт http://upravlenie-zapasami.ru/)
Одной из самых используемых формул оценки ошибки прогнозирования является следующая формула:


где: P – это прогноз, а S – факт за тот же месяц. Однако у этой формулы есть серьезное ограничение — как оценить ошибку, если факт равен нулю? Возможный ответ, что в таком случае D = 100% – который означает, что мы полностью ошиблись. Однако простой пример показывает, что такой ответ — не верен:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
300% |
|
№3 |
1 |
4 |
75% |
Оказывается, что в варианте развития событий №2, когда мы лучше угадали спрос, чем в варианте №1, ошибка по данной формуле оказалась – больше. То есть ошиблась уже сама формула. Есть и другая проблема, если мы посмотрим на варианты №2 и №3, то увидим, что имеем дело с зеркальной ситуацией в прогнозе и факте, а ошибка при этом отличается – в разы!.. То есть при такой оценке ошибки прогноза нам лучше его заведомо делать менее точным, занижая показатель – тогда ошибка будет меньше!.. Хотя понятно, что чем точнее будет прогноз – тем лучше будет и закупка. Поэтому для расчёта ошибки Валерий Разгуляев рекомендует использовать следующую формулу:


В таком случае для тех же примеров ошибка рассчитается иначе:
|
вариант |
прогноз |
факт |
ошибка прогноза |
|
№1 |
4 |
0 |
100% |
|
№2 |
4 |
1 |
75% |
|
№3 |
1 |
4 |
75% |
Как мы видим, в варианте №1 ошибка становится равной 100%, причём это уже – не наше предположение, а чистый расчёт, который можно доверить машине. Зеркальные же варианты №2 и №3 – имеют и одинаковую ошибку, причём эта ошибка меньше ошибки самого плохого варианта №1. Единственная ситуация, когда данная формула не сможет дать однозначный ответ – это равенство знаменателя нулю. Но максимум из прогноза и факта равен нулю, только когда они оба равны нулю. В таком случае получается, что мы спрогнозировали отсутствие спроса, и его, действительно, не было – то есть ошибка тоже равна нулю – мы сделали совершенно точное предсказание.
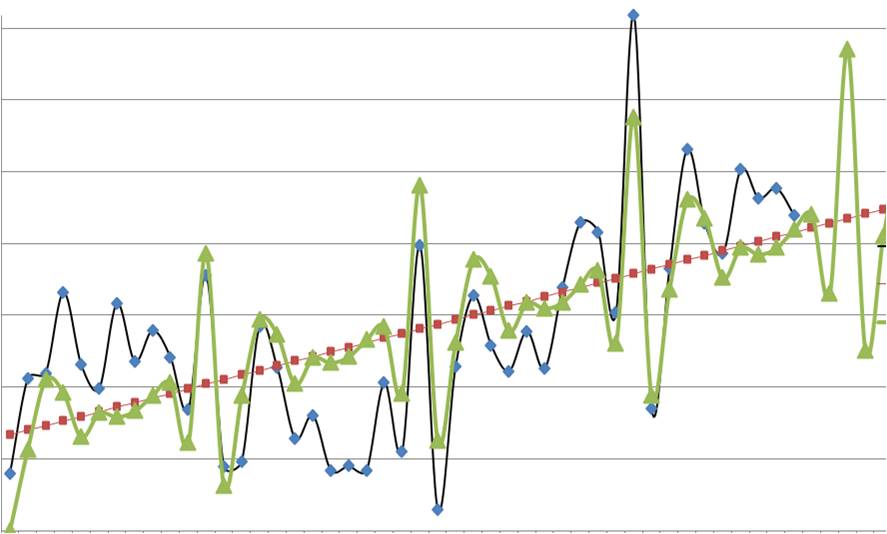
Визуальный метод – графический
Визуальный метод состоит в том, что мы на график выводим значение прогнозной модели и факта продаж по тем моделям, которые хотим сравнить. Далее сравниваем визуально, насколько прогнозная модель близка к фактическим продажам. Давайте рассмотрим на примере. В таблице представлены две прогнозные модели, а также фактические продажи по этому товару за тот же период. Для наглядности мы также рассчитали ошибку прогнозирования по обеим моделям.

По графикам очевидно, что модель 2 описывает лучше продажи этого товара. Оценка ошибки прогнозирования тоже это показывает – 65% и 31% ошибка прогнозирования по модели 1 и модели 2 соответственно.


Недостатком данного метода является то, что небольшую разницу между моделями сложно выявить — разницу в несколько процентов сложно оценить по диаграмме. Однако эти несколько процентов могут существенно улучшить качество прогнозирования и планирования пополнения запасов в целом.
Использование формул ошибки прогнозирования на практике
Практический аспект оценки ошибки прогнозирования я вывела отдельным пунктом. Это связано с тем, что все статистические методы расчета показателя ошибки прогнозирования рассчитывают то, насколько мы ошиблись в прогнозе в количественных показателях. Давайте теперь обсудим, насколько такой показатель будет полезен в вопросах управления запасами. Дело в том, что основная цель управления запасами — обеспечить продажи, спрос наших клиентов. И, в конечном счете, максимизировать доход и прибыль компании. А эти показатели оцениваются как раз в стоимостном выражении. Таким образом, нам важно при оценке ошибки прогнозирования понимать какой вклад каждая позиция внесла в объем продаж в стоимостном выражении. Когда мы оцениваем ошибку прогнозирования в количественном выражении мы предполагаем, что каждый товар имеет одинаковый вес в общем объеме продаж, но на самом деле это не так – есть очень дорогие товары, есть товары, которые продаются в большом количестве, наша группа А, а есть не очень дорогие товары, есть товары которые вносят небольшой вклад в объем продаж. Другими словами большая ошибка прогнозирования по товарам группы А будет нам «стоить» дороже, чем низкая ошибка прогнозирования по товарам группы С, например. Для того, чтобы наша оценка ошибки прогнозирования была корректной, релевантной целям управления запасами, нам необходимо оценивать ошибку прогнозирования по всем товарам или по отдельной группе не по средними показателями, а средневзвешенными с учетом прогноза и факта в стоимостном выражении.
Пример расчета такой оценки Вы сможете увидеть в файле Excel.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже.
При этом нужно помнить, что для оценки ошибки прогнозирования по отдельным позициям мы рассчитываем по количеству, но вот если нам важно понять в целом ошибку прогнозирования по компании, например, для оценки модели, которую используем, то нам нужно рассчитывать не среднюю оценку по всем товарам, а средневзвешенную с учетом стоимостной оценки. Оценку можно брать по ценам себестоимости или ценам продажи, это не играет большой роли, главное, эти же цены (тип цен) использовать при всех расчетах.
Для чего используется ошибка прогнозирования
В первую очередь, оценка ошибки прогнозирования нам необходима для оценки того, насколько мы ошибаемся при планировании продаж, а значит при планировании поставок товаров. Если мы все время прогнозируем продажи значительно больше, чем потом фактически продаем, то вероятнее всего у нас будет излишки товаров, и это невыгодно компании. В случае, когда мы ошибаемся в обратную сторону – прогнозируем продажи меньше чем фактические продажи, с большой вероятностью у нас будут дефициты и компания не дополучит прибыль. В этом случае ошибка прогнозирования служит индикатором качества планирования и качества управления запасами.
Индикатором того, что повышение эффективности возможно за счет улучшения качества прогнозирования. За счет чего можно улучшить качество прогнозирования мы не будем здесь рассматривать, но одним из вариантов является поиск другой модели прогнозирования, изменения параметров расчета, но вот насколько новая модель будет лучше, как раз поможет показатель ошибки прогнозирования или точности прогноза. Сравнение этих показателей по нескольким моделям поможет определить ту модель, которая дает лучше результат.
В идеальном случае, мы можем так подбирать модель для каждой отдельной позиции. В этом случае мы будем рассчитывать прогноз по разным товарам по разным моделям, по тем, которые дают наилучший вариант именно для конкретного товара.
Также этот показатель можно использовать при выборе автоматизированного инструмента для прогнозирования спроса и управления запасами. Вы можете сделать тестовые расчеты прогноза в предлагаемой программе и сравнить ошибку прогнозирования полученного прогноза с той, которая есть у вашей существующей модели. Если у предлагаемого инструмента ошибка прогнозирования меньше. Значит, этот инструмент можно рассматривать для применения в компании. Кроме этого, показатель точности прогноза или ошибки прогнозирования можно использовать как KPI сотрудников, которые отвечают за подготовку прогноза продаж или менеджеров по закупкам, в том случае, если они рассчитывают прогноз будущих продаж при расчете заказа.
Примечание. Примеры расчетов данных показателей представлены в файле Excel, который можно скачать, оставив электронный адрес в форме ниже.
Если вы хотите повысить эффективность управления запасами и увеличить оборачиваемость товарных запасов, предлагаю изучить мастер-класс «Как увеличить оборачиваемость товарных запасов».
Копирование статьи возможно только вместе с этим текстом, с обязательным указанием автора, и ссылки на первоисточник: https://uppravuk.net/
 Существует множество моделей прогноза, но как выбрать среди них ту, которая наиболее точно сделает прогноз?
Существует множество моделей прогноза, но как выбрать среди них ту, которая наиболее точно сделает прогноз?
Из данной статьи вы узнаете:
- Какие способы оценки прогноза вы можете использовать?
- Как выбрать оптимальную модель, которая поможет вам сделать максимально точный прогноз?
- Как рассчитать показатель «Точность прогноза»?
Какие способы оценки прогнозной модели вы можете использовать:
1. Оценить отношение фактических продаж к прогнозу;
2. Расчет показателя точность прогноза — оценка на сколько точно выбранная модель описывает анализируемые данные;
3. Графический анализ — строим график и визуально оцениваем адекватность модели прогноза относительно фактических продаж за последний период ;
1-й способ — Расчет отношения фактических продаж к прогнозу.
