
Детальный анализ
проявления ошибок показывает их глубокую
связь с методами структурного построения
программ, типом языка программирования,
степенью автоматизации технологии
проектирования и многими другими
факторами. Статистические характеристики
различных типов ошибок трудно описать
математическими моделями, и более
доступны для математического описания
обобщенные характеристики ошибок в
комплексе программ. Путем анализа и
обобщения экспериментальных данных
реальных разработок предложено несколько
математических моделей, описывающих
основные закономерности изменения
суммарного
количества вторичных ошибок
в программах. Модели имеют вероятностный
характер, и достоверность прогнозов в
значительной степени зависит от точности
исходных данных и глубины прогнозирования
по времени. Эти математические модели
предназначены для оценки:
-
надежности
функционирования комплекса программ
в процессе отладки, испытаний и
эксплуатации; -
числа ошибок,
оставшихся невыявленными в анализируемых
программах; -
времени, требующегося
для обнаружения следующей ошибки в
функционирующей программе; -
времени, необходимого
для выявления всех ошибок с заданной
вероятностью.
Точное определение
полного числа невыявленных ошибок в
комплексе программ прямыми
методами измерения невозможно.
Однако имеются пути для приближенной
статистической оценки их полного числа
или вероятности ошибки в каждой команде
программы. Такие оценки базируются на
построении математических Моделей в
предположении о жесткой корреляции
между общим количеством и проявлениями
ошибок в комплексе программ после его
отладки в течение времени T,
т. е. между:
-
суммарным
количеством первичных ошибок в комплексе
программ (n0)
или вероятностью ошибки в каждой команде
программы (p0); -
количеством
ошибок, выявляемых в единицу времени
в процессе тестирования и отладки при
постоянных усилиях на ее проведение
{dn/dt); -
интенсивностью
искажений результатов в единицу времени
()
на выходе комплекса программ вследствие
невыявленных первичных ошибок при
функционировании программ.
Наиболее доступно
для измерения количество вторичных
ошибок в программе, выявляемых в единицу
времени в процессе отладки. Возможна
также непосредственная регистрация
отказов и наиболее крупных искажений
результатов, выявляемых средствами
оперативного контроля в процессе
функционирования программ. Все три
показателя связаны некоторыми
коэффициентами пропорциональности,
значения которых зависят, в частности,
от интервала времени, на котором
производится сопоставление, от
быстродействия ЭВМ, от эффективности
средств автоматизации отладки и от
некоторых других параметров. При
фиксированных условиях разработки и
функционирования конкретного комплекса
программ эти коэффициенты имеют вполне
определенное значения. Для другой
подобной системы коэффициенты могут
несколько измениться, однако оценки,
полученные для нескольких конкретных
систем, позволяют прогнозировать эти
характеристики, а следовательно, и
соответствующие показатели надежности
ПС в зависимости от длительности отладки
и ряда других факторов.
Описаны несколько
математических моделей, основой которых
являются различные гипотезы о характере
проявления вторичных ошибок в программах.
Эти гипотезы в той или иной степени
апробированы при обработке данных
реальных разработок, и их можно разделить
на три группы. В первую
группу входят
очевидные допущения, статистическая
проверка которых невозможна и
нецелесообразна. Вторую группу составляют
допущения, определяющие специфические
характеристики модели и требующие
статистической проверки и обоснования
на базе экспериментальных исследований.
В третью группу включены второстепенные
допущения, расширяющие и уточняющие
возможности применения модели и частично
доступные экспериментальной проверке.
Первая группа
допущений включает предположение о
наблюдаемости
искажений данных,
программ или вычислительного процесса,
обусловленных первичными ошибками в
программах. Первичная ошибка, являющаяся
причиной искажения результатов, либо
фиксируется и исправляется после
завершения этапа тестирования, либо
вообще не обнаруживается, так как
проявление ее последствий незначительно.
Предполагается,
что множество тестов более или менее
равномерно
покрывает
все множество реальных исходных данных
и отсутствуют априорные сведения для
искусственного повышения интенсивности
ошибок при некоторых тестах. Тем самым
состав тестов представляется случайным
относительно области изменения входных
данных программы и содержащихся в ней
необнаруженных первичных ошибок.
