
Качество программного обеспечения.
Проблемы разработки ПО
Наиболее распространёнными проблемами, возникающим в процессе разработки ПО, считают:
· Недостаток прозрачности. В любой момент времени сложно сказать, в каком состоянии находится проект и каков процент его завершения.
Данная проблема возникает при недостаточном планировании структуры (или архитектуры) будущего программного продукта, что чаще всего является следствием отсутствия достаточного финансирования проекта: программа нужна, сколько времени займёт разработка, каковы этапы, можно ли какие-то этапы исключить или сэкономить — следствием этого процесса является то, что этап проектирования сокращается.
· Недостаток контроля. Без точной оценки процесса разработки срываются графики выполнения работ и превышаются установленные бюджеты. Сложно оценить объем выполненной и оставшейся работы.
Данная проблема возникает на этапе, когда проект, завершённый более, чем на половину, продолжает разрабатываться после дополнительного финансирования без оценки степени завершённости проекта.
· Недостаток трассировки.
· Недостаток мониторинга. Невозможность наблюдать ход развития проекта не позволяет контролировать ход разработки в реальном времени. С помощью инструментальных средств менеджеры проектов принимают решения на основе данных, поступающих в реальном времени.
Данная проблема возникает в условиях, когда стоимость обучения менеджмента владению инструментальными средствами, сравнима со стоимостью разработки самой программы.
· Неконтролируемые изменения. У потребителей постоянно возникают новые идеи относительно разрабатываемого программного обеспечения. Влияние изменений может быть существенным для успеха проекта, поэтому важно оценивать предлагаемые изменения и реализовывать только одобренные, контролируя этот процесс с помощью программных средств.
Данная проблема возникает вследствие нежелания конечного потребителя использовать те или иные программные среды. Например, когда при создании клиент-серверной системы потребитель предъявляет требования не только к операционной системе на компьютерах-клиентах, но и на компьютере-сервере.
· Недостаточная надежность. Самый сложный процесс — поиск и исправление ошибок в программах на ЭВМ. Поскольку число ошибок в программах заранее неизвестно, то заранее неизвестна и продолжительность отладки программ и отсутствие гарантий отсутствия ошибок в программах. Следует отметить, что привлечение доказательного подхода к проектированию ПО позволяет обнаружить ошибки в программе до её выполнения. В этом направлении много работали Кнут, Дейкстра и Вирт. Профессор Вирт при разработке Паскаля и Оберона за счет строгости их синтаксиса добился математической доказуемости завершаемости и правильности программ, написанной на этих языках. Особенно крупный вклад в дисциплину программирования внёс Дональд Кнут. Его четырёхтомник «Искусство программирования» является необходимой для каждого серьезного программиста книгой.
Данная проблема возникает при неправильном выборе средств разработки. Например, при попытке создать программу, требующую средств высокого уровня, с помощью средств низкого уровня. Например, при попытке создать средства автоматизации с СУБД на ассемблере. В результате исходный код программы получается слишком сложным и плохо поддающимся структурированию.
· Отсутствие гарантий качества и надежности программ из-за отсутствия гарантий отсутствия ошибок в программах вплоть до формальной сдачи программ заказчикам.
Данная проблема не является проблемой, относящейся исключительно к разработке ПО. Гарантия качества — это проблема выбора поставщика товара (не продукта).
Качество программного обеспечения — характеристика программного обеспечения (ПО) как степени его соответствия требованиям. При этом требования могут трактоваться довольно широко, что порождает целый ряд независимых определений понятия. Чаще всего используется определение ISO 9001, согласно которому качество есть «степень соответствия присущих характеристик требованиям».
Качество исходного кода
Качество кода может определяться различными критериями. Некоторые из них имеют значение только с точки зрения человека. Например, то, как отформатирован текст программы, совершенно не важно для компьютера, но может иметь серьёзное значение для последующего сопровождения. Многие из имеющихся стандартов оформления кода, определяющих специфичные для используемого языка соглашения и задающие ряд правил, улучшающих читаемость кода, имеют своей целью облегчить будущее сопровождение ПО, включающее отладку и обновление. Существуют и другие критерии, определяющие, «хорошо» ли написан код, например, такие, как:
· Структурированность — степень логического разбиения кода на ряд управляемых блоков
· Читаемость кода
· Лёгкость поддержки, тестирования, отладки, исправления ошибок, изменения и портируемости
· Низкая сложность кода
· Низкое использование ресурсов: памяти и процессорного времени
· Корректная обработка исключительных ситуаций
· Низкое количество предупреждений при компиляции и линковке
· Вязкость — свойство программного проекта или среды разработки затруднять внесение изменений предусмотренными в них методами
Методы улучшения качества кода: рефакторинг.
Факторы качества
Фактор качества ПО — это нефункциональное требование к программе, которое обычно не описывается в договоре с заказчиком, но, тем не менее, является желательным требованием, повышающим качество программы.
Некоторые из факторов качества:
· понятность
Назначение ПО должно быть понятным, из самой программы и документации.
· полнота
Все необходимые части программы должны быть представлены и полностью реализованы.
· краткость
Отсутствие лишней, дублирующейся информации. Повторяющиеся части кода должны быть преобразованы в вызов общей процедуры. То же касается и документации.
· портируемость
Лёгкость в адаптации программы к другому окружению: другой архитектуре, платформе, операционной системе или её версии.
· согласованность
По всей программе и в документации должны использоваться одни и те же соглашения, форматы и обозначения.
· сопровождаемость
Насколько сложно изменить программу для удовлетворения новых требований. Это требование также указывает, что программа должна быть хорошо документирована, не слишком запутана, и иметь резерв роста по использованию ресурсов (память, процессор).
· тестируемость
Позволяет ли программа выполнить проверку реализованных в программе методов, классов, поддерживается ли возможность измерения производительности.
· удобство использования
Простота и удобство использования программы. Это требование относится прежде всего к интерфейсу пользователя.
· надёжность
отсутствие отказов и сбоев в работе программ, а также простота исправления дефектов и ошибок:
· структурированность
· эффективность
Насколько рационально программа относится к ресурсам (память, процессор) при выполнении своих задач.
· безопасность
С точки зрения пользователя
Помимо технического взгляда на качество ПО, существует и оценка качества с позиции пользователя. Для этого аспекта качества иногда используют термин «юзабилити» (англ. usability — дословно «возможность использования», «способность быть использованным», «полезность»). Довольно сложно получить оценку юзабилити для заданного программного продукта. Наиболее важные из вопросов, влияющих на оценку:
· Является ли пользовательский интерфейс интуитивно понятным?
· Насколько просто выполнять простые, частые операции?
· Насколько легко выполняются сложные операции?
· Выдаёт ли программа понятные сообщения об ошибках?
· Всегда ли программа ведёт себя так, как ожидается?
· Имеется ли документация и насколько она полна?
· Является ли интерфейс пользователя само-описательным/само-документирующим?
· Всегда ли задержки с ответом программы являются приемлемыми?
Методы улучшения качества кода: рефакторинг.
Рефакторинг — процесс изменения внутренней структуры программы, не затрагивающий её внешнего поведения и имеющий целью облегчить понимание её работы. В основе рефакторинга лежит последовательность небольших эквивалентных (то есть сохраняющих поведение) преобразований. Поскольку каждое преобразование маленькое, программисту легче проследить за его правильностью, и в то же время вся последовательность может привести к существенной перестройке программы и улучшению её согласованности и четкости. Рефакторинг позволяет разрабатывать архитектуру программы постепенно, откладывая проектные решения до тех пор, пока не станет более ясной их необходимость.
Цели рефакторинга
Цель рефакторинга — сделать код программы более легким для понимания; без этого рефакторинг нельзя считать успешным. Рефакторинг следует отличать от оптимизации производительности. Как и рефакторинг, оптимизация обычно не изменяет поведение программы, а только ускоряет ее работу. Но оптимизация часто затрудняет понимание кода, что противоположно рефакторингу. С другой стороны, нужно отличать рефакторинг от реинжиниринга, который осуществляется для расширения функциональности программного обеспечения. Как правило, крупные рефакторинги предваряют реинжиниринг.
Причины применения рефакторинга
Рефакторинг нужно применять постоянно при разработке кода. Основными стимулами его проведения являются следующие задачи:
· Необходимо добавить новую функцию, которая не достаточно укладывается в принятое архитектурное решение
· Необходимо исправить ошибку, причины возникновения которой сразу не ясны
· Трудности в командной разработке обусловлены сложной логикой программы
Какой код должен подвергаться рефакторингу
Во многом при рефакторинге лучше полагаться на интуицию, основанную на опыте. Но можно выделить наиболее очевидные причины, когда код нужно подвергнуть рефакторингу:
· Дублирование кода
· Длинный метод
· Большой класс
· Длинный список параметров
· «Завистливые» функции — это метод, который чрезмерно обращается к данным другого объекта
· Избыточные временные переменные
· Классы данных
· Несгруппированные данные
Рефакторинг кода
В программировании термин рефакторинг означает изменение исходного кода программы без изменения его внешнего поведения. В экстремальном программировании и других гибких методологиях рефакторинг является неотъемлемой частью цикла разработки ПО: разработчики попеременно то создают новые тесты и функциональность, то выполняют рефакторинг кода для улучшения его логичности и прозрачности. Автоматическое юнит-тестирование позволяет убедиться, что рефакторинг не разрушил существующую функциональность. Иногда под рефакторингом неправильно подразумевают коррекцию кода с заранее оговоренными правилами отступа, перевода строк, внесения комментариев и прочими визуально значимыми изменениями, которые никак не отражаются на процессе компиляции, с целью обеспечения лучшей читаемости кода.
Рефакторинг изначально не предназначен для исправления ошибок и добавления новой функциональности, он вообще не меняет поведение программного обеспечения. Но это помогает избежать ошибок и облегчить добавление функциональности. Он выполняется для улучшения понятности кода или изменения его структуры, для удаления «мёртвого кода» — всё это для того, чтобы в будущем код было легче поддерживать и развивать. В частности, добавление в программу нового поведения может оказаться сложным с существующей структурой — в этом случае разработчик может выполнить необходимый рефакторинг, а уже затем добавить новую функциональность.
Это может быть перемещение поля из одного класса в другой, вынесение фрагмента кода из метода и превращение его в самостоятельный метод или даже перемещение кода по иерархии классов. Каждый отдельный шаг может показаться элементарным, но совокупный эффект таких малых изменений в состоянии радикально улучшить проект или даже предотвратить распад плохо спроектированной программы.
Методы рефакторинга
Наиболее употребимые методы рефакторинга:
· Изменение сигнатуры метода (Change Method Signature)
· Инкапсуляция поля (Encapsulate Field)
· Выделение класса (Extract Class)
· Выделение интерфейса (Extract Interface)
· Выделение локальной переменной (Extract Local Variable)
· Выделение метода (Extract Method)
· Генерализация типа (Generalize Type)
· Встраивание (Inline)
· Введение фабрики (Introduce Factory)
· Введение параметра (Introduce Parameter)
· Подъём поля/метода (Pull Up)
· Спуск поля/метода (Push Down)
· Замена условного оператора полиморфизмом (Replace Conditional with Polymorphism)
Изменение сигнатуры метода (Change Method Signature)
Заключается в добавлении, изменении или удалении параметра метода. Изменив сигнатуру метода, необходимо скорректировать обращения к нему в коде всех клиентов. Это изменение может затронуть внешний интерфейс программы, кроме того, не всегда разработчику, изменяющему интерфейс, доступны все клиенты этого интерфейса, поэтому может потребоваться та или иная форма регистрации изменений интерфейса для последующей передачи их вместе с новой версией программы.
Инкапсуляция поля (Encapsulate field)
В случае, если у класса имеется открытое поле, необходимо сделать его закрытым и обеспечить методы доступа. После «Инкапсуляции поля» часто применяется «Перемещение метода».
Выделение метода (Extract Method)
Заключается в выделении из длинного и/или требующего комментариев кода отдельных фрагментов и преобразовании их в отдельные методы, с подстановкой подходящих вызовов в местах использования. В этом случае действует правило: если фрагмент кода требует комментария о том, что он делает, то он должен быть выделен в отдельный метод. Также правило: один метод не должен занимать более чем один экран (25-50 строк, в зависимости от условий редактирования), в противном случае некоторые его фрагменты имеют самостоятельную ценность и подлежат выделению. Из анализа связей выделяемого фрагмента с окружающим контекстом делается вывод о перечне параметров нового метода и его локальных переменных.