Сначала рассчитываем прогноз разными способами и оцениваем отношение фактических продаж к прогнозу. ВАЖНО протестировать модели не по одному товару или направлению продаж, а сразу взять 10 и более товарных позиций или направлений продаж и рассчитать прогноз по ним на минимум на 3 периода вперед (количество периодов и направления прогноза зависят от ваших задач. Если задача — сделать точный прогноз на 6 месяцев, то рассчитываем прогноз на 6 месяцев несколькими вариантами и оцениваем отношение факта к прогнозу по сумме полугода).
Рассчитаем прогноз 4 способами на полгода. Протестируем следующие модели:
-
Линейный тренд + сезонность — лист «Линейный» в приложенном файле (см. статью «Как рассчитать прогноз с учетом роста и сезонности в Excel»)
-
Логарифмический тренд + сезонность — лист «Логарифмический» в приложенном файле (см. статью «5 способов расчета значений логарифмического тренда»)
-
Скользящая средняя с сезонностью к 2-м месяцам — лист «Скользящая к 2-м» (см. статью «Как рассчитать прогноз по методу скользящей средней»);
-
Скользящяя средняя с сезонностью к 3-м месяцам — лист «Скользящая к 3-м»;
Для каждой из 4-х прогнозных моделей в листе «Оценка моделей»:
-
Суммируем прогноз по каждой модели за 6 месяцев;
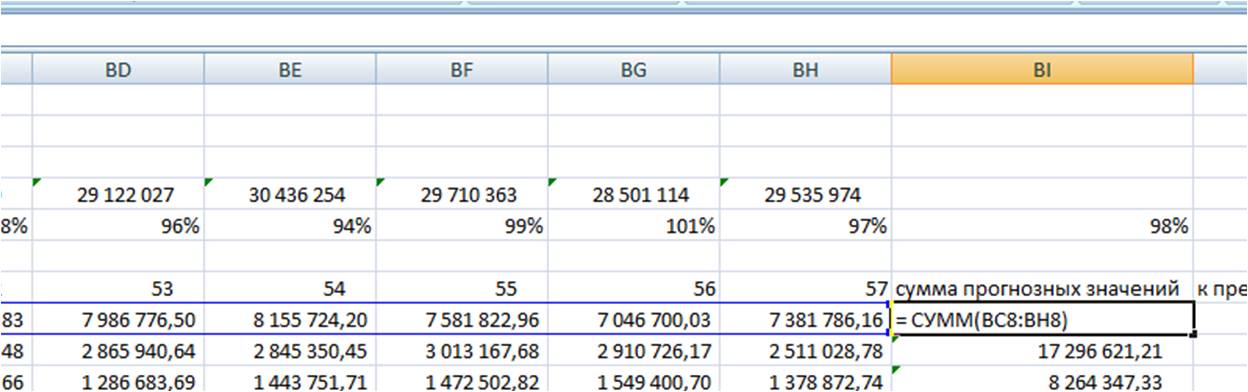
-
Суммируем фактические продажи, которые мы будем сравнивать с прогнозом;
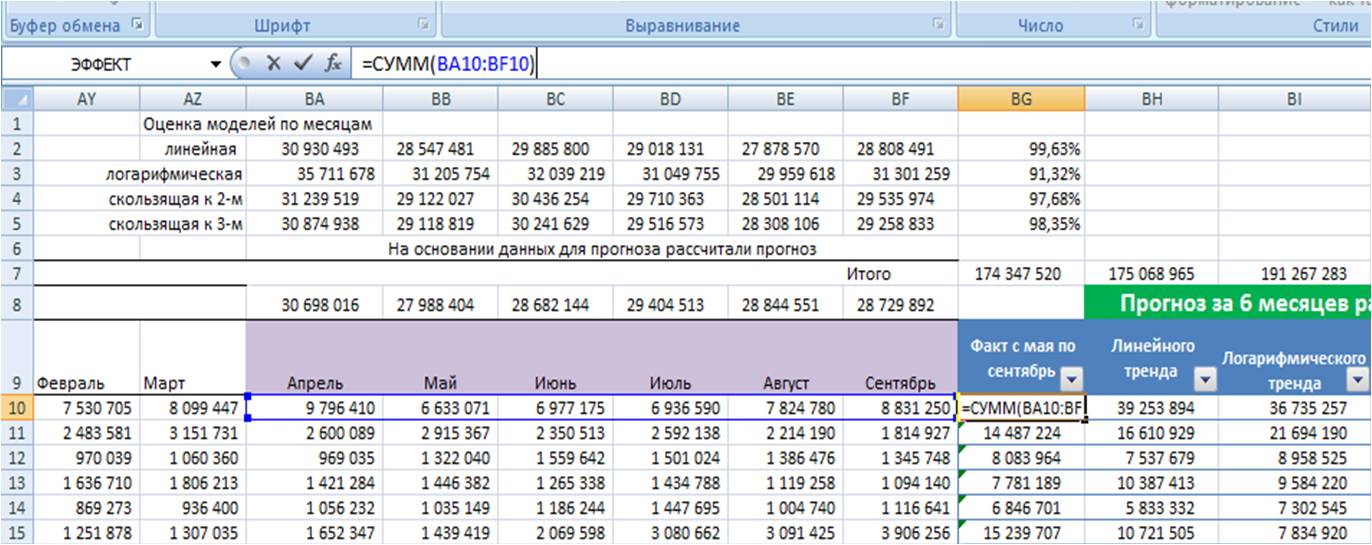
-
Рассчитываем отношение факта к прогнозу по каждой позиции для каждой модели;
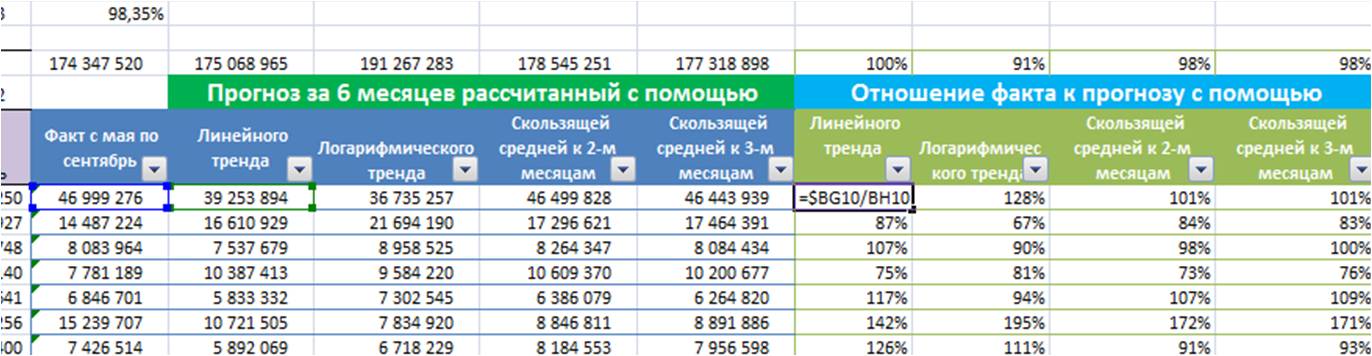
-
Рассчитываем по каждой модели среднее отношение факта к прогнозу;
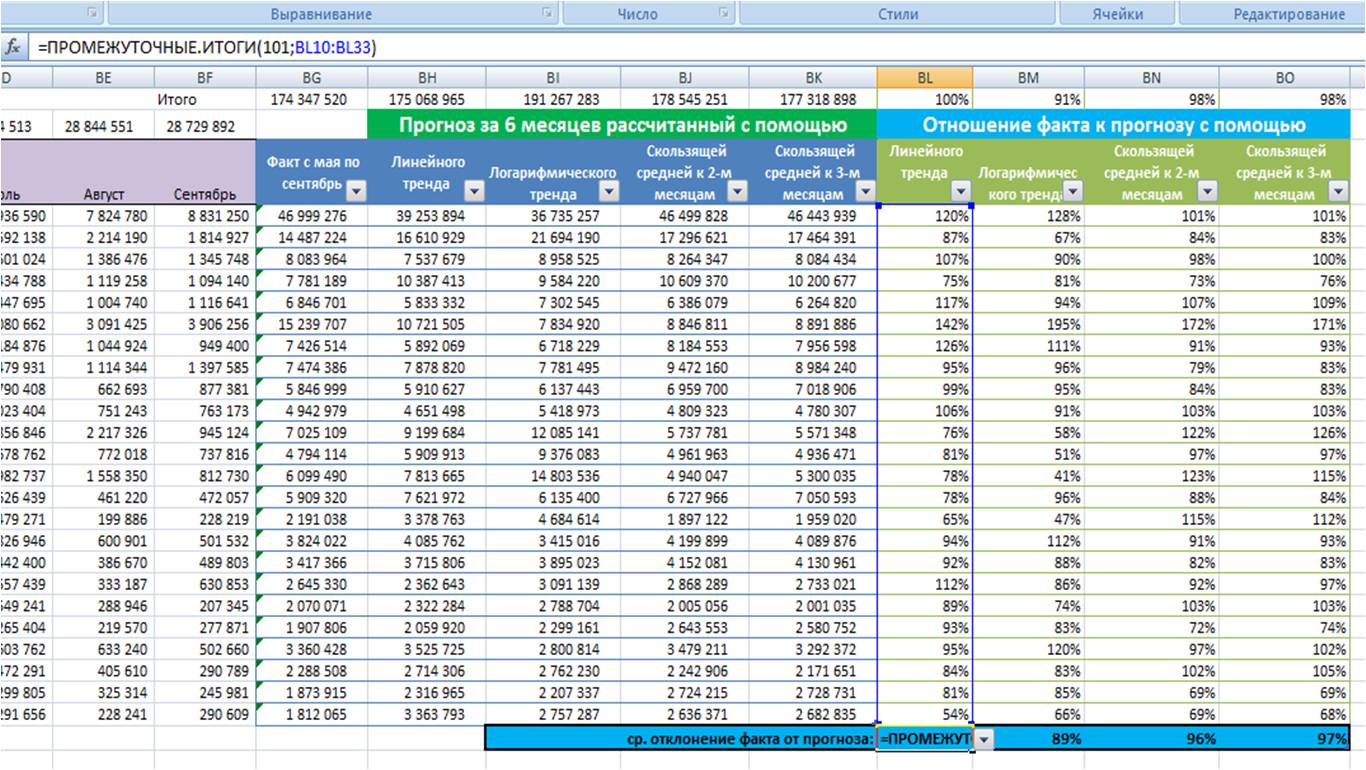
-
Выбираем модель прогноза, которая по показателю «среднее отношение факта к прогнозу» оказалась максимально приближена к 100%;
Для наших данных самой точной моделью оказалась скользящая средняя к 3-м месяцам с сезонностью, среднее отклонение факта от прогноза 97%.