Наличие большого
числа разнообразных данных, необходимых
для исполнения программ, и практически
некоррелированное их изменение приводит
к внешне
случайному выбору маршрута, по
которому исполняется программа в каждом
конкретном случае. В результате
интенсивность проявления ошибок при
реальном функционировании программ
зависит от среднего быстродействия ЭВМ
и практически не зависит от конкретного
распределения типов команд на маршрутах
обработки данных между ошибками.
Коллектив
специалистов,
их квалификация и загруженность
предполагаются постоянными
на интервале проектирования и исследования
характеристик ошибок. Также постоянным
считается доступное машинное время для
проведения проверок программ.
Вторая группа
допущений при построении математических
моделей ошибок является основной и
проверена интегрально по обобщенным
характеристикам частости обнаружения
ошибок и дифференцирование путем анализа
правомерности каждого допущения. Ниже
рассмотрены допущения при построении
экспоненциальной модели.
Интервалы времени
между обнаруживаемыми искажениями
результатов предполагаются статистически
независимыми.
Время измеряется по фактической наработке
длительностей исполнения программ
без учета дополнительных затрат
календарного времени на локализацию,
диагностику и исправление ошибок.
Предполагается,
что интенсивность
проявления ошибок остается постоянной,
пока не произведено исправление первичной
ошибки или не изменена программа по
другой причине. Если каждая обнаруженная
ошибка исправляется, то значения
интервалов времени между их проявлениями
изменяются по экспоненциальному закону.
Интегральная проверка распределения
интервалов времени между обнаружениями
ошибок показала, что оно достаточно
хорошо аппроксимируется экспонентой.
Логично предположить,
что интенсивность
обнаружения ошибок пропорциональна
суммарному числу первичных ошибок,
имеющихся
в данный момент в комплексе программ.
Это допущение подтверждено расчетом
значений суммарного числа ошибок для
хорошо отлаженных и переданных в
эксплуатацию комплекса программ на ряд
предыдущих моментов времени, когда
проводилась отладка.
Каждая обнаруженная
ошибка подлежит исправлению, поэтому
предполагается, что частота
исправления ошибок пропорциональна
частоте их обнаружения.
Однако некоторые исправления, в свою
очередь, содержат ошибки. Кроме того,
некоторые ошибки являются связанными,
и при обнаружении проявления одной
ошибки следует исправление нескольких
первичных ошибок. Из-за этого частота
обнаружения ошибок и частота их
исправления не равны, а должны быть
связаны некоторым коэффициентом
пропорциональности. Коэффициенты
корреляции для исследованных комплексов
программ довольно высокие — от 0,52 до
0,82 при среднем значении около 0,68, т. е.
достаточно хорошо подтверждают гипотезу.
Третья группа
допущений детализирует использование
ресурсов на корректировку программ и
повышение
их качества.
Приведенные
предположения позволяют построить
экспоненциальную математическую модель
распределения моментов обнаружения
ошибок в программах и установить связь
между интенсивностью обнаружения ошибок
при отладке dn/d,
интенсивностью проявления ошибок при
нормальном функционировании программ
и числом первичных ошибок п.
Предположим, что в начале отладки
комплекса программ при =0
в нем содержалось N0
первичных ошибок. После отладки в
течение времени осталось п0
первичных
ошибок и устранено п
ошибок (n0
+ n
= N0).
Время
соответствует длительности исполнения
программы на ЭВМ для обнаружения ошибок
и не учитывает время, необходимое для
анализа результатов и проведения
корректировок. Календарное время к
отладочных и испытательных работ с
реальным комплексом программ значительно
больше, так как после тестирования
программ, на которое затрачивается
машинное время т, необходимо время на
анализ результатов, на обнаружение и
локализацию ошибок, а также на их
устранение.
При постоянных
усилиях на отладку интенсивность
обнаружения искажений вычислительного
процесса, программ или данных вследствие
еще не выявленных ошибок пропорциональна
количеству оставшихся первичных ошибок
в комплексе программ. Предположение о
сильной корреляции между значениями
по
и dn/d
проверено анализом реальных характеристик
процесса обнаружения ошибок. Тогда
![]() (11.1)_
(11.1)_
где коэффициенты
К и К’ учитывают масштаб времени,
используемый для описания процесса
обнаружения ошибок, быстродействие ЭВМ
и другие параметры. Значение коэффициента
К’ можно определить как изменение темпа
проявления искажений при переходе от
функционирования программ на специальных
тестах к функционированию на типовых
исходных данных. В начале отладки это
различие может быть значительным, однако
при завершении отладки и при испытаниях
тестовые данные практически совпадают
с исходными данными при нормальной
эксплуатации. Поэтому ниже К’ полагается
равным единице (К’=1).