Перемещение метода (Move Method)
Применяется по отношению к методу, который чаще обращается к другому классу, чем к тому, в котором сам располагается.
Замена условного оператора полиморфизмом (Replace Conditional with Polymorphism)
Условный оператор с несколькими ветвями заменяется вызовом полиморфного метода некоторого базового класса, имеющего подклассы для каждой ветви исходного оператора. Выбор ветви осуществляется неявно, в зависимости от того, экземпляру какого из подклассов оказался адресован вызов.
Основные принципы:
1. вначале следует создать базовый класс и нужное число подклассов
2. в некоторых случаях следует провести оптимизацию условного оператора путем «Выделения метода»
3. возможно использование «Перемещения метода», чтобы поместить условный оператор в вершину иерархии наследования
4. выбрав один из подклассов, нужно конкретизировать в нём полиморфный метод базового класса и переместить в него тело соответствующей ветви условного оператора.
5. повторить предыдущее действие для каждой ветви условного оператора
6. заменить весь условный оператор вызовом полиморфного метода базового класса
Проблемы, возникающие при проведении рефакторинга
· проблемы, связанные с базами данных
· проблемы изменения интерфейсов
· трудности при изменении дизайна
Реинжиниринг программного обеспечения.
Реинжиниринг программного обеспечения — процесс создания новой функциональности или устранения ошибок, путём революционного изменения, но используя уже имеющееся в эксплуатации программное обеспечение. Процесс реинжиниринга описан Chikofsky и Кроссом в их труде 1990 года, как «The examination and alteration of a system to reconstitute it in a new form». Выражаясь менее формально, реинжиниринг является изменением системы программного обеспечения после проведения обратного инжиниринга.
Сложность реинжиниринга
Как правило, утверждается, что «легче разработать новый программный продукт». Это связано со следующими проблемами:
1. Обычному программисту сложно разобраться в чужом исходном коде
2. Реинжиниринг чаще всего дороже разработки нового программного обеспечения, т.к. требуется убрать ограничения предыдущих версий, но при этом оставить совместимость с предыдущими версиями
3. Реинжиниринг не может сделать программист низкой и средней квалификации. Даже профессионалы часто не могут качественно реализовать его. Поэтому требуется работа программистов с большим опытом переделки программ и знанием различных технологий.
В то же время, если изначально программа обладала строгой и ясной архитектурой, то провести реинжиниринг будет на порядок проще. Поэтому при проектировании как правило анализируется, что выгоднее провести реинжиниринг или разработать программный продукт «с нуля».
Тестирование программного обеспечения.
Тестирование программного обеспечения — процесс исследования программного обеспечения (ПО) с целью получения информации о качестве продукта.
Введение
Существующие на сегодняшний день методы тестирования ПО не позволяют однозначно и полностью выявить все дефекты и установить корректность функционирования анализируемой программы, поэтому все существующие методы тестирования действуют в рамках формального процесса проверки исследуемого или разрабатываемого ПО.
Такой процесс формальной проверки или верификации может доказать, что дефекты отсутствуют с точки зрения используемого метода. (То есть нет никакой возможности точно установить или гарантировать отсутствие дефектов в программном продукте с учётом человеческого фактора, присутствующего на всех этапах жизненного цикла ПО).
Существует множество подходов к решению задачи тестирования и верификации ПО, но эффективное тестирование сложных программных продуктов — это процесс в высшей степени творческий, не сводящийся к следованию строгим и чётким процедурам или созданию таковых.
С точки зрения ISO 9126, Качество (программных средств) можно определить как совокупную характеристику исследуемого ПО с учётом следующих составляющих:
· Надёжность
· Сопровождаемость
· Практичность
· Эффективность
· Мобильность
· Функциональность
Более полный список атрибутов и критериев можно найти в стандарте ISO 9126 Международной организации по стандартизации. Состав и содержание документации, сопутствующей процессу тестирования, определяется стандартом IEEE 829-1998 Standard for Software Test Documentation.
История развития тестирования программного обеспечения
Первые программные системы разрабатывались в рамках программ научных исследований или программ для нужд министерств обороны. Тестирование таких продуктов проводилось строго формализованно с записью всех тестовых процедур, тестовых данных, полученных результатов. Тестирование выделялось в отдельный процесс, который начинался после завершения кодирования, но при этом, как правило, выполнялось тем же персоналом.
В 1960-х много внимания уделялось «исчерпывающему» тестированию, которое должно проводиться с использованием всех путей в коде или всех возможных входных данных. Было отмечено, что в этих условиях полное тестирование ПО невозможно, потому что, во-первых, количество возможных входных данных очень велико, во-вторых, существует множество путей, в-третьих, сложно найти проблемы в архитектуре и спецификациях. По этим причинам «исчерпывающее» тестирование было отклонено и признано теоретически невозможным.
В начале 1970-х тестирование ПО обозначалось как «процесс, направленный на демонстрацию корректности продукта» или как «деятельность по подтверждению правильности работы ПО». В зарождавшейся программной инженерии верификация ПО значилась как «доказательство правильности». Хотя концепция была теоретически перспективной, на практике она требовала много времени и была недостаточно всеобъемлющей. Было решено, что доказательство правильности — неэффективный метод тестирования ПО. Однако, в некоторых случаях демонстрация правильной работы используется и в наши дни, например, приемо-сдаточные испытания. Во второй половине 1970-х тестирование представлялось как выполнение программы с намерением найти ошибки, а не доказать, что она работает. Успешный тест — это тест, который обнаруживает ранее неизвестные проблемы. Данный подход прямо противоположен предыдущему. Указанные два определения представляют собой «парадокс тестирования», в основе которого лежат два противоположных утверждения: с одной стороны, тестирование позволяет убедиться, что продукт работает хорошо, а с другой — выявляет ошибки в ПО, показывая, что продукт не работает. Вторая цель тестирования является более продуктивной с точки зрения улучшения качества, так как не позволяет игнорировать недостатки ПО.
В 1980-х тестирование расширилось таким понятием, как предупреждение дефектов. Проектирование тестов — наиболее эффективный из известных методов предупреждения ошибок. В это же время стали высказываться мысли, что необходима методология тестирования, в частности, что тестирование должно включать проверки на всем протяжении цикла разработки, и это должен быть управляемый процесс. В ходе тестирования надо проверить не только собранную программу, но и требования, код, архитектуру, сами тесты. «Традиционное» тестирование, существовавшее до начала 1980-х, относилось только к скомпилированной, готовой системе (сейчас это обычно называется системное тестирование), но в дальнейшем тестировщики стали вовлекаться во все аспекты жизненного цикла разработки. Это позволяло раньше находить проблемы в требованиях и архитектуре и тем самым сокращать сроки и бюджет разработки. В середине 1980-х появились первые инструменты для автоматизированного тестирования. Предполагалось, что компьютер сможет выполнить больше тестов, чем человек, и сделает это более надежно. Поначалу эти инструменты были крайне простыми и не имели возможности написания сценариев на скриптовых языках.
В начале 1990-х в понятие «тестирование» стали включать планирование, проектирование, создание, поддержку и выполнение тестов и тестовых окружений, и это означало переход от тестирования к обеспечению качества, охватывающего весь цикл разработки ПО. В это время начинают появляться различные программные инструменты для поддержки процесса тестирования: более продвинутые среды для автоматизации с возможностью создания скриптов и генерации отчетов, системы управления тестами, ПО для проведения нагрузочного тестирования. В середине 1990-х с развитием интернета и разработкой большого количества веб-приложений особую популярность стало получать «гибкое тестирование» (по аналогии с гибкими методологиями программирования).
В 2000-х появилось еще более широкое определение тестирования, когда в него было добавлено понятие «оптимизация бизнес-технологий» (en:business technology optimization, BTO). BTO направляет развитие информационных технологий в соответствии с целями бизнеса. Основной подход заключается в оценке и максимизации значимости всех этапов жизненного цикла разработки ПО для достижения необходимого уровня качества, производительности, доступности.
Тестирование программного обеспечения
Существует несколько признаков, по которым принято производить классификацию видов тестирования. Обычно выделяют следующие:
По объекту тестирования:
· Функциональное тестирование (functional testing)
· Нагрузочное тестирование
· Тестирование производительности (perfomance/stress testing)
· Тестирование стабильности (stability/load testing)
· Тестирование удобства использования (usability testing)
· Тестирование интерфейса пользователя (UI testing)
· Тестирование безопасности (security testing)
· Тестирование локализации (localization testing)
· Тестирование совместимости (compatibility testing)
По знанию системы:
· Тестирование чёрного ящика (black box)
· Тестирование белого ящика (white box)
· Тестирование серого ящика (gray box)
По степени автоматизированности:
· Ручное тестирование (manual testing)
· Автоматизированное тестирование (automated testing)
· Полуавтоматизированное тестирование (semiautomated testing)
По степени изолированности компонентов:
· Компонентное (модульное) тестирование (component/unit testing)
· Интеграционное тестирование (integration testing)
· Системное тестирование (system/end-to-end testing)
По времени проведения тестирования:
· Альфа тестирование (alpha testing)
· Тестирование при приёмке (smoke testing)
· Тестирование новых функциональностей (new feature testing)
· Регрессионное тестирование (regression testing)
· Тестирование при сдаче (acceptance testing)
· Бета тестирование (beta testing)
По признаку позитивности сценариев:
· Позитивное тестирование (positive testing)
· Негативное тестирование (negative testing)
По степени подготовленности к тестированию:
· Тестирование по документации (formal testing)
· Эд Хок (интуитивное) тестирование (ad hoc testing)
Уровни тестирования
Модульное тестирование (юнит-тестирование) — тестируется минимально возможный для тестирования компонент, например, отдельный класс или функция. Часто модульное тестирование осуществляется разработчиками ПО.
Интеграционное тестирование — тестируются интерфейсы между компонентами, подсистемами. При наличии резерва времени на данной стадии тестирование ведётся итерационно, с постепенным подключением последующих подсистем.
Системное тестирование — тестируется интегрированная система на её соответствие требованиям.
Альфа-тестирование — имитация реальной работы с системой штатными разработчиками, либо реальная работа с системой потенциальными пользователями/заказчиком. Чаще всего альфа-тестирование проводится на ранней стадии разработки продукта, но в некоторых случаях может применяться для законченного продукта в качестве внутреннего приёмочного тестирования. Иногда альфа-тестирование выполняется под отладчиком или с использованием окружения, которое помогает быстро выявлять найденные ошибки. Обнаруженные ошибки могут быть переданы тестировщикам для дополнительного исследования в окружении, подобном тому, в котором будет использоваться ПО.
Бета-тестирование — в некоторых случаях выполняется распространение версии с ограничениями (по функциональности или времени работы) для некоторой группы лиц, с тем чтобы убедиться, что продукт содержит достаточно мало ошибок. Иногда бета-тестирование выполняется для того, чтобы получить обратную связь о продукте от его будущих пользователей.
Часто для свободного/открытого ПО стадия Альфа-тестирования характеризует функциональное наполнение кода, а Бета тестирования — стадию исправления ошибок. При этом как правило на каждом этапе разработки промежуточные результаты работы доступны конечным пользователям.
Тестирование «белого ящика» и «чёрного ящика»
В терминологии профессионалов тестирования (программного и некоторого аппаратного обеспечения), фразы «тестирование белого ящика» и «тестирование чёрного ящика» относятся к тому, имеет ли разработчик тестов доступ к исходному коду тестируемого ПО, или же тестирование выполняется через пользовательский интерфейс либо прикладной программный интерфейс, предоставленный тестируемым модулем.
При тестировании белого ящика (англ. white-box testing, также говорят — прозрачного ящика), разработчик теста имеет доступ к исходному коду программ и может писать код, который связан с библиотеками тестируемого ПО. Это типично для юнит-тестирования (англ. unit testing), при котором тестируются только отдельные части системы. Оно обеспечивает то, что компоненты конструкции — работоспособны и устойчивы, до определённой степени. При тестировании белого ящика используются метрики покрытия кода.