Мы протестировали каждую модель прогноза на реальных данных и выбрали для себя оптимальную, которая в среднем показала минимальное отклонение от факлических продаж.
2-й способ оценки модели прогноза — расчет показателя точность прогноза.
Показатель точность прогноза показывает, на сколько точно выбранная модель прогноза описывает данные. Идея в том, чем точнее выбранная модель описывает фактические данные, тем точнее она сделает прогноз.
Как рассчитать точность прогноза? Рассмотрим на примере расчета для модели прогноза с линейным трендом и сезонностью.
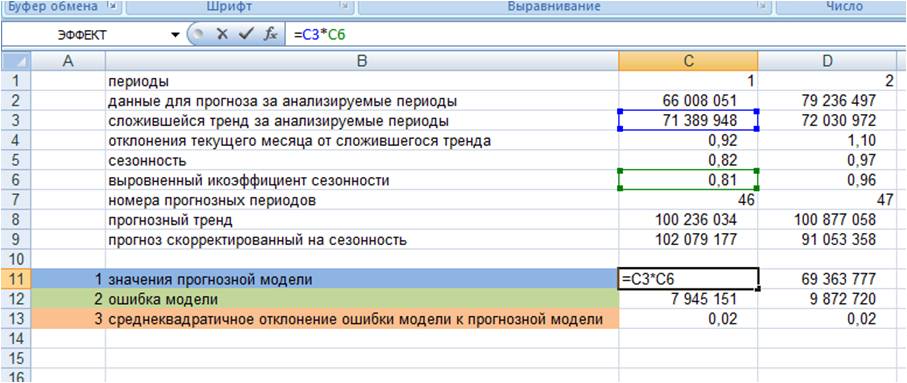
1. Рассчитываем значения прогнозной модели для каждого анализируемого момента времени в прошлом.
Для этого значения тренда для анализируемых периодов умножаем на выровненные коэффициенты сезонности (см. файл с примером)
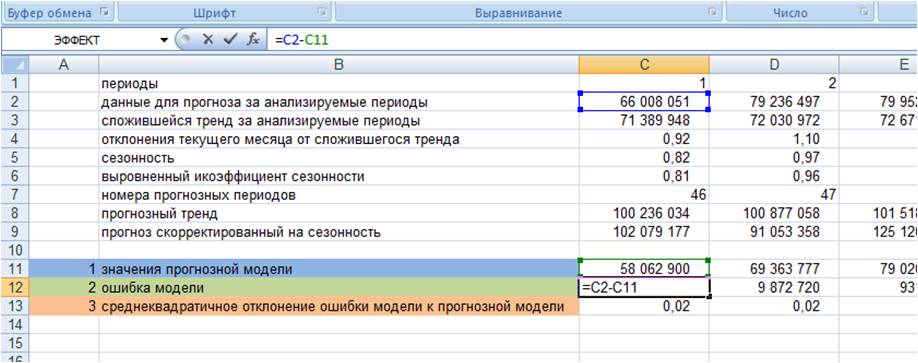
2. Рассчитываем ошибку прогнозной модели. Для этого за каждый период от фактических значений вычитаем значения прогнозной модели.
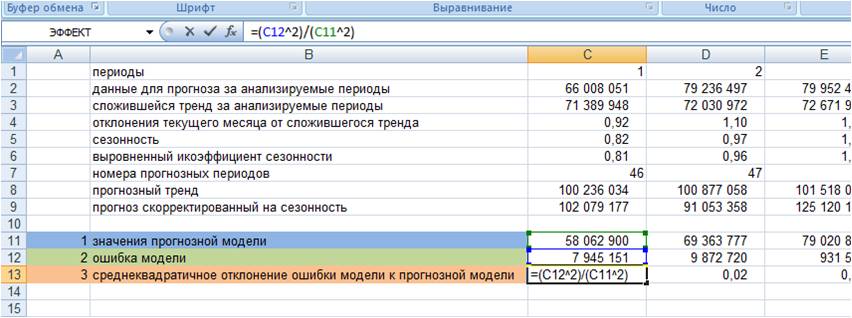
3. Рассчитываем квадратическое отклонение ошибки от значений прогнозной модели (см. файл с примером);
4. Рассчитываем среднее значение квадратического отклонения, т.е. среднеквадратическое отклонение
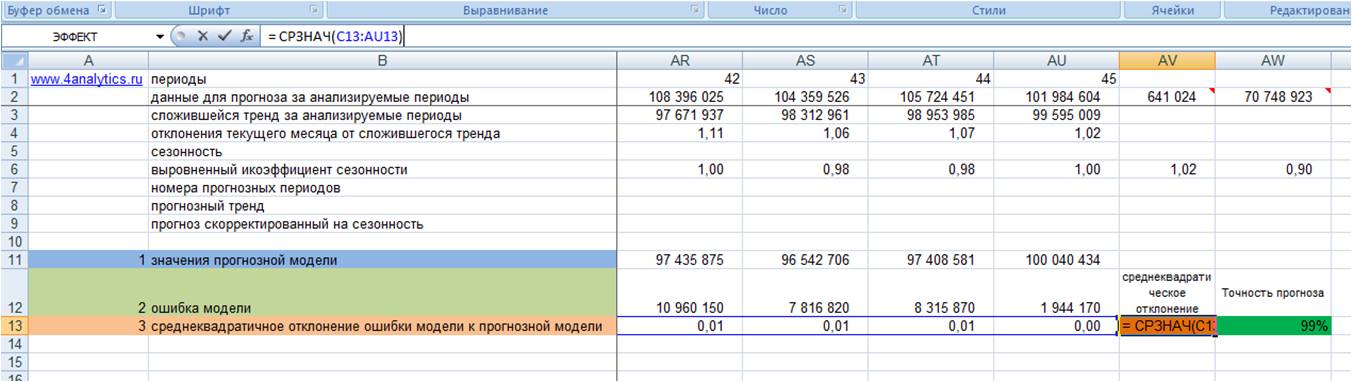
5. Точность прогноза = (1- среднеквадратическое отклонение ошибки прогнозной модели)*100 (см. файл с примером).
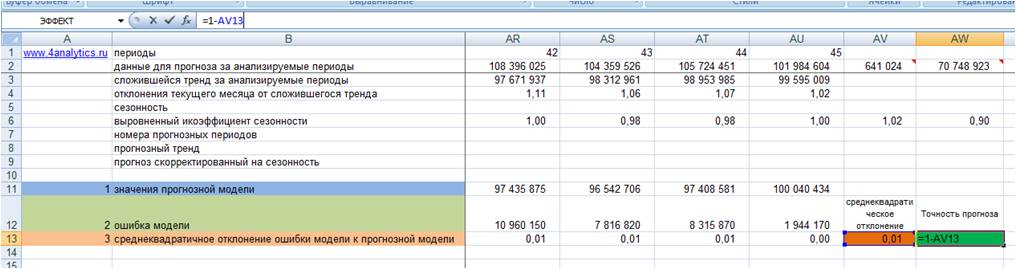
Показатель точности прогноза выражается в процентах:
-
Если точность прогноза равна 100%, то выбранная модель описывает фактические значения на 100%, т.е. очень точно.
-
Если 0% или отрицательное число, то совсем не описывает, и данной модели доверять не стоит.
Выбрать подходящую модель прогноза можно с помощью расчета показателя точность прогноза. Модель прогноза, у которой показатель точность прогноза будет ближе к 100%, с большей вероятностью сделает более точный прогноз. Такую модель можно назвать оптимальной для выбранного временного ряда.
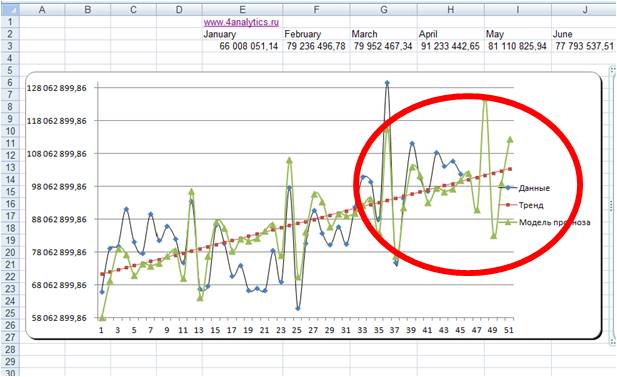
3. Способ оценки прогнозной модели — визуальный.
На график выводим анализируемые данные, тренд, значение модели и прогноз (см. вложенный файл). Обычно визуально видно, какая модель адекватнее строит прогноз . 3-й способ по своей сути схож с 1-м и вторым, только мы верим не цифрам, а тому что мы видим на графике.