Таким образом,
интенсивность обнаружения ошибок в
программе и абсолютное число устраненных
первичных ошибок связываются уравнением
![]() (11.2)
(11.2)
Так как выше
предполагалось, что в начале отладки
при =
0 отсутствуют обнаруженные ошибки, то
решение уравнения (11.2) имеет вид
![]() (11.3)
(11.3)
пропорционально
интенсивности их обнаружения dn/d
с точностью до коэффициента К.
Наработка между
проявлениями ошибок, которые,
рассматриваются как обнаруживаемые
искажения программ, данных или
вычислительного процесса, равны величине,
обратной интенсивности обнаружения
ошибок:
![]() (11.4)
(11.4)
Если учесть, что
до начала отладки в комплексе программ
содержалось N0
первичных
ошибок и этому соответствовала наработка
T0
, то функцию наработки между проявлениями
ошибок от длительно-
![]() (11.5)
(11.5)
Если известны все
моменты обнаружения ошибок
ti
и каждый раз в эти моменты обнаруживается
и достоверно устраняется одна первичная
ошибка, то, используя метод максимального
правдоподобия, получим уравнение для
определения значения начального
количества первичных ошибок N0
 (11.6)
(11.6)
и выражение для
расчета коэффициента пропорциональности
 (11.7)
(11.7)
Необходимые для
расчетов К и N0
экспериментальные значения ti
определяются
в процессе отладки данного или аналогичных
комплексов программ, созданных тем же
коллективом разработчиков и при такой
же технологии. В результате можно
рассчитать число оставшихся в программе
первичных ошибок и среднюю наработку
Т
до обнаружения следующей ошибки.
В процессе отладки
и испытания программ для повышения
наработки между проявлениями ошибок
от величины Т1
до значения Т2
необходимо обнаружить и устранить n
ошибок. Эту величину можно определить,
выразив число обнаруживаемых ошибок
через длительность наработки на
проявление ошибок, для чего подставим
(11.4) в {11.2). Тогда
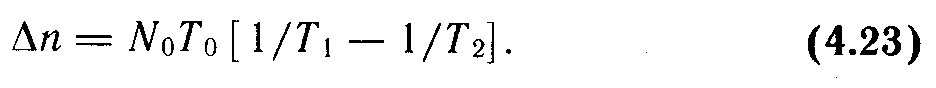 (11.8)
(11.8)
Аналогичными
несложными преобразованиями можно
получить затраты времени на проведение
отладки ,
которые позволяют устранить n
ошибок и
соответственно повысить наработку
между очередными обнаружениями ошибок
от значения Т1
до Т2:
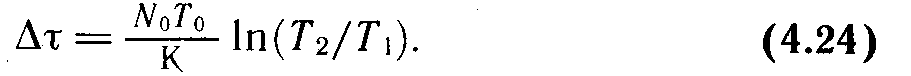 (11.9)
(11.9)
Следует подчеркнуть
статистический характер приведенных
соотношений. Неравномерность выбора
маршрутов исполнения программы при
нормальной эксплуатации, разное влияние
конкретных типов ошибок в программах
на проявление их при функционировании,
а также сравнительно небольшие значения
n
и n,
особенно на заключительных этапах
отладки, приводят к тому, что флюктуации
интервалов времени между обнаружением
ошибок
могут быть весьма значительными
From Wikipedia, the free encyclopedia
In digital transmission, the number of bit errors is the numbers of received bits of a data stream over a communication channel that have been altered due to noise, interference, distortion or bit synchronization errors.
The bit error rate (BER) is the number of bit errors per unit time. The bit error ratio (also BER) is the number of bit errors divided by the total number of transferred bits during a studied time interval. Bit error ratio is a unitless performance measure, often expressed as a percentage.[1]
The bit error probability pe is the expected value of the bit error ratio. The bit error ratio can be considered as an approximate estimate of the bit error probability. This estimate is accurate for a long time interval and a high number of bit errors.