При тестировании чёрного ящика, тестировщик имеет доступ к ПО только через те же интерфейсы, что и заказчик или пользователь, либо через внешние интерфейсы, позволяющие другому компьютеру либо другому процессу подключиться к системе для тестирования. Например, тестирующий модуль может виртуально нажимать клавиши или кнопки мыши в тестируемой программе с помощью механизма взаимодействия процессов, с уверенностью в том, все ли идёт правильно, что эти события вызывают тот же отклик, что и реальные нажатия клавиш и кнопок мыши. Как правило, тестирование чёрного ящика ведётся с использованием спецификаций или иных документов, описывающих требования к системе. Как правило, в данном виде тестирования критерий покрытия складывается из покрытия структуры входных данных, покрытия требований и покрытия модели (в тестировании на основе моделей).
Если «альфа-» и «бета-тестирование» относятся к стадиям до выпуска продукта (а также, неявно, к объёму тестирующего сообщества и ограничениям на методы тестирования), тестирование «белого ящика» и «чёрного ящика» имеет отношение к способам, которыми тестировщик достигает цели.
Бета-тестирование в целом ограничено техникой чёрного ящика (хотя постоянная часть тестировщиков обычно продолжает тестирование белого ящика параллельно бета-тестированию). Таким образом, термин «бета-тестирование» может указывать на состояние программы (ближе к выпуску чем «альфа»), или может указывать на некоторую группу тестировщиков и процесс, выполняемый этой группой. Итак, тестировщик может продолжать работу по тестированию белого ящика, хотя ПО уже «в бете» (стадия), но в этом случае он не является частью «бета-тестирования» (группы/процесса).
Статическое и динамическое тестирование
Описанные выше техники — тестирование белого ящика и тестирование чёрного ящика — предполагают, что код исполняется, и разница состоит лишь в той информации, которой владеет тестировщик. В обоих случаях это динамическое тестирование.
При статическом тестировании программный код не выполняется — анализ программы происходит на основе исходного кода, который вычитывается вручную, либо анализируется специальными инструментами. В некоторых случаях, анализируется не исходный, а промежуточный код (такой как байт-код или код на MSIL).
Также к статическому тестированию относят тестирование требований, спецификаций, документации.
Регрессионное тестирование
Регрессио́нное тести́рование (англ. regression testing, от лат. regressio — движение назад) — собирательное название для всех видов тестирования программного обеспечения, направленных на обнаружение ошибок в уже протестированных участках исходного кода. Такие ошибки — когда после внесения изменений в программу перестает работать то, что должно было продолжать работать, — называют регрессионными ошибками (англ. regression bugs).
Обычно используемые методы регрессионного тестирования включают повторные прогоны предыдущих тестов, а также проверки, не попали ли регрессионные ошибки в очередную версию в результате слияния кода.
Из опыта разработки ПО известно, что повторное появление одних и тех же ошибок — случай достаточно частый. Иногда это происходит из-за слабой техники управления версиями или по причине человеческой ошибки при работе с системой управления версиями. Но настолько же часто решение проблемы бывает «недолго живущим»: после следующего изменения в программе решение перестаёт работать. И наконец, при переписывании какой-либо части кода часто всплывают те же ошибки, что были в предыдущей реализации.
Поэтому считается хорошей практикой при исправлении ошибки создать тест на неё и регулярно прогонять его при последующих изменениях программы. Хотя регрессионное тестирование может быть выполнено и вручную, но чаще всего это делается с помощью специализированных программ, позволяющих выполнять все регрессионные тесты автоматически. В некоторых проектах даже используются инструменты для автоматического прогона регрессионных тестов через заданный интервал времени. Обычно это выполняется после каждой удачной компиляции (в небольших проектах) либо каждую ночь или каждую неделю.
Регрессионное тестирование является неотъемлемой частью экстремального программирования. В этой методологии проектная документация заменяется на расширяемое, повторяемое и автоматизированное тестирование всего программного пакета на каждой стадии цикла разработки программного обеспечения.
Регрессионное тестирование может быть использовано не только для проверки корректности программы, часто оно также используется для оценки качества полученного результата. Так, при разработке компилятора, при прогоне регрессионных тестов рассматривается размер получаемого кода, скорость его выполнения и время компиляции каждого из тестовых примеров.
Цитата
«Фундаментальная проблема при сопровождении программ состоит в том, что исправление одной ошибки с большой вероятностью (20-50%) влечет появление новой. Поэтому весь процесс идет по принципу «два шага вперед, шаг назад».
Почему не удается устранять ошибки более аккуратно? Во-первых, даже скрытый дефект проявляет себя как отказ в каком-то одном месте. В действительности же он часто имеет разветвления по всей системе, обычно неочевидные. Всякая попытка исправить его минимальными усилиями приведет к исправлению локального и очевидного, но если только структура не является очень ясной или документация очень хорошей, отдаленные последствия этого исправления останутся незамеченными. Во-вторых, ошибки обычно исправляет не автор программы, а зачастую младший программист или стажер.
Вследствие внесения новых ошибок сопровождение программы требует значительно больше системной отладки на каждый оператор, чем при любом другом виде программирования. Теоретически, после каждого исправления нужно прогнать весь набор контрольных примеров, по которым система проверялась раньше, чтобы убедиться, что она каким-нибудь непонятным образом не повредилась. На практике такое возвратное (регрессионное) тестирование действительно должно приближаться к этому теоретическому идеалу, и оно очень дорого стоит.»
После внесения изменений в очередную версию программы, регрессионные тесты подтверждают, что сделанные изменения не повлияли на работоспособность остальной функциональности приложения. Регрессионное тестирование может выполняться как вручную, так и средствами автоматизации тестирования.
Тестовые скрипты
Тестировщики используют тестовые скрипты на разных уровнях: как в модульном, так и в интеграционном и системном тестировании. Тестовые скрипты, как правило, пишутся для проверки компонентов, в которых наиболее высока вероятность появления отказов или вовремя не найденная ошибка может быть дорогостоящей.
Покрытие кода
Покрытие кода — мера, используемая при тестировании программного обеспечения. Она показывает процент, насколько исходный код программы был протестирован. Техника покрытия кода была одной из первых методик, изобретённых для систематического тестирования ПО. Первое упоминание покрытия кода в публикациях появилось в 1963 году.
Критерии
Существует несколько различных способов измерения покрытия, основные из них:
· Покрытие операторов — каждая ли строка исходного кода была выполнена и протестирована?
· Покрытие условий — каждая ли точка решения (вычисления истинно ли или ложно выражение) была выполнена и протестирована?
· Покрытие путей — все ли возможные пути через заданную часть кода были выполнены и протестированы?
· Покрытие функций — каждая ли функция программы была выполнена
· Покрытие вход/выход — все ли вызовы функций и возвраты из них были выполнены
Для программ с особыми требованиями к безопасности часто требуется продемонстрировать, что тестами достигается 100 % покрытие для одного из критериев. Некоторые из приведённых критериев покрытия связаны между собой; например, покрытие путей включает в себя и покрытие условий и покрытие операторов. Покрытие операторов не включает покрытие условий, как показывает этот код на Си:
printf(«this is «);
if (bar < 1)
{
printf(«not «);
}
printf(«a positive integer»);
Если здесь bar = −1, то покрытие операторов будет полным, а покрытие условий — нет, так как случай несоблюдения условия в операторе if — не покрыт. Полное покрытие путей обычно невозможно. Фрагмент кода, имеющий n условий содержит 2n путей; конструкция цикла порождает бесконечное количество путей. Некоторые пути в программе могут быть не достигнуты из-за того, что в тестовых данных отсутствовали такие, которые могли привести к выполнению этих путей. Не существует универсального алгоритма, который решал бы проблему недостижимых путей (этот алгоритм можно было бы использовать для решения проблемы останова). На практике для достижения покрытия путей используется следующий подход: выделяются классы путей (например, к одному классу можно отнести пути отличающиеся только количеством итераций в одном и том же цикле), 100 % покрытие достигнуто, если покрыты все классы путей (класс считается покрытым, если покрыт хотя бы один путь из него).
Покрытие кода, по своей сути, является тестированием методом белого ящика. Тестируемое ПО собирается со специальными настройками или библиотеками и/или запускается в особом окружении, в результате чего для каждой используемой (выполняемой) функции программы определяется местонахождение этой функции в исходном коде. Этот процесс позволяет разработчикам и специалистам по обеспечению качества определить части системы, которые, при нормальной работе, используются очень редко или никогда не используются (такие как код обработки ошибок и т.п.). Это позволяет сориентировать тестировщиков на тестирование наиболее важных режимов.
Практическое применение
Обычно исходный код снабжается тестами, которые регулярно выполняются. Полученный отчёт анализируется с целью выявить невыполнявшиеся области кода, набор тестов обновляется, пишутся тесты для непокрытых областей. Цель состоит в том, чтобы получить набор тестов для регрессионного тестирования, тщательно проверяющих весь исходный код.
Степень покрытия кода обычно выражают в виде процента. Например, «мы протестировали 67 % кода». Смысл этой фразы зависит от того какой критерий был использован. Например, 67 % покрытия путей — это лучший результат чем 67 % покрытия операторов. Вопрос о связи значения покрытия кода и качеством тестового набора ещё до конца не решён.
Тестировщики могут использовать результаты теста покрытия кода для разработки тестов или тестовых данных, которые расширят покрытие кода на важные функции.
Как правило, инструменты и библиотеки, используемые для получения покрытия кода, требуют значительных затрат производительности и/или памяти, недопустимых при нормальном функционировании ПО. Поэтому они могут использоваться только в лабораторных условиях.
Метрика программного обеспечения
Метрика программного обеспечения (англ. software metric) — это мера, позволяющая получить численное значение некоторого свойства программного обеспечения или его спецификаций.
Поскольку количественные методы хорошо зарекомендовали себя в других областях, многие теоретики и практики информатики пытались перенести данный подход и в разработку программного обеспечения. Как сказал Том ДеМарко, «вы не можете контролировать то, что не можете измерить».
Метрики
Набор используемых метрик включает:
· порядок роста (имеется в виду анализ алгоритмов в терминах асимптотического анализа и O-нотации)
· количество строк кода
· цикломатическая сложность
· анализ функциональных точек
· количество ошибок на 1000 строк кода
· покрытие кода
· покрытие требований
· количество классов и интерфейсов
· метрики программного пакета от Роберта Сесиль Мартина
· связность
Критика
Потенциальные недостатки подхода, на которые нацелена критика:
Неэтичность: Утверждается, что неэтично сводить оценку работы человека к нескольким числовым параметрам и по ним судить о производительности. Менеджер может назначить наиболее талантливых программистов на сложнейший участок работы; это означает, что разработка этого участка займёт наибольшее время и породит наибольшее количество ошибок, из-за сложности задачи. Не зная об этих трудностях, другой менеджер по полученным показателям может решить, что программист сделал свою работу плохо.
Замещение «управления людьми» на «управление цифрами», которое не учитывает опыт сотрудников и их другие качества
Искажение: Процесс измерения может быть искажён за счёт того, что сотрудники знают об измеряемых показателях и стремятся оптимизировать эти показатели, а не свою работу. Например, если количество строк исходного кода является важным показателем, то программисты будут стремиться писать как можно больше строк и не будут использовать способы упрощения кода, сокращающие количество строк.
Неточность: Нет метрик, которые были бы одновременно и значимы и достаточно точны. Количество строк кода — это просто количество строк, этот показатель не даёт представление о сложности решаемой проблемы. Анализ функциональных точек был разработан с целью лучшего измерения сложности кода и спецификации, но он использует личные оценки измеряющего, поэтому разные люди получат разные результаты.
Обратная семантическая трассировка
Обратная семантическая трассировка (ОСТ) — метод контроля качества, который позволяет обнаруживать ошибки, утечку или искажение информации при создании проектных артефактов: документации, кода и т. д. Метод наиболее ценен на ранних стадиях разработки программного обеспечения, при создании требований и архитектуры будущей системы при отсутствии исполняемого кода для тестирования. ОСТ является частью P-Modeling Framework.