Линейная модель:
Логарифмическая модель:
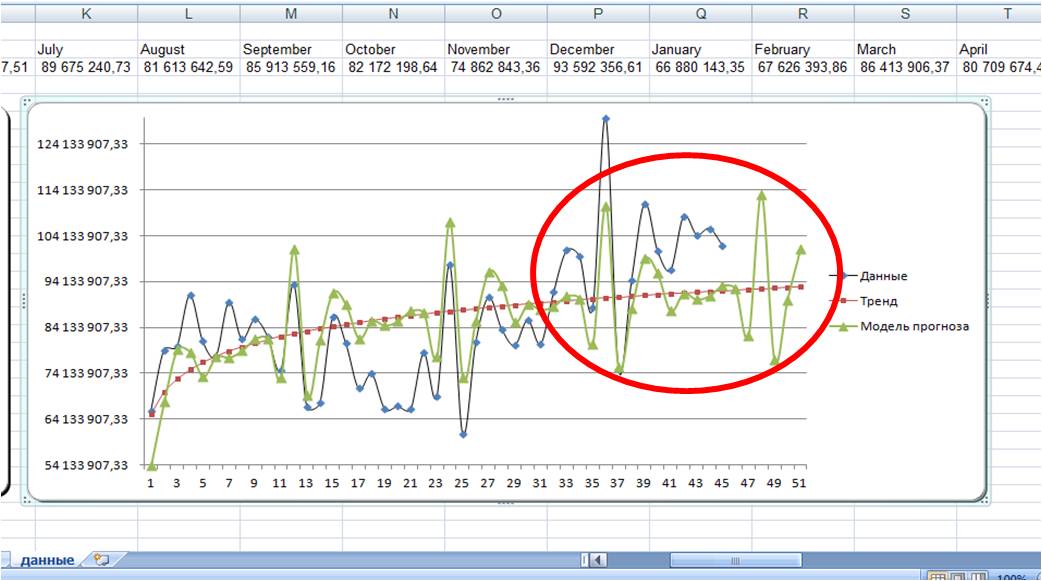
По последним периодам видно, что линейная модель более точно описывает данные за последние месяцы, и она, вероятнее всего, сделает более точный прогноз.
Какую модель прогноза выбрать?
1. Которая на основании тестирования на реальных данных для выбранного промежутка времени (месяца, 3-х месяцев, полугода, года) будет делать максимально точный прогноз, т.е. отношение факта к прогнозу будет близко к 1 или 100%.
2. Модель, которая будет максимально точно описывать фактические данные, т.е. показатель точность прогноза будет приближаться к 1, но не всегда модели точно описывающие данные делают адекватные прогнозы (это надо понимать и оценивать графически).
3. Модель, которой визуально вы больше доверяете с точки зрения описания входящих данных и продления прогнозной модели в будущее.
Для повышения точности прогноза я в своей практике стараюсь использовать 3 этих способа параллельно:
-
По завершении прогнозного периода и в промежутках всегда оцениваю отношение фактических продаж к прогнозу.
-
При построении прогноза анализирую показатель «среднеквадратическое отклонение» и рассчитываю показатель «точность прогноза» для оценки данных и модели.
-
А также на график вывожу анализируемые данные и прогнозную модель, для визуального контроля.
Оценивая прогноз по факту или в промежуточные периоды в случае значительных отклонений фактических продаж от прогнозных, разбираю ситуацию и выясняю причины, в случае необходимости вношу корректировки в прогнозную модель.
С помощью программы Forecast4AC PRO вы можете рассчитать показатель точность прогноза автоматически.
Также Forecast4AC умеет автоматически выбирать оптимальную модель прогноза для каждого временного ряда.
+ одним нажатием строить график «Анализируемые данные + модель прогноза», на котором вы можете оценить, как соотносятся между собой:
-
анализируемые данные;
-
выбранный тренд;
-
модель прогноза;
как в анализируемом периоде, так и в будущем.
Точных прогнозов!
Присоединяйтесь к нам!
Скачивайте бесплатные приложения для прогнозирования и бизнес-анализа:

- Novo Forecast Lite — автоматический расчет прогноза в Excel.
- 4analytics — ABC-XYZ-анализ и анализ выбросов в Excel.
- Qlik Sense Desktop и QlikView Personal Edition — BI-системы для анализа и визуализации данных.
Тестируйте возможности платных решений:
- Novo Forecast PRO — прогнозирование в Excel для больших массивов данных.
Получите 10 рекомендаций по повышению точности прогнозов до 90% и выше.
Зарегистрируйтесь и скачайте решения
Статья полезная? Поделитесь с друзьями
Качество регрессионной модели. Нелинейная регрессия
Значимость уравнения регрессии еще не означает, что выбранная модель достаточно правильно (адекватно) описывает исследуемое экономическое явление. Применение неадекватной модели для целей анализа и прогнозирования может приводить к неоправданно большим ошибкам. Если модель адекватна, то остатки регрессии представляют собой независимые нормально распределенные случайные величины с одинаковой дисперсией. В случае неадекватности модели остатки содержат также и систематическую составляющую, а закон их распределения отличается от нормального. Проверка адекватности регрессионной модели рассматривается в § 3.8.
Обычно в начале исследуется линейная модель, для которой после оценки параметров и проверки значимости уравнения регрессии определяется коэффициент детерминации и оценивается точность.
Коэффициент детерминации R 2 рассчитывается по формуле
 . . |
(2.19) |
Его значение показывает долю вариации результата Y, обусловленную вариацией фактора X. К примеру, если R 2 =0,856, то это означает, что 85,6 % вариации результата Y вызвано вариацией фактора X, а соответственно 14,4 % ( 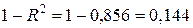 ) — неучтенными и случайными факторами. Коэффициент детерминации принимает значения в интервале от 0 до 1. Чем ближе R 2 к единице, тем лучше модель объясняет вариацию Y, а уравнение регрессии аппроксимирует фактические данные.
) — неучтенными и случайными факторами. Коэффициент детерминации принимает значения в интервале от 0 до 1. Чем ближе R 2 к единице, тем лучше модель объясняет вариацию Y, а уравнение регрессии аппроксимирует фактические данные.
Заметим, что для линейной парной модели коэффициент детерминации равен квадрату коэффициента корреляции: 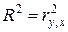 , а стандартная ошибка регрессии Sрег связана с R 2 соотношением
, а стандартная ошибка регрессии Sрег связана с R 2 соотношением
 , , |
(2.20) |
где Sy — стандартное отклонение зависимой переменной Y в исходных данных.
Коэффициент детерминации и F–статистика Фишера (см. § 2.3) связаны между собой соотношением
 , , |
(2.21) |
где n — число наблюдений; m — число оцениваемых параметров регрессионной модели, включая свободный коэффициент b0.
В случае парной линейной регрессии m=2 и
 . . |
(2.22) |
Точность модели, т.е. близость линии регрессии к фактическим данным,характеризует средняя относительная ошибка аппроксимации
 . . |
(2.23) |
Если Еотн не превышает 10 %, то считается, что модель имеет высокую точность, при  точность модели хорошая, при
точность модели хорошая, при  — удовлетворительная, а при
— удовлетворительная, а при 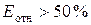 — неудовлетворительная.
— неудовлетворительная.
Средняя относительная ошибка аппроксимации Еотн связана со стандартной ошибкой регрессии Sрег приближенным соотношением
 . . |
(2.24) |
Расхождение между формулами (2.23) и (2.24) обычно незначительное, особенно при достаточно большом объеме наблюдений (  ).
).
После анализа качества линейной модели переходят к исследованию нелинейных моделей, коэффициент детерминации и средняя относительная ошибка аппроксимации которых, определяются по тем же самым формулам и имеют тот же смысл, что и для линейной модели. Наиболее часто на практике используются нелинейные модели, приведенные в табл. 2.2.
Значимость нелинейного уравнения регрессии проверяется по F‑критерию Фишера. Лучшей считается модель, имеющая наибольший коэффициент детерминации R 2 . При незначительных расхождениях в значениях R 2 предпочтение отдается более простой модели. Если модель предполагается использовать для целей анализа, то ее параметры должны иметь содержательную экономическую интерпретацию. Интерпретация параметров степенной, показательной и логарифмической регрессий рассматривается в приведенных ниже примерах.
| Таблица | 2.2 |
| Часто используемые на практике нелинейные модели |
| Форма связи | Модель | Уравнение регрессии |
| 1. Степенная | 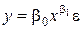 |
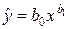 |
| 2. Показательная |  |
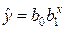 |
| 3. Экспоненциальная (другой вид показательной связи) |  |
 |
| 4. Логарифмическая | 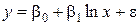 |
 |
| 5. Гиперболическая |  |
 |
| 6. Полиноминальная разных степеней (q — степень полинома) |  |
 |
Решение типовых задач
Пример 2.1
По десяти однородным предприятиям имеется информация, характеризующая зависимость объема выпускаемой продукции (результативная переменная Y, млн. руб.) от объема капиталовложений (фактор X, млн. руб.):
| Предприятие | А | Б | В | Г | Д | Е | Ж | З | И | К |
| Y | ||||||||||
| X |
1. Рассчитать парный коэффициент корреляции между переменными Y и X и проверить его статистическую значимость (уровень значимости a=0,05).
2. Найти параметры уравнения линейной регрессии Y по X и дать их экономическую интерпретацию.
3. Вычислить коэффициент детерминации R 2 и пояснить его смысл.
4. Проверить статистическую значимость уравнения регрессии по F-критерию Фишера (a=0,05).
5. Определить стандартную ошибку регрессии и оценить точность модели с помощью средней относительной ошибки аппроксимации.