Example[edit]
As an example, assume this transmitted bit sequence:
1 1 0 0 0 1 0 1 1
and the following received bit sequence:
0 1 0 1 0 1 0 0 1,
The number of bit errors (the underlined bits) is, in this case, 3. The BER is 3 incorrect bits divided by 9 transferred bits, resulting in a BER of 0.333 or 33.3%.
Packet error ratio[edit]
The packet error ratio (PER) is the number of incorrectly received data packets divided by the total number of received packets. A packet is declared incorrect if at least one bit is erroneous. The expectation value of the PER is denoted packet error probability pp, which for a data packet length of N bits can be expressed as
 ,
,

assuming that the bit errors are independent of each other. For small bit error probabilities and large data packets, this is approximately

Similar measurements can be carried out for the transmission of frames, blocks, or symbols.
The above expression can be rearranged to express the corresponding BER (pe) as a function of the PER (pp) and the data packet length N in bits:
![{displaystyle p_{e}=1-{sqrt[{N}]{(1-p_{p})}}}](https://wikimedia.org/api/rest_v1/media/math/render/svg/f5d380e45b0451c45265e199221fae5bd5b84bf9)
Factors affecting the BER[edit]
In a communication system, the receiver side BER may be affected by transmission channel noise, interference, distortion, bit synchronization problems, attenuation, wireless multipath fading, etc.
The BER may be improved by choosing a strong signal strength (unless this causes cross-talk and more bit errors), by choosing a slow and robust modulation scheme or line coding scheme, and by applying channel coding schemes such as redundant forward error correction codes.
The transmission BER is the number of detected bits that are incorrect before error correction, divided by the total number of transferred bits (including redundant error codes). The information BER, approximately equal to the decoding error probability, is the number of decoded bits that remain incorrect after the error correction, divided by the total number of decoded bits (the useful information). Normally the transmission BER is larger than the information BER. The information BER is affected by the strength of the forward error correction code.
Analysis of the BER[edit]
The BER may be evaluated using stochastic (Monte Carlo) computer simulations. If a simple transmission channel model and data source model is assumed, the BER may also be calculated analytically. An example of such a data source model is the Bernoulli source.
Examples of simple channel models used in information theory are:
- Binary symmetric channel (used in analysis of decoding error probability in case of non-bursty bit errors on the transmission channel)
- Additive white Gaussian noise (AWGN) channel without fading.
A worst-case scenario is a completely random channel, where noise totally dominates over the useful signal. This results in a transmission BER of 50% (provided that a Bernoulli binary data source and a binary symmetrical channel are assumed, see below).
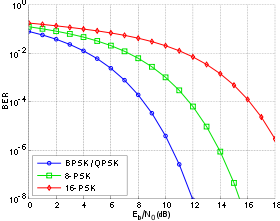
Bit-error rate curves for BPSK, QPSK, 8-PSK and 16-PSK, AWGN channel.

In a noisy channel, the BER is often expressed as a function of the normalized carrier-to-noise ratio measure denoted Eb/N0, (energy per bit to noise power spectral density ratio), or Es/N0 (energy per modulation symbol to noise spectral density).
For example, in the case of QPSK modulation and AWGN channel, the BER as function of the Eb/N0 is given by:
 .[2]
.[2]
People usually plot the BER curves to describe the performance of a digital communication system. In optical communication, BER(dB) vs. Received Power(dBm) is usually used; while in wireless communication, BER(dB) vs. SNR(dB) is used.
Measuring the bit error ratio helps people choose the appropriate forward error correction codes. Since most such codes correct only bit-flips, but not bit-insertions or bit-deletions, the Hamming distance metric is the appropriate way to measure the number of bit errors. Many FEC coders also continuously measure the current BER.
A more general way of measuring the number of bit errors is the Levenshtein distance.
The Levenshtein distance measurement is more appropriate for measuring raw channel performance before frame synchronization, and when using error correction codes designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.[3]
Mathematical draft[edit]
The BER is the likelihood of a bit misinterpretation due to electrical noise  . Considering a bipolar NRZ transmission, we have
. Considering a bipolar NRZ transmission, we have
 for a «1» and
for a «1» and  for a «0». Each of
for a «0». Each of  and
and  has a period of
has a period of  .