Вступление
Каждый этап процесса разработки программного обеспечения можно рассматривать как серию «переводов» с одного языка на другой. В самом начале проекта заказчик рассказывает команде свои требования к программе на естественном языке: русском, английском и т. д. Эти пожелания клиента иногда могут оказаться неполными, неясными или даже противоречащими друг другу. Первым шагом в цепочке «переводов» является определение и анализ пожеланий заказчика, их преобразование в формальный список требований для будущей системы. Затем требования становятся исходным материалом для архитектуры и проекта системы. Так шаг за шагом команда создает мегабайты кода, написанного на весьма формальном языке программирования. При переводе всегда существует риск ошибки, неправильного толкования или потери информации. Иногда это не имеет значения, но иногда даже небольшой дефект в спецификации требований может вызвать серьезные переделки системы на поздних стадиях проекта.
Чаще всего обратная семантическая трассировка применяется для:
· Проверки UML моделей;
· Проверки изменений в требованиях;
· Проверки исправлений ошибок в коде;
· Быстрой адаптации нового человека в команде (новому члену команды дают задание провести ОСТ сессию — он знакомится с программой, документацией, кодом и т. д. гораздо быстрее, так как ему необходимо не просто прочитать материал, но и проанализировать его).
·
Роли
Основными действующими лицами в процессе обратной семантической трассировки являются:
· авторы артефактов (как исходного, так и результирующего);
· реверс-инженеры;
· группа экспертов для оценки качества артефакта;
· менеджер проекта.
Процесс
Определить все артефакты проекта и их взаимосвязи
Обратная семантическая трассировка, как метод контроля качества, может быть применена к любому артефакту проекта, даже к любой части артефакта, вплоть до одной строки документа или кода. Однако очевидно, что выполнение такой процедуры для всех документов и изменений может создать ненужную нагрузку для проектной команды. Чтобы этого избежать, применение ОСТ должно быть обосновано. Какой объем ОСТ нужен для обеспечения качества — решает компания (в соответствие со стандартами качества и процессами, принятым в компании) и проджект менеджер (исходя из специфики конкретного проекта).
В общем случае, количество ОСТ сессий определяется важностью артефактов для проекта и уровнем контроля качества для этого артефакта (тестирование, верификация, рецензии и т. д.)
Количество ОСТ сессий определяется на этапе планирования проекта.
Прежде всего менеджер проекта создает список всех артефактов, которые будут созданы в процессе работы над проектом. Этот список может быть представлен в виде дерева, отображающего связи и отношения артефактов между собой. Артефакты могут быть представлены как в единственном экземпляре (например, документ описывающий ви́дение проекта), так и во многих экземплярах (например, задачи, дефекты или риски). Этот список может меняться в течение проекта, однако принцип принятия решения об ОСТ будет тем же.
Расставить приоритеты для артефактов
Следующий шаг — анализ важности артефактов и уровня контроля качества, который применяется по отношению к артефакту. Важность документа — это степень его влияния на успех проекта и качество финального продукта. Важность условно можно измерить по следующей шкале:
Очень высокая(1): качество артефакта очень важно для общего качества продукта и влияет на успех проекта в целом. Примеры таких артефактов: спецификация требований, архитектура системы, исправления критических ошибок в системе, риски с очень высокой вероятностью.
Высокая(2): артефакт имеет влияние на качество финального продукта. Например: тест кейсы, требования к интерфейсу и юзабилити, дефекты с высоким приоритетом, риски с высокой вероятностью.
Средняя(3): артефакт имеет среднее или косвенное влияние на качество конечного продукта. Например: план проекта, дефекты со средним приоритетом.
Низкая(4): артефакт имеет незначительное влияние на качество разрабатываемого программного продукта. Например: задачи программистов, косметические дефекты, риски с низкой вероятностью.
Уровень контроля качества для артефакта определяется в соответствии с объемом работ по обеспечению качества артефакта, вероятностью возникновения недоразумений и искажений информации в процессе его создания.
Низкий(1): Не предусмотрены тестирование или проверки (рецензии), недоразумения и потери информации очень вероятны, над артефактом работает распределенная команда, существует языковой барьер и т. д.
Средний(2): Рецензия не предусмотрена, над артефактом работает нераспределенная команда.
Достаточный(3): Предусмотрено рецензирование или парное программирование, над артефактом работает нераспределенная команда.
Отличный(4): Для артефакта предусмотрены парное программирование, верификация иили тестирование, автоматическое или юнит тестирование. Есть инструменты для создания или тестирования артефактов.
Определить, кто будет проводить ОСТ
Успех ОСТ сессий во многом зависит от правильного выбора реверс-инженеров — они должны обладать достаточной компетенцией, чтобы суметь восстановить родительский артефакт. Но в то же время, реверс инженеры не должны знать деталей проекта, чтобы избежать предвзятости при восстановлении информации. В идеале, это должны быть инженеры из другого проекта, использующего сходные технологии или процессы.
Провести ОСТ
Процесс обратной семантической трассировки начинается, когда решение о ее необходимости принято и назначены ответственные инженеры для ее выполнения.
Менеджер проекта определяет какие документы будут являться входными для данной сессии ОСТ. Например, это может быть дополнительная информация, которая позволит реверс-инжерену восстановить родительский артефакт более полно. Рекомендуется также дать информацию о размере восстанавливаемого артефакта, чтобы помочь реверс-инженерам определить объем работы: это может быть одна-две строки или несколько страниц текста. И хотя восстановленный текст может не совпадать с исходным по количеству слов, эти величины должны быть соизмеримы.
После этого реверс-инженеры берут артефакт и восстанавливают из него исходный текст. ОСТ сессия сама по себе занимает около часа (для 1 страницы текста, примерно 750 слов)
Оценить качество артефактов
Чтобы завершить ОСТ сессию, необходимо сравнить исходный и восстановленный текст и оценить качество артефактов. Решение о переработке, доработке и исправлении артефактов делается на основании этой оценки.
Для оценки формируется группа экспертов. Эксперты должны иметь представление о предметной области проекта и иметь достаточно опыта, чтобы оценить качество артефакта. Например, аналитик может быть экспертом для сравнения и оценки документа описывающего видение проекта и видения, восстановленного из требований и сценариев.
Критерии оценки и шкала:
1. Восстановленный и оригинальный тексты имеют очень большие смысловые различия и потери критической информации.
2. Восстановленный и оригинальный тексты имеют смысловые различия, потерю или искажение важной информации.
3. Восстановленный и оригинальный тексты имеют смысловые различия, незначительную потерю или искажение информации.
4. Восстановленный и оригинальный тексты близки по смыслу, незначительное искажение информации.
5. Восстановленный и оригинальный тексты очень близки, информация не потеряна (искажена).
Каждый эксперт даёт свою оценку, затем вычисляется средняя оценка (среднее арифметическое). В зависимости от этой оценки, проджект менеджер принимает решение о исправлении артефактов, переделке их или доработке.
Если оценка ОСТ находится между 1 и 2 — качество артефакта очень низкое. Рекомендуется переработать не только тестируемый артефакт, но и родительский, для того чтобы внести однозначность в представленную там информацию. В этом случае может потребоваться несколько сессий ОСТ после доработки артефактов.
Для артефактов с оценкой от 2 до 3 требуется доработка оцениваемого артефакта и рекомендуется ревью родительского артефакта для того, чтобы понять, что привело к потере информации. Дополнительные ОСТ сессии не требуются.
Если средняя оценка от 3 до 4, требуется доработка тестируемого артефакта, чтобы исправить неточности.
Если оценка больше 4, это подразумевает что артефакт хорошего качества, доработка не предполагается.
Естественно, финальное решение принимает менеджер проекта, и оно должно учитывать причины расхождений в исходном и восстановленном текстах.
Программный код и его метрики
Время на прочтение
19 мин
Количество просмотров 119K
Одной из тем в программировании, к которым интерес периодически то появляется, то пропадает, является вопрос метрик кода программного обеспечения. В крупных программных средах время от времени появляются механизмы подсчета различных метрик. Волнообразный интерес к теме так выглядит потому, что до сих пор в метриках не придумано главного — что с ними делать. То есть даже если какой-то инструмент позволяет хорошо подсчитать некоторые метрики, то что с этим делать дальше зачастую непонятно. Конечно, метрики — это и контроль качества кода (не пишем большие и сложные функции), и «производительность» (в кавычках) программистов, и скорость развития проекта. Эта статья — обзор наиболее известных метрик кода программного обеспечения.
Введение
В статье приведен обзор 7 классов метрик и более 50 их представителей.
Будет представлен широкий спектр метрик программного обеспечения. Естественно, все существующие метрики приводить не целесообразно, большинство из них никогда не применяется на практике либо из-за невозможности дальнейшего использования результатов, либо из-за невозможности автоматизации измерений, либо из-за узкой специализации данных метрик, однако существуют метрики, которые применяются достаточно часто, и их обзор как раз будет приведен ниже.
В общем случае применение метрик позволяет руководителям проектов и предприятий изучить сложность разработанного или даже разрабатываемого проекта, оценить объем работ, стилистику разрабатываемой программы и усилия, потраченные каждым разработчиком для реализации того или иного решения. Однако метрики могут служить лишь рекомендательными характеристиками, ими нельзя полностью руководствоваться, так как при разработке ПО программисты, стремясь минимизировать или максимизировать ту или иную меру для своей программы, могут прибегать к хитростям вплоть до снижения эффективности работы программы. Кроме того, если, к примеру, программист написал малое количество строк кода или внес небольшое число структурных изменений, это вовсе не значит, что он ничего не делал, а может означать, что дефект программы было очень сложно отыскать. Последняя проблема, однако, частично может быть решена при использовании метрик сложности, т.к. в более сложной программе ошибку найти сложнее.
1. Количественные метрики
Прежде всего, следует рассмотреть количественные характеристики исходного кода программ (в виду их простоты). Самой элементарной метрикой является количество строк кода (SLOC). Данная метрика была изначально разработана для оценки трудозатрат по проекту. Однако из-за того, что одна и та же функциональность может быть разбита на несколько строк или записана в одну строку, метрика стала практически неприменимой с появлением языков, в которых в одну строку может быть записано больше одной команды. Поэтому различают логические и физические строки кода. Логические строки кода — это количество команд программы. Данный вариант описания так же имеет свои недостатки, так как сильно зависит от используемого языка программирования и стиля программирования [2].
Кроме SLOC к количественным характеристикам относят также:
- количество пустых строк,
- количество комментариев,
- процент комментариев (отношение числа строк, содержащих комментарии к общему количеству строк, выраженное в процентах),
- среднее число строк для функций (классов, файлов),
- среднее число строк, содержащих исходный код для функций (классов, файлов),
- среднее число строк для модулей.
Иногда дополнительно различают оценку стилистики программы (F). Она заключается в разбиении программы на n равных фрагментов и вычислении оценки для каждого фрагмента по формуле Fi = SIGN (Nкомм.i / Ni — 0,1), где Nкомм.i — количество комментариев в i-м фрагменте, Ni — общее количество строк кода в i-м фрагменте. Тогда общая оценка для всей программы будет определяться следующим образом: F = СУММА Fi. [2]
Также к группе метрик, основанных на подсчете некоторых единиц в коде программы, относят метрики Холстеда [3]. Данные метрики основаны на следующих показателях:
n1 — число уникальных операторов программы, включая символы-
разделители, имена процедур и знаки операций (словарь операторов),
n2 — число уникальных операндов программы (словарь операндов),
N1 — общее число операторов в программе,
N2 — общее число операндов в программе,
n1′ — теоретическое число уникальных операторов,
n2′ — теоретическое число уникальных операндов.
Учитывая введенные обозначения, можно определить:
n=n1+n2 — словарь программы,
N=N1+N2 — длина программы,
n’=n1’+n2′ — теоретический словарь программы,
N’= n1*log2(n1) + n2*log2(n2) — теоретическая длина программы (для стилистически корректных программ отклонение N от N’ не превышает 10%)
V=N*log2n — объем программы,
V’=N’*log2n’ — теоретический объем программы, где n* — теоретический словарь программы.