6. Построитьдоверительные интервалы для истинных параметров b0 и b1 регрессионной модели и проверить статистическую значимость коэффициентов уравнения регрессии по t-критерию Стьюдента (a=0,05).
7. Спрогнозировать с доверительной вероятностью 0,9 значение показателя Y, если прогнозное значения фактора Х составит 80 % от максимального значения в исходных данных.
8. Изобразить графически результаты моделирования и прогнозирования.
1. Для определения парного коэффициента корреляции ry,x между переменными Y и X в EXCEL может быть использована любая из встроенных функций «КОРРЕЛ» или «ПИРСОН». Использование встроенных функций EXCEL рассмотрено в § 5.4.
Коэффициент корреляции имеет значение
 .
.
Критическое значение коэффициента корреляции для уровня значимости a=0,05 и числа степеней свободы  составляет rкр=0,632, где n=10 — число пар значений переменных. Видно, что коэффициент корреляции превышает по абсолютной величине критическое значение и следовательно является статистически значимым. Положительное значение коэффициента корреляции свидетельствует о прямой связи между переменными Y и X, а превышение им по абсолютной величине 0,8 — о тесной линейной связи.
составляет rкр=0,632, где n=10 — число пар значений переменных. Видно, что коэффициент корреляции превышает по абсолютной величине критическое значение и следовательно является статистически значимым. Положительное значение коэффициента корреляции свидетельствует о прямой связи между переменными Y и X, а превышение им по абсолютной величине 0,8 — о тесной линейной связи.
2. Линейная модель парной регрессии Y по X и уравнение регрессии соответственно имеют вид:
 ;
;
 .
.
Коэффициенты уравнения регрессии определяем с помощью встроенных функций «ОТРЕЗОК» и «НАКЛОН» соответственно. Они имеют значения:
 млн. руб.;
млн. руб.;
 .
.
Окончательно уравнение регрессии —
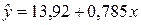 .
.
Значение свободного коэффициента b0 показывает, что при нулевом объеме капиталовложений X объем выпускаемой продукции Y будет составлять в среднем 13,92 млн. руб. Значение углового коэффициента b1=0,785 показывает, что при увеличении объема капиталовложений на 1 млн. руб. объем выпускаемой продукции возрастает в среднем на 0,785 млн. руб.
3. Коэффициент детерминации R 2 парной линейной регрессии определяется с помощью встроенной функции EXCEL «КВПИРСОН». Получим:
 .
.
Значение R 2 показывает, что линейная модель объясняет 86,9 % вариации Y. Другими словами, 86,9 % вариации объема выпускаемой продукции Y обусловлена вариацией объема капиталовложений X.
4. Для проверки статистической значимости уравнения регрессии F‑статистику Фишера определимчерез коэффициент детерминации по формуле (2.22):
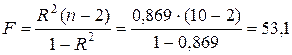 .
.
Табличное значение F-критерия Фишера для уровня значимости a=0,05 и чисел степеней свободы числителя (регрессии)  и знаменателя (остатка)
и знаменателя (остатка)  составляет Fтаб=5,32. Так как F-статистика превышает табличное значение F-критерия, то это свидетельствует о статистической значимости уравнения регрессии в целом.
составляет Fтаб=5,32. Так как F-статистика превышает табличное значение F-критерия, то это свидетельствует о статистической значимости уравнения регрессии в целом.
5. Стандартная ошибка линейной парной регрессии Sрег (см. § 2.2) определяется с помощью встроенной функции EXCEL «СТОШYX». Имеем:
 млн. руб.
млн. руб.
Среднюю относительную ошибку аппроксимации Еотн рассчитаем по приближенной формуле
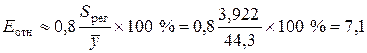 %,
%,
где  млн. руб. — средний объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ».
млн. руб. — средний объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ».
Значение Еотн показывает, что предсказанные уравнением регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 7,1 %. Так как средняя относительная ошибка аппроксимации меньше 10 %, то это свидетельствует о высокой точности линейной модели.
6. Для определения интервальных оценок истинных параметров b0 и b1 регрессионной модели рассчитаем стандартные ошибки коэффициентов уравнения регрессии:
 млн. руб.;
млн. руб.;
 ,
,
где  млн. руб. — стандартное отклонение переменной X в исходных данных, определяемое с помощью встроенной функции «СТАНДОТКЛОН»;
млн. руб. — стандартное отклонение переменной X в исходных данных, определяемое с помощью встроенной функции «СТАНДОТКЛОН»;  — сумма квадратов значений переменной X в исходных данных (функция «СУММКВ»).
— сумма квадратов значений переменной X в исходных данных (функция «СУММКВ»).
Доверительный интервал, «накрывающий» с заданной надежностью 0,95 неизвестное значение параметра b0 модели, имеет вид:
 млн. руб.,
млн. руб.,
где tтаб=2,306 — табличное значение t-критерия Стьюдента для уровня значимости a=0,05 и числа степеней свободы остатка линейной парной регрессии  .
.
Таким образом, с доверительной вероятностью 95 % истинное значение параметра b0 будет находиться в интервале от 3,89 до 23,95 млн. руб. Так как нижняя и верхняя границы доверительного интервала имеют одинаковый знак, то коэффициент b0 уравнения регрессии признается статистически значимым на уровне значимости a=0,05.
Доверительный интервал для параметра b1 модели имеет вид:
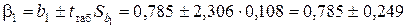 .
.
Это означает, что при увеличении объема капиталовложений X на 1 млн. руб. объем выпускаемой продукции Y с вероятностью 95 % возрастает в среднем на величину, заключенную в интервале от 0,536 до 1,034 млн. руб. Один и тот же знак доверительных границ свидетельствует о статистической значимости коэффициента b1 и уравнения регрессии в целом на уровне a=0,05.
7. Спрогнозируем объем выпускаемой продукции Y, если прогнозное значение x0 объема капиталовложений X составит 80 % от своего максимального значения в исходных данных xmax=59 млн. руб.:
 млн. руб.
млн. руб.
Среднее прогнозируемое значение объема выпускаемой продукции (точечный прогноз) равно
 млн. руб.
млн. руб.
Точечный прогноз можно рассчитать и с помощью встроенной функции «ПРЕДСКАЗ».
Стандартная ошибка прогноза фактического значенияобъема выпускаемой продукции y0 рассчитывается по формуле
 млн. руб.,
млн. руб.,
где 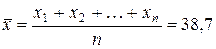 млн. руб. — средний объем капиталовложений, определенный с помощью встроенной функции «СРЗНАЧ».
млн. руб. — средний объем капиталовложений, определенный с помощью встроенной функции «СРЗНАЧ».
Интервальный прогноз фактического значения объема выпускаемой продукции y0 с надежностью g=0,9 (уровень значимости a=0,1) имеет вид:
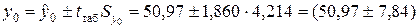 млн. руб.,
млн. руб.,
где tтаб=1,860 — табличное значение t-критерия Стьюдента при уровне значимости a=0,1 и числе степеней свободы .
Объем выпускаемой продукции с вероятностью 90 % будет находиться в интервале от 43,13 до 58,81 млн. руб.
8. График, на котором изображены фактические и предсказанные уравнением регрессии значения Y, строим с помощью надстройки «Мастер диаграмм» EXCEL (рис. 2.5). Данная надстройка позволяет построить линии нескольких видов регрессии (линейной, степенной, логарифмической, экспоненциальной и полиноминальной), определить их уравнение и коэффициент детерминации. Использование «Мастера диаграмм» рассмотрено в § 5.1.

рис. 2.5. Линия линейной парной регрессии и точки прогноза
Пример 2.2
Используя исходные данные предыдущего примера, выполнить следующие действия:
1. С помощью табличного процессора EXCEL построить уравнения линейной, логарифмической, степенной и показательной регрессий Y по X. Для указанных регрессий:
· привести графики их линий;
· дать экономическую интерпретацию параметрам уравнений;
· найти коэффициенты детерминации;
· проверить статистическую значимость уравнений по F-критерию Фишера;
· оценить точность моделей с помощью средней относительной ошибки аппроксимации.
2. Сравнить построенные модели между собой и выбрать лучшую из них для целей анализа и прогнозирования.
1. Линейную, степенную, логарифмическую и показательную регрессии строим с помощью «Мастера диаграмм» EXCEL. Линейная и степенная регрессии показаны на рис. 2.6, логарифмическая и показательная — на рис. 2.7. На графиках приводятся не только линии регрессии, но также их уравнения и коэффициенты детерминации (см. § 5.1).

рис. 2.6. Линии линейной и степенной регрессий

рис. 2.7. Линии логарифмической и показательной регрессий
Рассмотрим последовательно каждую модель.
1) Уравнение линейной регрессии имеет вид:
.
Угловой коэффициент b1=0,785 является показателем среднего абсолютного прироста. Его значение показывает, что при увеличении объема капиталовложений X на 1 млн. руб. объем выпускаемой продукции Y возрастает в среднем на 0,785 млн. руб.
Коэффициент детерминации R 2 =0,869 показывает, что линейная модель объясняет 89,8 % вариации объема выпускаемой продукции Y.
F-статистика Фишера линейной модели определяем через коэффициент детерминации R 2 по формуле
.
Табличное значение F-критерия Фишера для уровня значимости a=0,05 и чисел степеней свободы числителя (регрессии) и знаменателя (остатка)  составляет Fтаб=5,32. Так как F-статистика превышает табличное значение, то это свидетельствует о статистической значимости уравнения линейной регрессии в целом.
составляет Fтаб=5,32. Так как F-статистика превышает табличное значение, то это свидетельствует о статистической значимости уравнения линейной регрессии в целом.
Следует заметить, что табличное значение F-критерия Фишера одинаково как для линейной, так и для всех нелинейных моделей, которые здесь строятся (Fтаб=5,32).