.
Knowing that the noise has a bilateral spectral density  ,
,
is 
and is  .
.
Returning to BER, we have the likelihood of a bit misinterpretation  .
.
 and
and 
where  is the threshold of decision, set to 0 when
is the threshold of decision, set to 0 when  .
.
We can use the average energy of the signal  to find the final expression :
to find the final expression :

±§
Bit error rate test[edit]
BERT or bit error rate test is a testing method for digital communication circuits that uses predetermined stress patterns consisting of a sequence of logical ones and zeros generated by a test pattern generator.
A BERT typically consists of a test pattern generator and a receiver that can be set to the same pattern. They can be used in pairs, with one at either end of a transmission link, or singularly at one end with a loopback at the remote end. BERTs are typically stand-alone specialised instruments, but can be personal computer–based. In use, the number of errors, if any, are counted and presented as a ratio such as 1 in 1,000,000, or 1 in 1e06.
Common types of BERT stress patterns[edit]
- PRBS (pseudorandom binary sequence) – A pseudorandom binary sequencer of N Bits. These pattern sequences are used to measure jitter and eye mask of TX-Data in electrical and optical data links.
- QRSS (quasi random signal source) – A pseudorandom binary sequencer which generates every combination of a 20-bit word, repeats every 1,048,575 words, and suppresses consecutive zeros to no more than 14. It contains high-density sequences, low-density sequences, and sequences that change from low to high and vice versa. This pattern is also the standard pattern used to measure jitter.
- 3 in 24 – Pattern contains the longest string of consecutive zeros (15) with the lowest ones density (12.5%). This pattern simultaneously stresses minimum ones density and the maximum number of consecutive zeros. The D4 frame format of 3 in 24 may cause a D4 yellow alarm for frame circuits depending on the alignment of one bits to a frame.
- 1:7 – Also referred to as 1 in 8. It has only a single one in an eight-bit repeating sequence. This pattern stresses the minimum ones density of 12.5% and should be used when testing facilities set for B8ZS coding as the 3 in 24 pattern increases to 29.5% when converted to B8ZS.
- Min/max – Pattern rapid sequence changes from low density to high density. Most useful when stressing the repeater’s ALBO feature.
- All ones (or mark) – A pattern composed of ones only. This pattern causes the repeater to consume the maximum amount of power. If DC to the repeater is regulated properly, the repeater will have no trouble transmitting the long ones sequence. This pattern should be used when measuring span power regulation. An unframed all ones pattern is used to indicate an AIS (also known as a blue alarm).
- All zeros – A pattern composed of zeros only. It is effective in finding equipment misoptioned for AMI, such as fiber/radio multiplex low-speed inputs.
- Alternating 0s and 1s — A pattern composed of alternating ones and zeroes.
- 2 in 8 – Pattern contains a maximum of four consecutive zeros. It will not invoke a B8ZS sequence because eight consecutive zeros are required to cause a B8ZS substitution. The pattern is effective in finding equipment misoptioned for B8ZS.
- Bridgetap — Bridge taps within a span can be detected by employing a number of test patterns with a variety of ones and zeros densities. This test generates 21 test patterns and runs for 15 minutes. If a signal error occurs, the span may have one or more bridge taps. This pattern is only effective for T1 spans that transmit the signal raw. Modulation used in HDSL spans negates the bridgetap patterns’ ability to uncover bridge taps.
- Multipat — This test generates five commonly used test patterns to allow DS1 span testing without having to select each test pattern individually. Patterns are: all ones, 1:7, 2 in 8, 3 in 24, and QRSS.
- T1-DALY and 55 OCTET — Each of these patterns contain fifty-five (55), eight bit octets of data in a sequence that changes rapidly between low and high density. These patterns are used primarily to stress the ALBO and equalizer circuitry but they will also stress timing recovery. 55 OCTET has fifteen (15) consecutive zeroes and can only be used unframed without violating one’s density requirements. For framed signals, the T1-DALY pattern should be used. Both patterns will force a B8ZS code in circuits optioned for B8ZS.
Bit error rate tester[edit]
A bit error rate tester (BERT), also known as a «bit error ratio tester»[4] or bit error rate test solution (BERTs) is electronic test equipment used to test the quality of signal transmission of single components or complete systems.