L=V’/V — уровень качества программирования, для идеальной программы L=1
L’= (2 n2)/ (n1*N2) — уровень качества программирования, основанный лишь на параметрах реальной программы без учета теоретических параметров,
EC=V/(L’)2 — сложность понимания программы,
D=1/ L’ — трудоемкость кодирования программы,
y’ = V/ D2 — уровень языка выражения
I=V/D — информационное содержание программы, данная характеристика позволяет определить умственные затраты на создание программы
E=N’ * log2(n/L) — оценка необходимых интеллектуальных усилий при разработке программы, характеризующая число требуемых элементарных решений при написании программы
При применении метрик Холстеда частично компенсируются недостатки, связанные с возможностью записи одной и той же функциональности разным количеством строк и операторов.
Еще одним типом метрик ПО, относящихся к количественным, являются метрики Джилба. Они показывают сложность программного обеспечения на основе насыщенности программы условными операторами или операторами цикла. Данная метрика, не смотря на свою простоту, довольно хорошо отражает сложность написания и понимания программы, а при добавлении такого показателя, как максимальный уровень вложенности условных и циклических операторов, эффективность данной метрики значительно возрастает.
2. Метрики сложности потока управления программы
Следующий большой класс метрик, основанный уже не на количественных показателях, а на анализе управляющего графа программы, называется метрики сложности потока управления программ.
Перед тем как непосредственно описывать сами метрики, для лучшего понимания будет описан управляющий граф программы и способ его построения.
Пусть представлена некоторая программа. Для данной программы строится ориентированный граф, содержащий лишь один вход и один выход, при этом вершины графа соотносят с теми участками кода программы, в которых имеются лишь последовательные вычисления, и отсутствуют операторы ветвления и цикла, а дуги соотносят с переходами от блока к блоку и ветвями выполнения программы. Условие при построении данного графа: каждая вершина достижима из начальной, и конечная вершина достижима из любой другой вершины [4].
Самой распространенной оценкой, основанной на анализе получившегося графа, является цикломатическая сложность программы (цикломатическое число Мак-Кейба) [4]. Она определяется как V(G)=e — n + 2p, где e — количество дуг, n — количество вершин, p — число компонент связности. Число компонентов связности графа можно рассматривать как количество дуг, которые необходимо добавить для преобразования графа в сильно связный. Сильно связным называется граф, любые две вершины которого взаимно достижимы. Для графов корректных программ, т. е. графов, не имеющих недостижимых от точки входа участков и «висячих» точек входа и выхода, сильно связный граф, как правило, получается путем замыкания дугой вершины, обозначающей конец программы, на вершину, обозначающую точку входа в эту программу. По сути V(G) определяет число линейно независимых контуров в сильно связном графе. Так что в корректно написанных программах p=1, и поэтому формула для расчета цикломатической сложности приобретает вид:
V(G)=e — n + 2.
К сожалению, данная оценка не способна различать циклические и условные конструкции. Еще одним существенным недостатком подобного подхода является то, что программы, представленные одними и теми же графами, могут иметь совершенно разные по сложности предикаты (предикат — логическое выражение, содержащее хотя бы одну переменную).
Для исправления данного недостатка Г. Майерсом была разработана новая методика. В качестве оценки он предложил взять интервал (эта оценка еще называется интервальной) [V(G),V(G)+h], где h для простых предикатов равно нулю, а для n-местных h=n-1. Данный метод позволяет различать разные по сложности предикаты, однако на практике он почти не применяется.
Еще одна модификация метода Мак-Кейба — метод Хансена. Мера сложности программы в данном случае представляется в виде пары (цикломатическая сложность, число операторов). Преимуществом данной меры является ее чувствительность к структурированности ПО.
Топологическая мера Чена выражает сложность программы через число пересечений границ между областями, образуемыми графом программы. Этот подход применим только к структурированным программам, допускающим лишь последовательное соединение управляющих конструкций. Для неструктурированных программ мера Чена существенно зависит от условных и безусловных переходов. В этом случае можно указать верхнюю и нижнюю границы меры. Верхняя — есть m+1, где m — число логических операторов при их взаимной вложенности. Нижняя — равна 2. Когда управляющий граф программы имеет только одну компоненту связности, мера Чена совпадает с цикломатической мерой Мак-Кейба.
Продолжая тему анализа управляющего графа программы, можно выделить еще одну подгруппу метрик — метрики Харрисона, Мейджела.
Данные меры учитывает уровень вложенности и протяженность программы.
Каждой вершине присваивается своя сложность в соответствии с оператором, который она изображает. Эта начальная сложность вершины может вычисляться любым способом, включая использование мер Холстеда. Выделим для каждой предикатной вершины подграф, порожденный вершинами, которые являются концами исходящих из нее дуг, а также вершинами, достижимыми из каждой такой вершины (нижняя граница подграфа), и вершинами, лежащими на путях из предикатной вершины в какую-нибудь нижнюю границу. Этот подграф называется сферой влияния предикатной вершины.
Приведенной сложностью предикатной вершины называется сумма начальных или приведенных сложностей вершин, входящих в ее сферу влияния, плюс первичная сложность самой предикатной вершины.
Функциональная мера (SCOPE) программы — это сумма приведенных сложностей всех вершин управляющего графа.
Функциональным отношением (SCORT) называется отношение числа вершин в управляющем графе к его функциональной сложности, причем из числа вершин исключаются терминальные.
SCORT может принимать разные значения для графов с одинаковым цикломатическим числом.
Метрика Пивоварского — очередная модификация меры цикломатической сложности. Она позволяет отслеживать различия не только между последовательными и вложенными управляющими конструкциями, но и между структурированными и неструктурированными программами. Она выражается отношением N(G) = v *(G) + СУММАPi, где v *(G) — модифицированная цикломатическая сложность, вычисленная так же, как и V(G), но с одним отличием: оператор CASE с n выходами рассматривается как один логический оператор, а не как n — 1 операторов.
Рi — глубина вложенности i-й предикатной вершины. Для подсчета глубины вложенности предикатных вершин используется число «сфер влияния». Под глубиной вложенности понимается число всех «сфер влияния» предикатов, которые либо полностью содержатся в сфере рассматриваемой вершины, либо пересекаются с ней. Глубина вложенности увеличивается за счет вложенности не самих предикатов, а «сфер влияния». Мера Пивоварского возрастает при переходе от последовательных программ к вложенным и далее к неструктурированным, что является ее огромным преимуществом перед многими другими мерами данной группы.
Мера Вудворда — количество пересечений дуг управляющего графа. Так как в хорошо структурированной программе таких ситуаций возникать не должно, то данная метрика применяется в основном в слабо структурированных языках (Ассемблер, Фортран). Точка пересечения возникает при выходе управления за пределы двух вершин, являющихся последовательными операторами.
Метод граничных значений так же основан на анализе управляющего графа программы. Для определения данного метода необходимо ввести несколько дополнительных понятий.
Пусть G — управляющий граф программы с единственной начальной и единственной конечной вершинами.
В этом графе число входящих вершин у дуг называется отрицательной степенью вершины, а число исходящих из вершины дуг — положительной степенью вершины. Тогда набор вершин графа можно разбить на две группы: вершины, у которых положительная степень <=1; вершины, у которых положительная степень >=2.
Вершины первой группы назовем принимающими вершинами, а вершины второй группы — вершинами отбора.
Каждая принимающая вершина имеет приведенную сложность, равную 1, кроме конечной вершины, приведенная сложность которой равна 0. Приведенные сложности всех вершин графа G суммируются, образуя абсолютную граничную сложность программы. После этого определяется относительная граничная сложность программы:
S0=1-(v-1)/Sa,
где S0 — относительная граничная сложность программы, Sa — абсолютная граничная сложность программы, v — общее число вершин графа программы.
Существует метрика Шнейдевинда, выражающаяся через число возможных путей в управляющем графе.
3. Метрики сложности потока управления данными
Следующий класс метрик — метрики сложности потока управления данных.
Метрика Чепина: суть метода состоит в оценке информационной прочности отдельно взятого программного модуля с помощью анализа характера использования переменных из списка ввода-вывода.
Все множество переменных, составляющих список ввода-вывода, разбивается на 4 функциональные группы :
1. P — вводимые переменные для расчетов и для обеспечения вывода,
2. M — модифицируемые, или создаваемые внутри программы переменные,
3. C — переменные, участвующие в управлении работой программного модуля (управляющие переменные),
4. T — не используемые в программе («паразитные») переменные.
Поскольку каждая переменная может выполнять одновременно несколько функций, необходимо учитывать ее в каждой соответствующей функциональной группе.
Метрика Чепина :
Q = a1*P + a2*M + a3*C + a4*T,
где a1, a2, a3, a4 — весовые коэффициенты.
Весовые коэффициенты использованы для отражения различного влияния на сложность программы каждой функциональной группы. По мнению автора метрики, наибольший вес, равный 3, имеет функциональная группа C, так как она влияет на поток управления программы. Весовые коэффициенты остальных групп распределяются следующим образом: a1=1, a2=2, a4=0.5. Весовой коэффициент группы T не равен 0, поскольку «паразитные» переменные не увеличивают сложность потока данных программы, но иногда затрудняют ее понимание. С учетом весовых коэффициентов:
Q = P + 2M + 3C + 0.5T
Метрика спена основывается на локализации обращений к данным внутри каждой программной секции. Спен — это число утверждений, содержащих данный идентификатор, между его первым и последним появлением в тексте программы. Следовательно, идентификатор, появившийся n раз, имеет спен, равный n-1. При большом спене усложняется тестирование и отладка.
Еще одна метрика, учитывающая сложность потока данных — это метрика, связывающая сложность программ с обращениями к глобальным переменным.
Пара «модуль-глобальная переменная» обозначается как (p,r), где p — модуль, имеющий доступ к глобальной переменной r. В зависимости от наличия в программе реального обращения к переменной r формируются два типа пар «модуль — глобальная переменная»: фактические и возможные. Возможное обращение к r с помощью p показывает, что область существования r включает в себя p.
Данная характеристика обозначается Aup и говорит о том, сколько раз модули Up действительно получали доступ к глобальным переменным, а число Pup — сколько раз они могли бы получить доступ.
Отношение числа фактических обращений к возможным определяется
Rup = Aup/Pup.
Эта формула показывает приближенную вероятность ссылки произвольного модуля на произвольную глобальную переменную. Очевидно, что чем выше эта вероятность, тем выше вероятность «несанкционированного» изменения какой-либо переменной, что может существенно осложнить работы, связанные с модификацией программы.
На основе концепции информационных потоков создана мера Кафура. Для использования данной меры вводятся понятия локального и глобального потока: локальный поток информации из A в B существует, если:
1. Модуль А вызывает модуль В (прямой локальный поток)
2. Модуль В вызывает модуль А и А возвращает В значение, которое используется в В (непрямой локальный поток)
3. Модуль С вызывает модули А, В и передаёт результат выполнения модуля А в В.
Далее следует дать понятие глобального потока информации: глобальный поток информации из А в В через глобальную структуру данных D существует, если модуль А помещает информацию в D, а модуль В использует информацию из D.
На основе этих понятий вводится величина I — информационная сложность процедуры:
I = length * (fan_in * fan_out)2
Здесь:
length — сложность текста процедуры (меряется через какую-нибудь из метрик объёма, типа метрик Холстеда, Маккейба, LOC и т.п.)
fan_in — число локальных потоков входящих внутрь процедуры плюс число структур данных, из которых процедура берёт информацию
fan_out — число локальных потоков исходящих из процедуры плюс число структур данных, которые обновляются процедурой
Можно определить информационную сложность модуля как сумму информационных сложностей входящих в него процедур.
Следующий шаг — рассмотреть информационную сложность модуля относительно некоторой структуры данных. Информационная мера сложности модуля относительно структуры данных:
J = W * R + W * RW + RW *R + RW * (RW — 1)
W — число процедур, которые только обновляют структуру данных;
R — только читают информацию из структуры данных;
RW — и читают, и обновляют информацию в структуре данных.
Еще одна мера данной группы — мера Овиедо. Суть ее состоит в том, что программа разбивается на линейные непересекающиеся участки — лучи операторов, которые образуют управляющий граф программы.