Стандартная ошибка линейной регрессии рассчитывается по формуле
 млн. руб.,
млн. руб.,
где  млн. руб. — стандартное отклонение переменной X в исходных данных, определенное с помощью встроенной функции «СТАНДОТКЛОН».
млн. руб. — стандартное отклонение переменной X в исходных данных, определенное с помощью встроенной функции «СТАНДОТКЛОН».
Среднюю относительную ошибку аппроксимации определяем по приближенной формуле
 %,
%,
где 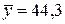 млн. руб. — средний объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ».
млн. руб. — средний объем выпускаемой продукции, определенный с помощью встроенной функции «СРЗНАЧ».
Предсказанные уравнением линейной регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 7,1 %.
2) Уравнение степенной регрессии выглядит следующим образом:
 .
.
Показатель степени b1=0,721 является средним коэффициентом эластичности. Его значение показывает, что при увеличении объема капиталовложений X на 1 % объем выпускаемой продукции Y возрастает в среднем на 0,721 %.
Коэффициент детерминации R 2 =0,873 показывает, что степенная модель объясняет 87,3 % вариации объема выпускаемой продукции Y.
F-статистика степенной модели

также превышает табличное значение F-критерия Фишера (Fтаб=5,32), что указывает на статистическую значимость уравнения степенной регрессии.
Стандартную ошибку и среднюю относительную ошибку аппроксимации нелинейных регрессий будем определять по тем же самым формулам, что и для линейной модели. Для степенной регрессии они равны:
 млн. руб.;
млн. руб.;
 %.
%.
Предсказанные уравнением степенной регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 7,0 %.
3) Уравнение логарифмической регрессии имеет вид:
 .
.
Значение параметра b1=29,9 показывает, что при увеличении объема капиталовложений X на 1 % объем выпускаемой продукции Y возрастает в среднем на  млн. руб.
млн. руб.
Коэффициент детерминации R 2 =0,898 показывает, что логарифмическая модель объясняет 89,8 % вариации объема выпускаемой продукции Y.
F-статистика Фишера логарифмической модели равна

и превышает табличное значение F-критерия Фишера (Fтаб=5,32). Это свидетельствует о статистической значимости уравнения регрессии.
Стандартная ошибка логарифмической регрессии составляет
 млн. руб.
млн. руб.
Средняя относительная ошибка аппроксимации имеет значение
 %.
%.
Предсказанные уравнением логарифмической регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 6,2 %.
4) Уравнение показательной регрессии определяется через экспоненциальную регрессию:
 ,
,
где е=2,718… — основание натуральных логарифмов;  — функция экспоненты (в EXCEL встроенная функция «EXP»).
— функция экспоненты (в EXCEL встроенная функция «EXP»).
Параметр b1=1,019 показательной регрессии является средним коэффициентом роста. Его значение показывает, что при увеличении объема капиталовложений X на 1 млн. руб. объем выпуска продукции Y возрастает в среднем в 1,019 раза, т.е. на 1,9 %.
Заметим, что параметр b1 экспоненциальной регрессии  , умноженный на 100, является средним темпом прироста, выраженным в процентах. Данный вывод вытекает из приближенного соотношения
, умноженный на 100, является средним темпом прироста, выраженным в процентах. Данный вывод вытекает из приближенного соотношения  , при относительно малых значениях a (
, при относительно малых значениях a (  ).
).
Уравнения показательной и экспоненциальной регрессии являются эквивалентными.
Коэффициент детерминации R 2 =0,821 показывает, что показательная модель объясняет 82,1 % вариации объема выпускаемой продукции Y.
F-статистика показательной модели

превышает табличное значение F-критерия Фишера (Fтаб=5,32), что свидетельствует о статистической значимости уравнения регрессии.
Стандартная ошибка показательной регрессии
 млн. руб.
млн. руб.
Средняя относительная ошибка аппроксимации
 %.
%.
Предсказанные уравнением показательной регрессии значения объема выпускаемой продукции Y отличаются от фактических значений в среднем на 8,3 %.
2. Сравнивая между собой коэффициенты детерминации R 2 четырех моделей, можно придти к выводу, что лучшей из них является логарифмическая модель, так как она имеет самое большое значение R 2 . Эту модель и целесообразно использовать в качестве рабочей для анализа и прогнозирования изменения объема выпускаемой продукции Y в зависимости от изменения объема капиталовложений X.
Заметим, что при выборе лучшей модели из четырех рассмотренных для целей анализа параметр b1 должен иметь содержательную интерпретацию. Так, если бы переменные X и Y были относительными величинами и измерялись в процентах, то корректная интерпретация параметра b1 нелинейных моделей оказалась бы затруднительной. В этом случае для прогнозирования следовало бы выбрать модель с большим R 2 , а для целей анализа — линейную модель.
Пример 2.3
В магазине исследуется зависимость количества реализованных за день упаковок шампуня (Y, шт.) от цены одной упаковки (X, руб.). Имеется информация по одиннадцати наименованиям шампуня:
| Шампунь | А | Б | В | Г | Д | Е | Ж | З | И | К | Л |
| Y | |||||||||||
| X |
Выполнить те же самые действия, что и в предыдущем примере.
1. Линейную, степенную, логарифмическую и показательную регрессии строим с помощью «Мастера диаграмм» EXCEL. Линейная и степенная регрессии показаны на рис. 2.8, логарифмическая и показательная — на рис. 2.9.
Используя формулы предыдущего примера, рассчитаем для каждой модели коэффициент детерминации R 2 , F-статистику Фишера, стандартную ошибку регрессии Sрег и среднюю относительную ошибку аппроксимации Eотн (  шт.; Sy=13,631 шт.). Полученные результаты сведены в табл. 2.3.
шт.; Sy=13,631 шт.). Полученные результаты сведены в табл. 2.3.

рис. 2.8. Линии линейной и степенной регрессий

рис. 2.9. Линии логарифмической и показательной регрессий
| Таблица | 2.3 |
| Сводная таблица результатов моделирования |
| Модель | Уравнение регрессии | R 2 | F | Sрег, шт. | Eотн, % |
| 1. Линейная |  |
0,788 | 33,45 | 6,62 | 11,8 |
| 2. Степенная |  |
0,857 | 53,94 | 5,43 | 9,7 |
| 3. Логарифмическая |  |
0,834 | 45,22 | 5,86 | 10,4 |
| 4. Показательная (экспоненциальная) |  ( (  ) ) |
0,825 | 42,43 | 6,01 | 10,7 |
Очевидно, что между переменными X и Y имеется обратная статистическая связь. На это указывают отрицательные значения параметра b1 линейного, степенного и логарифмического уравнений регрессии, а также меньшее единицы значение параметра b1 показательного уравнения. Все уравнения регрессии статистически значимы на уровне значимости a=0,05 ( ;  ; Fтаб=5,12).
; Fтаб=5,12).
Угловой коэффициент b1=–0,933 линейной регрессии показывает, что при увеличении цены шампуня X на 1 руб. количество проданных упаковок Y уменьшается в среднем на 0,933 шт. Линейная модель объясняет 78,8 % вариации Y (R 2 =0,788). Предсказанные уравнением регрессии значения Y отличаются от фактических значений в среднем на 11,8 %.
Показатель степени b1=–0,888 степенной регрессии показывает, что при увеличении цены X на 1 % число реализованных упаковок Y уменьшается в среднем на 0,888 %. Степенная модель объясняет 85,7 % вариации Y. Предсказанные уравнением регрессии значения Y отличаются от фактических в среднем на 9,7 %.
Значение параметра b1=39,6 логарифмической регрессии показывает, что при увеличении цены единицы продукции X на 1 % количество проданных упаковок Y уменьшается в среднем на  шт. Логарифмическая модель объясняет 83,4 % вариации Y. Средняя погрешность предсказания составляет 10,4 %.
шт. Логарифмическая модель объясняет 83,4 % вариации Y. Средняя погрешность предсказания составляет 10,4 %.
Значение основания степени b1=0,979 показательной регрессии показывает, что при увеличении цены X на 1 руб. объем реализации Y составит в среднем 97,9 % от первоначального значения, или, другими словами, уменьшится на 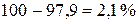 . Это же значение получается, если умножить на 100 параметр «–0,021» экспоненциальной регрессии (см. табл. 2.3). Показательная модель объясняет 82,5 % вариации Y. Предсказанные уравнением регрессии значения Y отличаются от фактических в среднем на 10,7 %.
. Это же значение получается, если умножить на 100 параметр «–0,021» экспоненциальной регрессии (см. табл. 2.3). Показательная модель объясняет 82,5 % вариации Y. Предсказанные уравнением регрессии значения Y отличаются от фактических в среднем на 10,7 %.
2. Сравнивая между собой коэффициенты детерминации R 2 четырех построенных моделей, приходим к выводу, что лучшей является степенная модель, имеющая наибольший R 2 . Эту модель и целесообразно использовать в качестве рабочей для анализа и прогнозирования изменения объема реализации Y от изменения цены единицы продукции X.
Контрольные задания
Используя приведенные ниже данные, выполнить расчеты в соответствии с заданием к примерам 2.1 и 2.2. В вариантах 1 – 5 между переменными присутствует прямая связь, в вариантах 6 – 10 — обратная связь.
Вариант 1(прямая связь)
Вариант 2(прямая связь)
Вариант 3(прямая связь)
Вариант 4(прямая связь)
Вариант 5(прямая связь)
Вариант 6(обратная связь)
Вариант 7(обратная связь)
Вариант 8(обратная связь)
Вариант 9(обратная связь)
Вариант 10(обратная связь)
Тестовые вопросы для самоконтроля
Из перечня предлагаемых ответов на вопрос только один является правильным. Правильные ответы приведены на с. 151. Числовые данные тестов можно использовать как исходные для рассмотренных в § 2.7 примеров.