The main building blocks of a BERT are:
- Pattern generator, which transmits a defined test pattern to the DUT or test system
- Error detector connected to the DUT or test system, to count the errors generated by the DUT or test system
- Clock signal generator to synchronize the pattern generator and the error detector
- Digital communication analyser is optional to display the transmitted or received signal
- Electrical-optical converter and optical-electrical converter for testing optical communication signals
See also[edit]
- Burst error
- Error correction code
- Errored second
- Pseudo bit error ratio
- Viterbi Error Rate
References[edit]
- ^ Jit Lim (14 December 2010). «Is BER the bit error ratio or the bit error rate?». EDN. Retrieved 2015-02-16.
- ^
Digital Communications, John Proakis, Massoud Salehi, McGraw-Hill Education, Nov 6, 2007 - ^
«Keyboards and Covert Channels»
by Gaurav Shah, Andres Molina, and Matt Blaze (2006?) - ^ «Bit Error Rate Testing: BER Test BERT » Electronics Notes». www.electronics-notes.com. Retrieved 2020-04-11.
![]() This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).
This article incorporates public domain material from Federal Standard 1037C. General Services Administration. (in support of MIL-STD-188).
External links[edit]
- QPSK BER for AWGN channel – online experiment
Мониторинг: смысл, цели и универсальные рецепты
Время на прочтение
7 мин
Количество просмотров 5K
В этом посте я расскажу про мониторинг — процесс сбора и анализа информации для принятия обоснованных управленческих решений и достижения показателей назначения. Начну с того, насколько стоит погружаться в мониторинг разным командам, вспомню основные методологии и две важнейшие, на мой взгляд, метрики, с которыми можно покрыть все (или почти все) кейсы.
Мониторинг — одна из трех частей концепции Observability (наблюдаемость), в которой описаны методы получения доступа к информации о внутреннем состоянии системы. Помимо мониторинга, концепция также включает логирование и трассировку.
Мониторинг часто путают с логированием, но эти понятия разделяют не просто так. При логировании мы работаем с логами — потоком событий. А при мониторинге мы собираем, оцифровываем и агрегируем определенную информацию, необходимую для принятия решений. Для полноты картины дадим определение трассировке — это наблюдение за обменом информацией между системами через запросы с помощью ServiceMesh или других инструментов.
Приведу простой пример мониторинга. У нас есть база данных, и пользователи говорят, что она тормозит. Мы смотрим результаты мониторинга базы данных: примерно 1000 запросов в секунду со средним временем ответа в 2 секунды. Хорошо это или плохо, нам подскажут показатели назначения. Представим, что там указано время ответа в 1 секунду при 1000 запросов. Как прийти к этим показателям? Можно добавить аппаратных ресурсов, оптимизировать запросы, сделать шардинг или придумать что-нибудь еще. Выбрать лучший вариант нам тоже поможет мониторинг.
Многие IT-системы внедряются как «черный ящик», поэтому решения по поводу их дальнейшего развития принимают по наитию, по каким-то внутренним ощущениям. Но какой бы ни была IT-система, мониторинг в ней предусмотреть можно. Глобально здесь выделяют три больших направления:
-
Железо. Какие бы облака мы ни использовали, в их основе всегда лежит аппаратная конфигурация, которую стоит мониторить по загрузке и другим важным параметрам.
-
Инфраструктура. Здесь может быть много слоев со своими наборами метрик — например, база данных, Kafka и другие инфраструктурные сервисы. Для полноценного мониторинга нужно учитывать их все.
-
Прикладные сервисы. Мы пишем их сами и метрики для них тоже определяем сами. Они должны быть понятны для всех, а не только для тех, кто их придумал.
Роль мониторинга в командах
Глубже всего в мониторинг стоит погружаться девопсам и SRE. В их задачи входит организация и сбор метрик по железу и инфраструктуре. Уровень прикладных сервисов они так проработать не смогут. Для девопсов это черный ящик, который, максимум, можно обернуть стандартными сервисами: например, если это HTTP-сервис, то при балансировке через nginx к нему можно прикрутить стандартные метрики.