Автор метрики исходит из следующих предположений: программист может найти отношение между определяющими и использующими вхождениями переменной внутри луча более легко, чем между лучами; число различных определяющих вхождений в каждом луче более важно, чем общее число использующих вхождений переменных в каждом луче.
Обозначим через R(i) множество определяющих вхождений переменных, которые расположены в радиусе действия луча i (определяющее вхождение переменной находится в радиусе действия луча, если переменная либо локальна в нём и имеет определяющее вхождение, либо для неё есть определяющее вхождение в некотором предшествующем луче, и нет локального определения по пути). Обозначим через V(i) множество переменных, использующие вхождения которых уже есть в луче i. Тогда мера сложности i-го луча задаётся как:
DF(i)=СУММА(DEF(vj)), j=i…||V(i)||
где DEF(vj) — число определяющих вхождений переменной vj из множества R(i), а ||V(i)|| — мощность множества V(i).
4. Метрики сложности потока управления и данных программы
Четвертым классом метрик являются метрики, близкие как к классу количественных метрик, классу метрик сложности потока управления программы, так и к классу метрик сложности потока управления данными (строго говоря, данный класс метрик и класс метрик сложности потока управления программы являются одним и тем же классом — топологическими метриками, но имеет смысл разделить их в данном контексте для большей ясности). Данный класс метрик устанавливает сложность структуры программы как на основе количественных подсчетов, так и на основе анализа управляющих структур.
Первой из таких метрик является тестирующая М-Мера [5]. Тестирующей мерой М называется мера сложности, удовлетворяющая следующим условиям:
Мера возрастает с глубиной вложенности и учитывает протяженность программы. К тестирующей мере близко примыкает мера на основе регулярных вложений. Идея этой меры сложности программ состоит в подсчете суммарного числа символов (операндов, операторов, скобок) в регулярном выражении с минимально необходимым числом скобок, описывающим управляющий граф программы. Все меры этой группы чувствительны к вложенности управляющих конструкций и к протяженности программы. Однако возрастает уровень трудоемкости вычислений.
Также мерой качества программного обеспечения служит связанность модулей программы [6]. Если модули сильно связанны, то программа становится трудномодифицируемой и тяжелой в понимании. Данная мера не выражается численно. Виды связанности модулей:
Связанность по данным — если модули взаимодействуют через передачу параметров и при этом каждый параметр является элементарным информационным объектом. Это наиболее предпочтительный тип связанности (сцепления).
Связанность по структуре данных — если один модуль посылает другому составной информационный объект (структуру) для обмена данными.
Связанность по управлению — если один посылает другому информационный объект — флаг, предназначенный для управления его внутренней логикой.
Модули связаны по общей области в том случае, если они ссылаются на одну и туже область глобальных данных. Связанность (сцепление) по общей области является нежелательным, так как, во-первых, ошибка в модуле, использующем глобальную область, может неожиданно проявиться в любом другом модуле; во-вторых, такие программы трудны для понимания, так как программисту трудно определить какие именно данные используются конкретным модулем.
Связанность по содержимому — если один из модулей ссылается внутрь другого. Это недопустимый тип сцепления, так как полностью противоречит принципу модульности, т.е. представления модуля в виде черного ящика.
Внешняя связанность — два модуля используют внешние данные, например коммуникационный протокол.
Связанность при помощи сообщений — наиболее свободный вид связанности, модули напрямую не связаны друг с другом, о сообщаются через сообщения, не имеющие параметров.
Отсутствие связанности — модули не взаимодействуют между собой.
Подклассовая связанность — отношение между классом-родителем и классом-потомком, причем потомок связан с родителем, а родитель с потомком — нет.
Связанность по времени — два действия сгруппированы в одном модуле лишь потому, что ввиду обстоятельств они происходят в одно время.
Еще одна мера, касающаяся стабильности модуля — мера Колофелло [7], она может быть определена как количество изменений, которые требуется произвести в модулях, отличных от модуля, стабильность которого проверяется, при этом эти изменения должны касаться проверяемого модуля.
Следующая метрика из данного класса — Метрика Мак-Клура. Выделяются три этапа вычисления данной метрики:
1. Для каждой управляющей переменной i вычисляется значениt её сложностной функции C(i) по формуле: C(i) = (D(i) * J(i))/n.
Где D(i) — величина, измеряющая сферу действия переменной i. J(i) — мера сложности взаимодействия модулей через переменную i, n — число отдельных модулей в схеме разбиения.
2. Для всех модулей, входящих в сферу разбиения, определяется значение их сложностных функций M(P) по формуле M(P) = fp * X(P) + gp * Y(P)
где fp и gp — соответственно, число модулей, непосредственно предшествующих и непосредственно следующих за модулем P, X(P) — сложность обращения к модулю P,
Y(P) — сложность управления вызовом из модуля P других модулей.
3. Общая сложность MP иерархической схемы разбиения программы на модули задаётся формулой:
MP = СУММА(M(P)) по всем возможным значениям P — модулям программы.
Данная метрика ориентирована на программы, хорошо структурированные, составленные из иерархических модулей, задающих функциональную спецификацию и структуру управления. Также подразумевается, что в каждом модуле одна точка входа и одна точка выхода, модуль выполняет ровно одну функцию, а вызов модулей осуществляется в соответствии с иерархической системой управления, которая задаёт отношение вызова на множестве модулей программы.
Также существует метрика, основанная на информационной концепции — мера Берлингера [8]. Мера сложности вычисляется как M=СУММАfi*log2pi, где fi — частота появления i-го символа, pi — вероятность его появления.
Недостатком данной метрики является то, что программа, содержащая много уникальных символов, но в малом количестве, будет иметь такую же сложность как программа, содержащая малое количество уникальных символов, но в большом количестве.
5. Объектно-ориентированные метрики
В связи с развитием объектно-ориентированных языков программирования появился новый класс метрик, также называемый объектно-ориентированными метриками. В данной группе наиболее часто используемыми являются наборы метрик Мартина и набор метрик Чидамбера и Кемерера. Для начала рассмотрим первую подгруппу.
Прежде чем начать рассмотрение метрик Мартина необходимо ввести понятие категории классов [9]. В реальности класс может достаточно редко быть повторно использован изолированно от других классов. Практически каждый класс имеет группу классов, с которыми он работает в кооперации, и от которых он не может быть легко отделен. Для повторного использования таких классов необходимо повторно использовать всю группу классов. Такая группа классов сильно связна и называется категорией классов. Для существования категории классов существуют следующие условия:
Классы в пределах категории класса закрыты от любых попыток изменения все вместе. Это означает, что, если один класс должен измениться, все классы в этой категории с большой вероятностью изменятся. Если любой из классов открыт для некоторой разновидности изменений, они все открыты для такой разновидности изменений.
Классы в категории повторно используются только вместе. Они настолько взаимозависимы и не могут быть отделены друг от друга. Таким образом, если делается любая попытка повторного использования одного класса в категории, все другие классы должны повторно использоваться с ним.
Классы в категории разделяют некоторую общую функцию или достигают некоторой общей цели.
Ответственность, независимость и стабильность категории могут быть измерены путем подсчета зависимостей, которые взаимодействуют с этой категорией. Могут быть определены три метрики :
1. Ca: Центростремительное сцепление. Количество классов вне этой категории, которые зависят от классов внутри этой категории.
2. Ce: Центробежное сцепление. Количество классов внутри этой категории, которые зависят от классов вне этой категории.
3. I: Нестабильность: I = Ce / (Ca+Ce). Эта метрика имеет диапазон значений [0,1].
I = 0 указывает максимально стабильную категорию.
I = 1 указывает максимально не стабильную категорию.
Можно определять метрику, которая измеряет абстрактность (если категория абстрактна, то она достаточно гибкая и может быть легко расширена) категории следующим образом:
A: Абстрактность: A = nA / nAll.
nA — количество_абстрактных_классов_в_категории.
nAll — oбщее_количество_классов_в_категории.
Значения этой метрики меняются в диапазоне [0,1].
0 = категория полностью конкретна,
1 = категория полностью абстрактна.
Теперь на основе приведенных метрик Мартина можно построить график, на котором отражена зависимость между абстрактностью и нестабильностью. Если на нем построить прямую, задаваемую формулой I+A=1, то на этой прямой будут лежать категории, имеющие наилучшую сбалансированность между абстрактностью и нестабильностью. Эта прямая называется главной последовательностью.
Далее можно ввести еще 2 метрики:
Расстояние до главной последовательности: D=|(A+I-1)/sqrt(2)|
Нормализированной расстояние до главной последовательности: Dn=|A+I-2|
Практически для любых категорий верно то, что чем ближе они находятся к главной последовательности, тем лучше.
Следующая подгруппа метрик — метрики Чидамбера и Кемерера [10]. Эти метрики основаны на анализе методов класса, дерева наследования и т.д.
WMC (Weighted methods per class), суммарная сложность всех методов класса: WMC=СУММАci, i=1…n, где ci — сложность i-го метода, вычисленная по какой либо из метрик (Холстеда и т.д. в зависимости от интересующего критерия), если у всех методов сложность одинаковая, то WMC=n.
DIT (Depth of Inheritance tree) — глубина дерева наследования (наибольший путь по иерархии классов к данному классу от класса-предка), чем больше, тем лучше, так как при большей глубине увеличивается абстракция данных, уменьшается насыщенность класса методами, однако при достаточно большой глубине сильно возрастает сложность понимания и написания программы.
NOC (Number of children) — количество потомков (непосредственных), чем больше, тем выше абстракция данных.
CBO (Coupling between object classes) — сцепление между классами, показывает количество классов, с которыми связан исходный класс. Для данной метрики справедливы все утверждения, введенные ранее для связанности модулей, то есть при высоком CBO уменьшается абстракция данных и затрудняется повторное использование класса.
RFC (Response for a class) — RFC=|RS|, где RS — ответное множество класса, то есть множество методов, которые могут быть потенциально вызваны методом класса в ответ на данные, полученные объектом класса. То есть RS=(({M}({Ri}), i=1…n, где M — все возможные методы класса, Ri — все возможные методы, которые могут быть вызваны i-м классом. Тогда RFC будет являться мощностью данного множества. Чем больше RFC, тем сложнее тестирование и отладка.
LCOM (Lack of cohesion in Methods) — недостаток сцепления методов. Для определения этого параметра рассмотрим класс C с n методами M1, M2,… ,Mn, тогда {I1},{I2},…,{In} — множества переменных, используемых в данных методах. Теперь определим P — множество пар методов, не имеющих общих переменных; Q — множество пар методов, имеющих общие переменные. Тогда LCOM=|P|-|Q|. Недостаток сцепления может быть сигналом того, что класс можно разбить на несколько других классов или подклассов, так что для повышения инкапсуляции данных и уменьшения сложности классов и методов лучше повышать сцепление.
6. Метрики надежности
Следующий тип метрик — метрики, близкие к количественным, но основанные на количестве ошибок и дефектов в программе. Нет смысла рассматривать особенности каждой из этих метрик, достаточно будет их просто перечислить: количество структурных изменений, произведенных с момента прошлой проверки, количество ошибок, выявленных в ходе просмотра кода, количество ошибок, выявленных при тестировании программы и количество необходимых структурных изменений, необходимых для корректной работы программы. Для больших проектов обычно рассматривают данные показатели в отношении тысячи строк кода, т.е. среднее количество дефектов на тысячу строк кода.
7. Гибридные метрики
В завершении необходимо упомянуть еще один класс метрик, называемых гибридными. Метрики данного класса основываются на более простых метриках и представляют собой их взвешенную сумму. Первым представителем данного класса является метрика Кокола. Она определяется следующим образом:
H_M = (M + R1 * M(M1) +… + Rn * M(Mn)/(1 + R1 +… + Rn)
Где M — базовая метрика, Mi — другие интересные меры, Ri — корректно подобранные коэффициенты, M(Mi) — функции.
Функции M(Mi) и коэффициенты Ri вычисляются с помощью регрессионного анализа или анализа задачи для конкретной программы.
В результате исследований, автор метрики выделил три модели для мер: Маккейба, Холстеда и SLOC, где в качестве базовой используется мера Холстеда. Эти модели получили название «наилучшая», «случайная» и «линейная».