По десяти интернет-брокерам в секции фондового рынка имеются данные, характеризующие зависимость годового торгового оборота (Y, млрд. руб.) от средней ставки маржинального кредитования (X, % годовых):
| Компания | А | Б | В | Г | Д | Е | Ж | З | И | К |
| Y | 30,82 | 30,8 | 25,14 | 14,1 | 12,73 | 10,8 | 9,74 | 8,42 | 7,65 | |
| X | 16,5 |
Парный коэффициент линейной корреляции между переменными Y и X имеет значение ry,x=–0,451.
Охарактеризовать линейную связь между торговым оборотом Y и средней ставкой маржинального кредитования X, если критическое значение коэффициента корреляции на уровне значимости a=0,05 составляет rкр=0,632.
а) Линейная связь статистически значимая.
б) Линейная связь статистически незначимая.
в) Линейная связь тесная.
г) Линейная связь прямая функциональная.
д) Линейная связь обратная функциональная.
По семи целлюлозно-бумажным компаниям имеются данные, характеризующие зависимость объема выпускаемой продукции (Y, млн. долл. США) от производственной мощности (X, тыс. тонн целлюлозы в год), по итогам года:
| Компания | А | Б | В | Г | Д | Е | Ж |
| Y | |||||||
| X |
Стандартные отклонения переменных Y и X и парный коэффициент корреляции между ними имеют соответственно значения: Sy=344 млн. долл. США, Sx=824 тыс. тонн, ry,x=0,988.
На сколько в среднем увеличивается объем выпускаемой продукции Y при росте производственной мощности X на одну тысячу тонн целлюлозы в год?
а) На 0,344 млн. долл.
б) На 0,824 млн. долл.
в) На 0,412 млн. долл.
г) На 0,988 млн. долл.
д) На 0,280 млн. долл.
Исследуется связь между официальными курсами доллара США (Y, руб./USD) и евро (X, руб./EUR), установленными Центральным банком Российской Федерации. Имеются данные за десять последовательных дней:
| День | ||||||||||
| Y | 28,11 | 27,97 | 27,97 | 28,01 | 27,98 | 28,12 | 28,19 | 28,13 | 28,09 | 28,07 |
| X | 36,59 | 36,46 | 36,56 | 36,47 | 36,28 | 36,13 | 35,98 | 35,97 | 36,00 | 36,13 |
Методом наименьших квадратов было получено уравнение линейной регрессии Y по X:
 .
.
Суммы квадратов отклонений зависимой переменной Y от своего среднего значения составляют:
· обусловленная регрессией — SSрег=0,0240;
Рассчитать F-статистику и проверить статистическую значимость уравнения регрессии, если табличное значение F‑критерия Фишера на уровне значимости a=0,05 составляет Fтаб=5,32.
а) F=6,17; уравнение регрессии статистически значимо.
б) F=0,77; уравнение регрессии статистически незначимо.
в) F=1,77; уравнение регрессии статистически незначимо.
г) F=2,54; уравнение регрессии статистически незначимо.
д) F=14,17; уравнение регрессии статистически значимо.
По девяти из наиболее прибыльных компаний региона имеются данные, характеризующие зависимость чистой прибыли (Y, млн. руб.) от объема реализации (X, млн. руб.) по итогам одного года:
| Компания | А | Б | В | Г | Д | Е | Ж | З | И |
| Y | |||||||||
| X |
Методом наименьших квадратов было получено уравнение линейной регрессии Y по X:
 .
.
Коэффициент детерминациисоставляет R 2 =0,540.
Рассчитать F-статистику и проверить статистическую значимость уравнения регрессии на уровне a=0,05, если табличное значение F‑критерия Фишера составляет Fтаб=5,59.
а) F=0,73; уравнение регрессии статистически незначимо.
б) F=1,17; уравнение регрессии статистически незначимо.
в) F=3,91; уравнение регрессии статистически значимо.
г) F=8,22; уравнение регрессии статистически значимо.
д) F=22,6; уравнение регрессии статистически значимо.
По восьми крупнейшим западным банкам-консультантам на рынке M&A (сопровождение сделок по слияниям и поглощениям) имеются данные, характеризующие зависимость размера комиссионных (Y, млн. долл. США) от объема сделок (X, млрд. долл. США), по итогам трех кварталов года:
| Банк | А | Б | В | Г | Д | Е | Ж | З |
| Y | ||||||||
| X | 305,5 | 265,7 | 240,4 | 149,3 | 101,6 | 114,6 | 122,2 |
Уравнение линейной регрессии Y по X имеет вид:
 .
.
Стандартные ошибки коэффициентов уравнения составляют:
· свободного коэффициента —  млн. долл.;
млн. долл.;
· углового коэффициента —  млн. долл./млрд. долл.
млн. долл./млрд. долл.
Проверить статистическую значимость уравнения регрессии на уровне значимости a=0,05 для чего рассчитать соответствующую t-статистику. Табличное значение t‑критерия Стьюдента составляет tтаб=2,447.
а) t=0,892; уравнение регрессии статистически незначимо.
б) t=2,510; уравнение регрессии статистически значимо.
в) t=1,121; уравнение регрессии статистически незначимо.
г) t=3,404; уравнение регрессии статистически значимо.
д) t=3,816; уравнение регрессии статистически значимо.
По семи оценочным компаниям имеются данные, характеризующие зависимость совокупной выручки за полугодие (Y, тыс. руб.) от количества специалистов-оценщиков (X, чел.):
| Компания | А | Б | В | Г | Д | Е | Ж |
| Y | |||||||
| X |
С помощью «Мастера диаграмм» EXCEL были получены уравнения линейной, степенной, показательной и логарифмической регрессий Y по X, и для каждой модели определен коэффициент детерминации R 2 :
· линейная:  ; R 2 =0,877;
; R 2 =0,877;
· степенная:  ; R 2 =0,858;
; R 2 =0,858;
· показательная:  ; R 2 =0,939;
; R 2 =0,939;
· логарифмическая:  ; R 2 =0,780.
; R 2 =0,780.
Какая из моделей лучше характеризует вариацию совокупной выручки Y?
Исследуется связь между ценой нефти марки Urals (Y, долл. США/баррель) и ценой нефти марки Brent (X, долл./баррель) по итогам торгов на Международной нефтяной бирже за десять торговых дней:
| День | ||||||||||
| Y | 39,91 | 41,18 | 40,38 | 39,4 | 39,44 | 39,54 | 40,04 | 38,42 | 38,49 | 39,81 |
| X | 44,8 | 45,87 | 44,64 | 43,65 | 43,38 | 43,69 | 43,05 | 42,93 | 42,98 | 44,42 |
Было получено уравнение линейной регрессии Y по X:
 .
.
Дать правильную экономическую интерпретацию угловому коэффициенту b1=0,715 уравнения регрессии.
Угловой коэффициент b1=0,715 уравнения регрессии показывает, что …
а) … 71,5 % вариации цены нефти Urals объясняется вариацией цены нефти Brent.
б) … с ростом цены нефти Brent на один процент цена нефти Urals возрастает в среднем на 0,715 %.
в) … с ростом цены нефти Brent на один процент цена нефти Urals возрастает в среднем на 0,715 долл./баррель.
г) … с ростом цены барреля нефти Brent на один доллар цена барреля нефти Urals возрастает в среднем на 0,715 %.
д) … с ростом цены барреля нефти Brent на один доллар цена барреля нефти Urals возрастает в среднем на 0,715 доллара.
Исследуется зависимость месячного торгового оборота универсального магазина (Y, млн. руб.) от размера торговых площадей (X, м 2 ). Имеются данные по восьми универмагам города:
| Магазин | А | Б | В | Г | Д | Е | Ж | З |
| Y | ||||||||
| X |
Было получено уравнение степенной регрессии Y по X:
 .
.
Дать правильную экономическую интерпретацию показателю степени b1=0,552 в уравнении регрессии.
Показатель степени b1=0,552 в уравнении регрессии показывает, что …
а) … 55,2 % вариации торгового оборота объясняется вариацией размера торговых площадей.
б) … с увеличением размера торговых площадей на один процент торговый оборот возрастает в среднем на 0,552 %.
в) … с увеличением размера торговых площадей на один процент торговый оборот возрастает в среднем на 0,552 млн. руб.
г) … с увеличением размера торговых площадей на один квадратный метр торговый оборот возрастает в среднем на 0,552 %.
д) … с увеличением размера торговых площадей на один квадратный метр торговый оборот возрастает в среднем на 0,552 млн. руб.
По девяти туристическим агентствам города исследуется зависимость месячного торгового оборота (Y, тыс. долл. США) от количества менеджеров по туризму (X, чел.):
| Турагентство | А | Б | В | Г | Д | Е | Ж | З | И |
| Y | |||||||||
| X |
Было получено уравнение показательной регрессии Y по X:
 .
.
Дать правильную экономическую интерпретацию основанию степени b1=1,076 в уравнении регрессии.
Основание степени b1=1,076 в уравнении регрессии показывает, что …
а) … с увеличением численности менеджеров по туризму на одного человека торговый оборот возрастает в среднем в 1,076 раз, т.е. на 7,6 %.
б) … с увеличением численности менеджеров по туризму на одного человека торговый оборот возрастает в среднем на 1,076 %.
в) … с увеличением численности менеджеров по туризму на одного человека торговый оборот возрастает в среднем на 1,076 тыс. руб.
г) … с увеличением численности менеджеров по туризму на один процент торговый оборот возрастает в среднем в 1,076 раз, т.е. на 7,6 %.
д) … 1,076 % вариации торгового оборота объясняется вариацией численности менеджеров по туризму.