Разработчикам стоит понимать, какие метрики по оборудованию и инфраструктуре необходимы для их задач. Вот, например, накодили вы систему, на нагрузочном тестировании всё было гладко, а в итоге ничего не работает. Но нашелся коллега, который разбирается в метриках БД, и помог раскрутить клубок: оказывается, вы просто забыли оптимизировать запросы в БД, поставить индексы. Поэтому индексы перестали влезать в оперативную память, БД пришлось лезть на диск и делать full-table сканы, а это привело к плачевному итогу. Кроме умения смотреть важно также умение организовать нормальный сбор метрик в своем коде — иначе он превратится в черный ящик из прошлого абзаца.
QA и саппорт должны обязательно понимать метрики прикладных сервисов, а на более глубоких уровнях можно обратиться к инженерам. Это же справедливо и для продакт-менеджеров, и для продакт-оунеров: метрики приклада стоит понимать всем.

Методики мониторинга
Начинающие разработчики, бывает, пасуют перед задачами мониторинга, поскольку не знают, как к ним подойти. Далее я вкратце расскажу о трех стандартных методиках, которые стоит выделить — USE, RED и The Four Golden Signals. Они помогают четко понять, что и как нужно мониторить.
USE расшифровывается как Utilization, Saturation, Error. USE подходит для мониторинга ограниченных ресурсов, например, оборудования. В общих чертах это выглядит так:
-
Utilization — работа под нагрузкой.
-
Saturation — работа под сверхнагрузкой (задачи в очереди).
-
Errors — количество ошибок.
Переложим эти USE-метрики для процессора:
-
Utilization. Здесь нас могут интересовать четыре метрики процессорного времени: idle (сколько процессор не используется), iowait (сколько процессор ждет I/O), system (сколько уходит на систему), user (сколько — на пользовательские задачи). Учтите, что в сумме эта метрика не может превышать общее количество процессорного времени,
-
Saturation. LA (LoadAverage) — с помощью нее мы оцениваем, насколько используется многоядерная система. Если это значение больше, чем количество ядер в конфигурации, то задачи складываются в бэклог.
-
Errors. Cache misses — количество ошибок кэша
Аналогично можно измерять не только аппаратные ресурсы, но и вообще любые ограниченные ресурсы внутри приложения, например, буферы, кэши, пулы соединений. В последнем случае метрики будут выглядеть примерно так:
-
Utilization: сколько соединений выделено, сколько используется.
-
Saturation: количество ожидающих запросов на соединение. Если их 0, то у нас, скорее всего, есть свободные соединения.
-
Errors: сколько раз по разным причинам мы не смогли установить соединение.
RED означает Rate, Errors, Duration. Это совсем другой метод, который лучше всего подходит в кейсах с неограниченными ресурсами, особенно для приложений в режиме request-response:
-
Rate — количество запросов к ресурсу в единицу времени
-
Errors — количество запросов в единицу времени, закончившихся ошибкой
-
Duration — время выполнения запроса (в виде гистограммы)
The Four Golden Signals не складываются в аббревиатуру, чтобы упростить запоминание. Но частично эта методика также пересекается с предыдущими. Четыре золотых сигнала рекомендуют для использования с фронтендом:
-
Latency — задержки. Здесь важно разделять задержи успешных и неудачных запросов; последние могут испортить общую статистику.
-
Traffic — загруженность системы. В веб-сервисах, например, обычно измеряется в количестве HTTP-запросов в секунду.
-
Errors — ошибки. Доля запросов, которые по разным причинам завершились ошибками.
-
Saturation — уровень загруженности системы. Особое внимание здесь стоит уделить ресурсам, которые ограничены. Также, производительность некоторых систем падает еще до достижения полной загрузки, поэтому стоит заранее определить целевой уровень.
Разрезы метрик
Создавая метрики, важно учитывать их разрезы — то, как их можно представить в совокупности для определенных целей. Продолжим на примере методологии RED. В случае с HTTP-запросами можно делать разрезы по определенному пути, методу или ответу.

Выше представлен пример подобного разреза по исключениям, методам, статусам и другим параметрам. Что здесь не учитывается? Время. Много раз я видел, как разработчики пытаются во время мониторинга извлекать метки времени и колдовать над ними: собирать средние значения, строить графики, какие-то медианные и прочее. Делать этого не надо. Для подобных задач предусмотрены гистограммы.