Метрика Зольновского, Симмонса, Тейера также представляет собой взвешенную сумму различных индикаторов. Существуют два варианта данной метрики:
(структура, взаимодействие, объем, данные) СУММА(a, b, c, d).
(сложность интерфейса, вычислительная сложность, сложность ввода/вывода, читабельность) СУММА(x, y, z, p).
Используемые метрики в каждом варианте выбираются в зависимости от конкретной задачи, коэффициенты — в зависимости от значения метрики для принятия решения в данном случае.
Заключение
Подводя итог, хотелось бы отметить, что ни одной универсальной метрики не существует. Любые контролируемые метрические характеристики программы должны контролироваться либо в зависимости друг от друга, либо в зависимости от конкретной задачи, кроме того, можно применять гибридные меры, однако они так же зависят от более простых метрик и также не могут быть универсальными. Строго говоря, любая метрика — это лишь показатель, который сильно зависит от языка и стиля программирования, поэтому ни одну меру нельзя возводить в абсолют и принимать какие-либо решения, основываясь только на ней.
Надёжность программного обеспечения | areliability.com блог инженера по надёжности

Статья обновлена 23.04.2020
Надёжность программного обеспечения. Введение
Надёжность программного обеспечения — загадочное и неуловимое нечто. Если вы попытаетесь найти что-то по этой теме в яндексе, вы увидите кучу теоретических статей, где написано множество умных слов и формул, но ни одна статья не содержит ни единого примера реального расчёта надёжности программы.
На предприятиях космической отрасли ситуация ещё лучше. Когда я спросил у специалистов одного уральского НПО, как они считают надёжность программного обеспечения, они сделали круглые глаза и сказали: «А чё там, за единицу берём да и всё. А надёжность обеспечиваем отработкой». Я согласен, что такой подход имеет право на жизнь, однако хотелось бы большего. Короче, я написал свою методику, прошу любить и жаловать. Внизу привожу калькулятор, на котором можно посчитать надёжность этого вашего ПО.
Проблема надёжности программного обеспечения приобретает все большее значение в связи с постоянным усложнением разрабатываемых систем, расширением круга задач, возлагаемых на них, а, следовательно, и значительным увеличением объемов и сложности ПО. Короче, мы дожили до того дня, когда железо стало надёжнее софта, и одна ошибка в программном коде может угробить космическую миссию ценой в миллиарды долларов.
По факту, пообщавшись с коллегами по надёжности и функциональной безопасности, мы коллективно пришли к выводу, что оценивать ВБР (вероятность безотказной работы) ПО не имеет смысла. ПО это тот объект, для которого малоприменимы хорошо отработанные методики оценки надёжности, используемые при оценке компонентов, агрегатов и систем.
Всё, что мы сейчас можем, это открыть неплохой ГОСТ Р 51904-2002 Программное обеспечение встроенных систем. Общие требования к разработке и документированию и выбрать уровень разработки нашего ПО. Самое высоконадёжное (и самое дорогое) ПО будет уровня А, затем B и так далее. Все, что написано ниже — моя творческая инициатива, позволяющая оценить ВБР ПО.
Надёжность программного обеспечения обуславливается наличием в программах разного рода ошибок, внесенных в неё, как правило, при разработке. Под надёжностью ПО будем понимать способность выполнять заданные функции, сохраняя во времени значения установленных эксплуатационных показателей в заданных пределах, соответствующих заданным режимам и условиям исполнения. Под ошибкой понимают всякое невыполнение программой заданных функций. Проявление ошибки является отказом программы.
Показатели надёжности ПО
Наиболее распространенными показателями надёжности ПО являются следующие:
– начальное число ошибок N0 в ПО после сборки программы и перед её отладкой;
– число ошибок n в ПО, обнаруженных и оставшихся после каждого этапа отладки;
– наработка на отказ (MTBF), часов;
– вероятность безотказной работы (ВБР) ПО за заданное время работы P(t);
– интенсивность отказов ПО λ, 10-6 1/ч.
Упрощенная оценка надёжности ПО
Сперва рассмотрим методики, которые предлагаем нам отечественная нормативная база. Единственный нормативный документ по данной теме это ГОСТ 28195-99.
Оценка надежности ПО по ГОСТ 28195-99 рассчитывается по весьма упрощенной методике, констатирующей фактическую надёжность по опыту эксплуатации программного комплекса P(t) 1-n/N, где n – число отказов при испытаниях ПО; N – число экспериментов при испытаниях. Очевидно, что посчитать по этой методике ничего нельзя.
Статистическая оценка надёжности ПО
Куда больший интерес представляет описанная в [1] среднестатистическая оценка начального числа N0 ошибок в ПО после автономной отладки. Согласно данной оценке, количество ошибок на 1 К слов кода составляет 4,34 для языков низкого уровня (Ассемблер) и 1,44 для языков высокого уровня (С++). К сожалению, не совсем понятно, что имели в виду авторы под фразой «1 К слов кода». В англоязычной литературе принято использовать параметр тысяча строк кода (ТСК) (KLOC). Так, согласно [3] для операционной системы Windows 2000 плотность ошибок составляет 1,8-2,2 на ТСК. Учитывая, что Windows 2000 написан на языке программирования C и имеет близкую размерность числа ошибок, можно с высокой долей достоверности предположить, что отечественный авторы имели в виду именно параметр ТСК.
Отечественные авторы в [1] приводят статистические показатели интенсивности отказов ПО λ. Приведём их в таблице 1.1.
Таблица 1.1
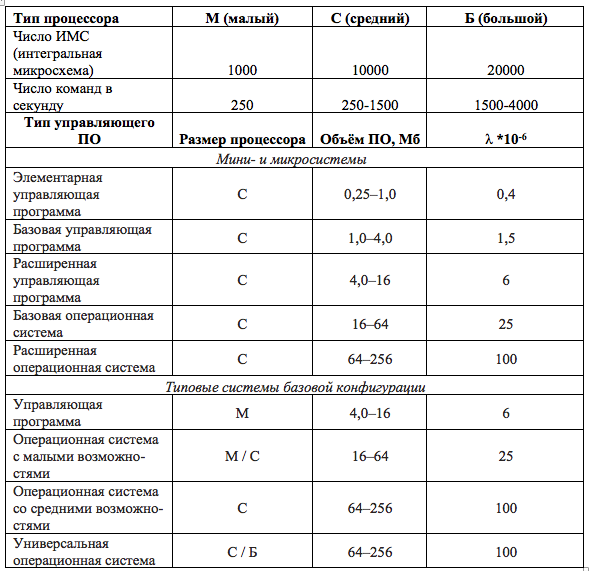
К сожалению, для какого языка ПО это действительно, авторы не сказывают. Кроме того, вводятся поправочные коэффициенты:
Таблица 1.2

И коэффициент, отражающий влияние времени работы программы:
Таблица 1.3
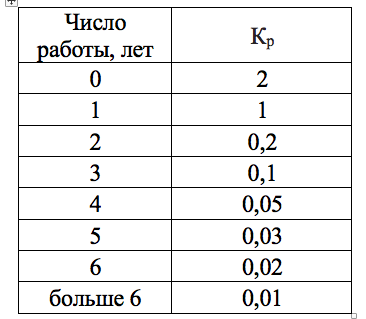
Тогда интенсивность отказов ПО λ определяется с помощью таблиц 1.1-1.3 по выражению:
λ по = λ* Кр* Кк* Кз* Ки (1.1)
Пример расчёта 1.
Объем ПО составляет 1 Мб, например.
Тогда, согласно таблице 1.1 λ = 6
Используем усредненные поправочные коэффициенты. Пусть:
Кр = 2 (короткий срок использования ПО)
Кк = 0,25 (высокое качество ПО)
Кз = 0,25 (высокая частота изменений ПО)
Ки = 1 (уровень загруженности средний)
λ по = 0,1 * 10 -6 отказов/час
Далее, используя экспоненциальную модель надёжности (при использовании данной модели поток отказов считается постоянным), можно получить ВБР ПО по стандартной формуле надёжности:
P(t) = exp**(-λ*t) (1.2)
Данная статистическая модель оценки надёжности ПО обладает значительными достоинствами по сравнению с упрощенной, однако и обладает рядом серьезных недостатков, в частности, она не учитываем язык разработки ПО и имеет большие интервалы объема ПО. То есть нельзя, например, сказать, какая будет надёжность у программы объёмом 2 гига и которая должна работать 10 лет.
Кроме того, поправочные коэффициенты имеют субъективную оценку. С какого потолка они взяты — неизвестно.
Попыткой устранения данных недостатков является Количественная модель оценки надёжности ПО.
Количественная модель оценки надёжности ПО
В основе данной модели лежит моё предположение, что уровень надежности ПО зависит от объема ПО (в битах или тысячах строк кода). Это утверждение не противоречит классической теории надежности, согласно которой чем объект сложнее, тем ниже его надёжность. Логично же. Чем больше будет строк кода, тем больше в итоге будет ошибок и тем ниже будет вероятность безотказной работы программы.
Используем оценку количества ошибок в зависимости от языка разработки из статистической модели:
Таблица 1.4
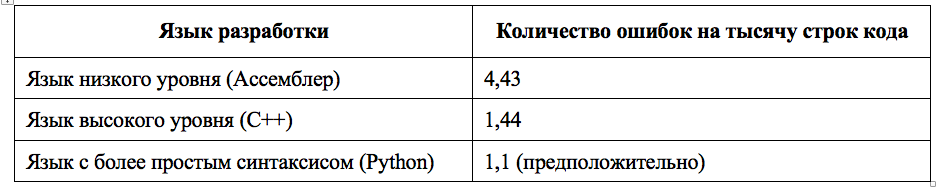
Далее, из [3] взята статистическая оценка связи количества строк кода и битов.
Для языка C, согласно [3] одна строка кода содержит 17 ± 3 байтов (146 битов) информации.
Зная V, объём кода ПО, в битах, мы можем получить число строк этого кода. Удобнее использовать параметр ТСК.
ТСК = V/146000 (1.3)
Используя данные таблицы 1.4 можно получить β, коэффициент количества ошибок на тысячу строк кода:
β = 1,44*ТСК/1000 (1.4)
Пример 2.
Объем ПО составляет 10 Мб. Язык разработки С++.
Тогда, согласно 1.3-1.4, β составит 0,08
Данный показатель очень близок к результату Примера 1.
Так появилась идея сопоставить параметр λ — интенсивности отказов ПО, получаемые статистической моделью и β, коэффициент количества ошибок ПО.
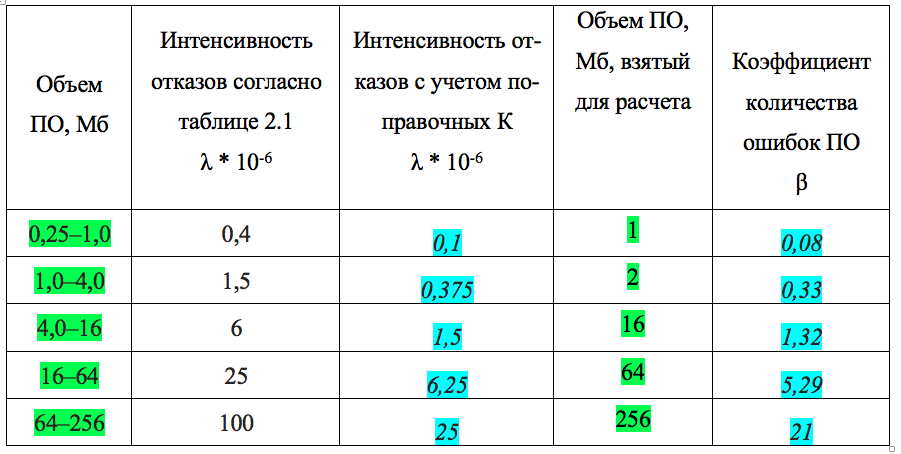
Сейчас внимание! Как видим, есть сильная корреляция результатов между интенсивностью отказов ПО с учётом поправочных коэффициентов и β — коэффициентом количества ошибок ПО. Использование других поправочных коэффициентов приводит к схожим результатам.