Исследуется связь между учетной ценой Банка России на аффинированное золото (Y, руб./г) и ценой золота на мировых рынках (X, долл. за тройскую унцию) по данным за десять последовательных дней:
| День | ||||||||||
| Y | 390,38 | 391,74 | 393,61 | 378,8 | 377,01 | 381,28 | 383,09 | 372,84 | 374,48 | 381,19 |
| X | 438,9 | 441,1 | 422,2 | 422,5 | 423,3 | 426,8 | 415,9 | 418,85 | 427,1 |
Методом наименьших квадратов было получено уравнение линейной регрессии Y по X:
 .
.
Построить интервальный прогноз учетной цены Банка России на аффинированное золото y0 с надежностью 90 % при цене золота x0=410 долл. за тройскую унцию, если стандартная ошибка прогноза фактического значения Y при этом составляет  руб./г, а табличное значение t-критерия Стьюдента — tтаб=1,86.
руб./г, а табличное значение t-критерия Стьюдента — tтаб=1,86.
С вероятностью 0,9 учетная цена золота будет находиться в интервале …
Уравнение нелинейной регрессии
Вместе с этим калькулятором также используют следующие:
Уравнение множественной регрессии
Виды нелинейной регрессии
Здесь ε — случайная ошибка (отклонение, возмущение), отражающая влияние всех неучтенных факторов.
Уравнению регрессии первого порядка — это уравнение парной линейной регрессии.
Уравнение регрессии второго порядка это полиномальное уравнение регрессии второго порядка: y = a + bx + cx 2 .
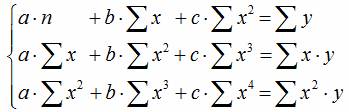
Уравнение регрессии третьего порядка соответственно полиномальное уравнение регрессии третьего порядка: y = a + bx + cx 2 + dx 3 .
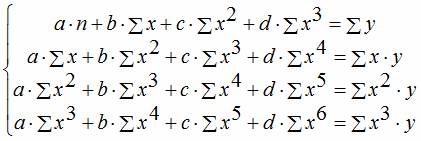
Чтобы привести нелинейные зависимости к линейной используют методы линеаризации (см. метод выравнивания):
- Замена переменных.
- Логарифмирование обеих частей уравнения.
- Комбинированный.
| y = f(x) | Преобразование | Метод линеаризации |
| y = b x a | Y = ln(y); X = ln(x) | Логарифмирование |
| y = b e ax | Y = ln(y); X = x | Комбинированный |
| y = 1/(ax+b) | Y = 1/y; X = x | Замена переменных |
| y = x/(ax+b) | Y = x/y; X = x | Замена переменных. Пример |
| y = aln(x)+b | Y = y; X = ln(x) | Комбинированный |
| y = a + bx + cx 2 | x1 = x; x2 = x 2 | Замена переменных |
| y = a + bx + cx 2 + dx 3 | x1 = x; x2 = x 2 ; x3 = x 3 | Замена переменных |
| y = a + b/x | x1 = 1/x | Замена переменных |
| y = a + sqrt(x)b | x1 = sqrt(x) | Замена переменных |
Пример . По данным, взятым из соответствующей таблицы, выполнить следующие действия:
- Построить поле корреляции и сформулировать гипотезу о форме связи.
- Рассчитать параметры уравнений линейной, степенной, экспоненциальной, полулогарифмической, обратной, гиперболической парной регрессии.
- Оценить тесноту связи с помощью показателей корреляции и детерминации.
- Дать с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
- Оценить с помощью средней ошибки аппроксимации качество уравнений.
- Оценить с помощью F-критерия Фишера статистическую надежность результатов регрессионного моделирования. По значениям характеристик, рассчитанных в пп. 4, 5 и данном пункте, выбрать лучшее уравнение регрессии и дать его обоснование.
- Рассчитать прогнозное значение результата, если прогнозное значение фактора увеличится на 15% от его среднего уровня. Определить доверительный интервал прогноза для уровня значимости α=0,05 .
- Оценить полученные результаты, выводы оформить в аналитической записке.
| Год | Фактическое конечное потребление домашних хозяйств (в текущих ценах), млрд. руб. (1995 г. — трлн. руб.), y | Среднедушевые денежные доходы населения (в месяц), руб. (1995 г. — тыс. руб.), х |
| 1995 | 872 | 515,9 |
| 2000 | 3813 | 2281,1 |
| 2001 | 5014 | 3062 |
| 2002 | 6400 | 3947,2 |
| 2003 | 7708 | 5170,4 |
| 2004 | 9848 | 6410,3 |
| 2005 | 12455 | 8111,9 |
| 2006 | 15284 | 10196 |
| 2007 | 18928 | 12602,7 |
| 2008 | 23695 | 14940,6 |
| 2009 | 25151 | 16856,9 |
Решение. В калькуляторе последовательно выбираем виды нелинейной регрессии. Получим таблицу следующего вида.
Экспоненциальное уравнение регрессии имеет вид y = a e bx
После линеаризации получим: ln(y) = ln(a) + bx
Получаем эмпирические коэффициенты регрессии: b = 0.000162, a = 7.8132
Уравнение регрессии: y = e 7.81321500 e 0.000162x = 2473.06858e 0.000162x
Степенное уравнение регрессии имеет вид y = a x b
После линеаризации получим: ln(y) = ln(a) + b ln(x)
Эмпирические коэффициенты регрессии: b = 0.9626, a = 0.7714
Уравнение регрессии: y = e 0.77143204 x 0.9626 = 2.16286x 0.9626
Гиперболическое уравнение регрессии имеет вид y = b/x + a + ε
После линеаризации получим: y=bx + a
Эмпирические коэффициенты регрессии: b = 21089190.1984, a = 4585.5706
Эмпирическое уравнение регрессии: y = 21089190.1984 / x + 4585.5706
Логарифмическое уравнение регрессии имеет вид y = b ln(x) + a + ε
Эмпирические коэффициенты регрессии: b = 7142.4505, a = -49694.9535
Уравнение регрессии: y = 7142.4505 ln(x) — 49694.9535
Нелинейные модели регрессии. Виды нелинейных уравнений регрессии. Линеаризация нелинейных моделей регрессии. Оценка качества нелинейных уравнений регрессии.
При исследовании социально-экономических явлений и процессов далеко не все зависимости можно описать с помощью линейной связи. Поэтому в эконометрическом моделировании широко используется класс нелинейных моделей регрессии, которые делятся на два класса:
1) модели регрессии, нелинейные относительно включенных в анализ независимых переменных, но линейные по оцениваемым параметрам;
2) модели регрессии, нелинейные по оцениваемым параметрам.
К моделям регрессии, нелинейным относительно включённых в анализ независимых переменных (но линейных по оцениваемым параметрам), относятся полиномы выше второго порядка и гиперболическая функция.
Модели регрессии, нелинейным относительно включённых в анализ независимых переменных, характеризуются тем, что зависимая переменная yi линейно связана с параметрами β0…βn модели.
Полиномы или полиномиальные функции применяются при анализе процессов с монотонным развитием и отсутствием пределов роста. Данному условию отвечают большинство экономических показателей (например, натуральные показатели промышленного производства). Полиномиальные функции характеризуются отсутствием явной зависимости приростов факторных переменных от значений результативной переменной yi.
Общий вид полинома n-го порядка (n-ой степени):
Чаще всего в эконометрическом моделировании применяется полином второго порядка (параболическая функция), характеризующий равноускоренное развитие процесса (равноускоренный рост или снижение уровней):
Полиномы, чей порядок выше четвёртого, в эконометрических исследованиях обычно не применяются, потому что они не способны точно отразить существующую зависимость между результативной и факторными переменными.
Гиперболическая функция характеризует нелинейную зависимость между результативной переменной yi и факторной переменной xi, однако, данная функция является линейной по оцениваемым параметрам β0 и β1.
Гиперболоид или гиперболическая функция имеет вид:
Данная гиперболическая функция является равносторонней.
В качестве примера эконометрической модели в виде гиперболической функции можно привести модель зависимости затрат на единицу продукции от объёма производства.
Неизвестные параметры β0…βn модели регрессии, нелинейной по факторным переменным, можно найти только после того, как модели будет приведена к линейному виду.
Для того чтобы оценить неизвестные параметры β0…βn нелинейной регрессионной модели необходимо привести её к линейному виду. Суть процесс линеаризации нелинейных по факторным переменным моделей регрессии заключается в замене нелинейных факторных переменных на линейные переменные.
Рассмотрим процесс линеаризации полиномиальной функции порядка n:
Заменим все факторные переменные на линейные следующим образом:
Тогда модель множественной регрессии можно записать в виде:
yi=β0+β1c1i+ β2c2i+…+ βncni+εi.
Рассмотрим процесс линеаризации гиперболической функции:
Данная функция может быть приведена к линейному виду путём замены нелинейной факторной переменной 1/x на линейную переменную с. Тогда модель регрессии можно записать в виде:
Следовательно, модели регрессии, нелинейные относительно включенных в анализ независимых переменных, но линейные по оцениваемым параметрам, могут быть преобразованы к линейному виду. Это позволяет применять к линеаризованным моделям регрессии классические методы определения неизвестных параметров модели (метод наименьших квадратов), а также методы проверки различных гипотез
Характеристика временных рядов. Временные ряды данных. Структура временного ряда. Аддитивная и мультипликативная модели временных рядов. Модели стационарных и нестационарных временных рядов и их идентификация.
Система одновременных уравнений. Общие понятие о системах уравнений, используемых эконометрике. Классификация систем уравнений. Идентификация систем эконометрических уравнений. Методы оценки параметров систем одновременных уравнений.
http://math.semestr.ru/corel/noncorel.php
http://helpiks.org/8-19901.html