В примере выше время запроса измеряется монотонно растущим счетчиком. Создается куча бакетов с тегом “le” — less than or equal. Внутри бакета работает счетчик запросов, попавших в интервал бакета. Все запросы, занимающие больше 30 секунд, попадают в “le=+inf”. Так мы можем не привязываться ко времени, а сразу распределять запросы. Самостоятельно прописывать эту логику не надо: у Micrometer, например, для этого есть отдельный класс timer, аналогичные инструменты предусмотрены в JS, Grafana и еще много где.
Интерпретируются результаты здесь в виде перцентилей. Например, 99% запросов попадают в одно время, 95% — в другое и так далее. Обычно достаточно четырех перцентилей, чтобы сделать вывод о системе.
Когда вы откроете для себя прелести мониторинга, может возникнуть соблазн насоздавать как можно больше метрик. Увлекаться здесь не стоит, ведь каждую метрику впоследствии предстоит поддерживать и уметь интерпретировать. Для фоновых задач лучше вообще использовать одну метрику с тегами, например, job_rate{job = “send”} и job_rate{job = “receive”}. С помощью тегов здесь можно будет динамически конфигурировать дашборды Grafana.
Великая универсальная метрика
Большую часть задач мониторинга можно решить одной-единственной метрикой — counter (монотонно растущий счетчик). С помощью этого счетчика можно посчитать очень много всего, например Rate — инкремент в секунду. Мы можем запросить его в любом нужном нам разрезе, с разными условиями.

Еще одна замечательная черта этой метрики: ее можно складывать между разными инстансами в кластере. Да и гистограмма времени по сути также представляет собой монотонно растущий счетчик. В целом 90% задач мониторинга можно решить с помощью монотонно растущего счетчика. И тегов, разумеется.
Вторая универсальная метрика
Другая универсальная метрика — это gauge, значение в моменте. Этот вариант больше подходит для бизнес-метрик и значений из БД. Gauge — очень агрегированная метрика, ее трудно делить на теги, поэтому нужно использовать ее очень аккуратно, при одинаковых значениях у всех экземпляров в кластере (например, количества записей в БД).

Gauge решает те 10% задач мониторинга, которые не решает counter. Например, через gauge можно выводить текущий размер какой-либо очереди, а с помощью counter тем временем — количество прочитанных и записанных в этой очереди сообщений. Этого набора будет достаточно для мониторинга любой очереди. Аналогично мы можем мониторить жизненный цикл любых бизнес-процессов.
Что мониторить? Всё!
Бывает, что при мониторинге упускают фоновые процессы, но мониторить их очень важно. HTTP-метрики можно снимать с nginx, а метрики задач придется делать самостоятельно, поскольку они специфичны для приложения. Можно также использовать метрики, которые экспортирует, например, Quartz.
Выделю здесь также этапы исполнения бизнес-процесса. Но если у нас, например, есть 20 типов заявок и 30 статусов, не нужно делать для этого 600 метрик. Просто считайте через инкрементные счетчики переходы заявок между статусами, и далее вы сможете построить любые необходимые отчеты.
Важно мониторить все внешние вызовы — нужно понимать, как долго нам отвечают, на сколько запросов, сколько ошибок получаем. Без этого придется бесконечно анализировать логи. И конечно, не стоит забывать о размерах очередей — их мы разбирали выше.
Настраивая мониторинг, важно не изобретать велосипед. Все необходимое обычно уже доступно бесплатно. Kafka умеет мониториться из коробки. HTTP-сервера и клиенты тоже могут экспортировать метрики — нужно только подключить их и вывести. Та же ситуация и с фоновыми процессами.
Почему это важно?
В среднем любая система пишется 10%, а эксплуатируется 90% времени. Чем больше людей вовлечено в работу с ней, тем больше времени нужно уделить мониторингу. С помощью метрик разработчики смогут быстрее понять, что сломано на проде. А с помощью хороших метрик — еще и почему сломано. Особенно это спасает с внешними интеграциями.
В распределенных системах типа блокчейна наблюдаемость в целом приобретает еще большее значение (помните термин Observability из начала поста?). Здесь у нас имеется много сред, много переменных и вариантов, что может пойти не так. Время поиска проблемы и всех проверок растет экспоненциально. Также мониторинг помогает понять, какие точки в системе хрупкие, оцифровать эту «хрупкость» и показатели производительности системы.