Можно сделать предположение, что введенный нами (придуманный мной) β по физическому смыслу близок к λ, интенсивности отказов. λ характеризует частоту отказов. β характеризует частоту ошибок в программе, а значит и отказов. Но! λ и β различаются. λ, единожды определённый для транзистора не изменяется от количества транзисторов. β — коэффициент динамический. Чем больше объём программы, тем больше β. Но это и логично. Чем больше программа, тем в ней больше ошибок. Кроме того, можно предположить, что авторы таблицы 1.1 написали её для ПО на языке С.
Очевидно, чем дольше работает программа, тем выше вероятность, что она откажет.
Используя экспоненциальную модель надёжности (при использовании данной модели поток отказов считается постоянным), можно получить ВБР ПО:
P(t) = exp**(-λ*t)
Резюмируя, для того чтобы оценить надёжность программного обеспечения, необходимо знать его язык разработки (высокий или низкий) и объём кода ПО.
[1] Надёжность авиационных приборов и измерительно-вычислительных комплексов, В.Ю. Чернов/ В.Г. Никитин; Иванов Ю.П. – М. 2004.
[2] Надёжность и эффективность в технике: Справочник., В.С. Авдуевский. 1988.
[3] Estimating source lines of code from object code, L. Hatton. 2005.
Попробуйте теперь что-нибудь посчитать. Например, найдите надёжность программного обеспечения, объём которого 100 Мб, и которое должно проработать 100 часов. Важно! Обратите внимание, что λ при изменении объёма ПО каждый раз пересчитывается под конкретный размер ПО.
KLOC, объём ПО в тысячах строк
β, к-т количества ошибок на тысячу строк кода для языка высокого уровня
β, к-т количества ошибок на тысячу строк кода для языка низкого уровня
λ, интенсивность отказов, язык высокого уровня
λ, интенсивность отказов, язык низкого уровня
t, время работы программы, часов
Вероятность безотказной работы, язык высокого уровня
Вероятность безотказной работы, язык низкого уровня
Валидация модели. Согласно этому сайту надёжность (вероятность безотказной работы) Windows 7 Home Premium составляет 0.98. Правда неизвестно, для какого времени работы сделан расчёт.
Давайте посчитаем по калькулятору. Windows 7 Home Premium после установки занимает около 15 гигабайт или 15360 мегабайт. Примем время работы — большой рабочий день = 12 часов. Тогда ВБР по калькулятору составит 0.984. Неплохо?
Продолжение. К вероятностной оценке надёжности программного обеспечения
Если вы хотите заказать у меня расчет надежности — нажмите на эту ссылку или на кнопку ниже.

Внимание! Если вас интересует корпоративное групповое обучение специалистов вашей компании, пожалуйста перейдите по ссылке ниже. Возможна адаптация учебной программы под ваши требования/пожелания/возможности как по объёму учёбы срокам обучения, формату обучения, так и по балансу теория/практика.


До встречи на обучении! С уважением, Алексей Глазачев. Инженер и преподаватель по надежности.
Ошибки программирования
Ошибки, которые обнаруживает компилятор, называют синтаксическими ошибками или ошибками компиляции. Синтаксические ошибки являются результатом ошибок в конструкции кода, таких как неправильное написание ключевого слова, пропуск необходимого знака пунктуации или использование открывающей фигурной скобки без соответствующей закрывающей фигурной скобки. Эти ошибки обычно легко обнаружить, поскольку компилятор говорит вам, где они находятся и что стало их причиной. Пример программы с синтаксической ошибкой:
Попытка компиляции приведённого кода:

Будет сообщено о четырёх ошибках, но в действительности программа содержит две ошибки:
Поскольку одна ошибка часто будет приводить к показу множества ошибок компиляции в разных строках, хорошей практикой является исправление ошибок начиная с верхней строки и постепенно двигаясь вниз. Исправление ошибок, которые ранее возникли в программе, может также исправить дополнительные ошибки, которые произошли позже.
Совет: если вы не знаете, как исправить ошибку, внимательно сравните вашу программу, символ за символом с похожими примерами в тексте. На начальном этапе обучения вы, вероятно, будете проводить много времени исправляя ошибки синтаксиса. Скоро вы будете знакомы с синтаксисом Java и сможете быстро исправлять синтаксические ошибки.
2. Ошибки во время выполнения
Ошибки во время выполнения – это ошибки, которые приводят к ненормальному обрывы работы программы. Они возникают во время работы программы, если среда обнаруживает операцию, которую невозможно выполнить. Обычно ошибки ввода становятся причинами ошибок во время выполнения. Ошибки ввода возникают, когда программа ожидает от пользователя ввода значения, но пользователь вводит величину, которую программа не может обработать. Например, программа ожидает получение числа, но вместо этого пользователь вводит строку, это приводит к ошибкам в программе, связанным с типами данных.
Другой пример ошибок во время выполнения – это деление на ноль. Это происходит, когда в целочисленном деление делитель равен нулю. Пример программы, которая вызовет ошибку во время выполнения:

3. Логические ошибки
Логические ошибки происходят, когда программа неправильно выполняет то, для чего она была создана. Ошибки этого рода возникают по многим различным причинам. Допустим, вы написали программу, которая конвертирует 35 градусов Цельсия в градусы Фаренгейта следующим образом:

Вы получите 67 градусов по Фаренгейту, что является неверным. Должно быть 95.0. В Java целочисленное деление показывает только часть – дробная часть отсекается, по этой причине в Java 9 / 5 это 1. Для получения правильного результата, нужно использовать 9.0 / 5, что даст результат 1.8.
Обычно ошибки синтаксиса легко обнаружить и легко исправить, поскольку компилятор даёт указания откуда пришла ошибка и что не так. Ошибки во время выполнения не трудны для поиска, поскольку причина и место для этих ошибок также показывается в консоли во время прерывания программы. Поиск логических ошибок, в свою очередь, очень сложный. В последующих главах вы обучитесь техникам трассировки программ и поиска логических ошибок.
4. Распространённые ошибки
Пропуск закрывающей фигурной скобки, пропуск точки с запятой, пропуск кавычки для строки и неправильное написание имён – всё это самые распространённые ошибки для новых программистов.
Частые ошибки 1: Пропущенные фигурные скобки
Фигурные скобки используются для обозначения в программе блоков. Каждой открывающей фигурной скобке должна соответствовать закрывающая фигурная скобка. Распространённая ошибка – это пропуск закрывающей фигурной скобки. Чтобы избежать эту ошибки, печатайте закрывающую фигурную скобку всякий раз, когда печатаете открывающую фигурную скобку как показано в следующем примере:

Если вы используете IDE такую как NetBeans и Eclipse, то IDE автоматически вставит закрывающую фигурную скобку каждой введённой вами открывающей фигурной скобки.
Частые ошибки 2: Пропуск точки с запятой
Каждая инструкция заканчивается ограничителем инструкции (;). Часто новые программисты забывают поместить ограничитель инструкции для последней инструкции в блоке как это показано в следующем примере:

Частые ошибки 3: Пропуск кавычки
Строки должны помещаться в кавычки. Часто начинающие программисты забывают поместить кавычку в конце строки как показано в следующем примере:

Если вы используете IDE, такую как NetBeans и Eclipse, то IDE автоматически вставит закрывающую кавычку каждый раз, когда вы ввели открывающую кавычку.
Частые ошибки 4: Неправильное написание имён
Java чувствительная к регистру. Неправильное написание имён – частая ошибка для новых программистов. Например, пишут слово main как Main, а вместо String пишут string. Пример:
Как посчитать ошибки в Excel с учетом их кодов
Часто складывается сложная ситуация, когда некоторые формулы вместо ожидаемых результатов вычисления выдает информацию об ошибке. Особенно полезной оказывается формула способная быстро находить и подсчитывать количество ошибочных значений в таблицах с большим объемом данных. А иногда нужно просто посчитать ошибку в Excel как числовое значение.
Как посчитать ошибку в формуле Excel
Перед тем как исправлять ошибки в Excel хорошо бы предоставить пользователю Excel возможность, наблюдать в режиме реального времени сколько еще осталось ошибок в процессе анализа вычислительных циклов формул. А для этого нужно их все посчитать. Пример схематической таблицы с ошибками в формулах:

На рисунке для примера проиллюстрированная проблемная ситуация, когда некоторые значения таблицы содержит ошибки вычислений формул в Excel там, где должны быть их результаты. Чтобы подсчитать количество ошибок в целой таблице следует сделать так:
Таким образом получаем текущее количество ошибок в таблице.
Разбор формулы для подсчета количества всех ошибок в ячейках Excel:
С помощью функции ЕОШИБКА проверена каждая ячейка диапазона A2:A9 на наличие ошибочных значений. Результаты функции в памяти программы образуют собой массив логических значений ИСТИНА и ЛОЖЬ. После перемножения каждого логического значения на число 1 в результате получаем массив из чисел 1 и 0. Потом все элементы массива суммируются, а формула возвращает количество ошибок.
Как найти первую ошибку в значении Excel
Пользователю для анализа вычислительных циклов полезно знать не только текущее количество неисправленных ошибок, но и строку, которая содержит первую ошибку. Чтобы узнать в какой строке листа встречается первая ошибка следует воспользоваться другой формулой:
Она также должна быть выполнена в массиве поэтому снова для подтверждения нажмите комбинацию горячих клавиш CTRL+SHIFT+Enter.

Первая ошибка находиться в третьей строке рабочего листа Excel.
Рассмотрим, как работает такая формула:
Наподобие первой формулы с помощью функции ЕОШИБКА в памяти программы создается массив из логических значений ИСТИНА и ЛОЖЬ. Далее функция СТРОКА возвращает текущие номера строк листа в диапазоне A2:A9. Благодаря функции ЕСЛИ в массиве с логическими значениями ИСТИНА заменяется на текущий номер строки. После чего функция МИН выбирает наименьшее число из этого же массива.
Как посчитать ошибки Excel с определенным кодом
Следующая полезная информация, которая пригодиться пользователю занятым проверкой ошибок – это количество определенного типа ошибок. Чтобы получить такой результат следует использовать третью формулу:
На этот раз формула не должна выполняться в массиве поэтому после ввода для ее подтверждения достаточно просто нажать клавишу Entеr.
Третья формула возвращает количество ошибок деления на 0 (#ДЕЛ/0!). Но она не мене эффективно работает если во втором аргументе функции СЧЕТЕСЛИ указать другой тип ошибки в ячейках Excel. Например, #ИМЯ?

Как видно на рисунке все работает не менее эффективно.
Чтобы узнать в какой строке встречается первая ошибка конкретного типа и кода следует использовать четвертую формулу:
Как показано на очередном рисунке, формула возвращает значение 4 которое соответствует номеру строки где впервые встречается ошибка деления на 0.

Коды и типы ошибок Excel
Функция ТИП. ОШИБКИ проверяет каждую ячейку в диапазоне A1:A9, если она наталкивается на ошибку возвращает соответствующий ей номер (например, код ошибки деления на ноль: для типа #ДЕЛ/0! – это код 2). Ниже приведена целая таблица типов и кодов для обработки ошибок Excel:
| ТИП | КОД |
| #ПУСТО! | 1 |
| #ДЕЛ/0! | 2 |
| #ЗНАЧ! | 3 |
| #ССЫЛКА! | 4 |
| #ИМЯ? | 5 |
| #ЧИСЛО! | 6 |
| #Н/Д | 7 |
| #ОЖИДАНИЕ_ДАННЫХ | 8 |
Далее создается в памяти массив значений с номерами кодов ошибок. В первом аугменте функции ПОИСКПОЗ мы указываем код ошибки, которую нужно найти. В третьем аргументе мы указываем код 0 для функции ПОИСКПОЗ, который означает что возвращать нужно первое встречающееся значение 2 при наличии дубликатов в массиве.
Внимание! В четвертой формуле мы ссылались на диапазон ячеек начиная с A1 и до A9. Потому как функция ПОИСКПОЗ возвращает текущею позицию значения относительно таблицы, а не целого листа. Поэтому во втором аргументе функции ПОИСКПОЗ следует указывать диапазон просматриваемых значений так, чтобы номера позиций совпадали с номерами строк листа. Другими словами, если бы мы указали адрес диапазона A2:A9, то формула вернула бы значение 5 – что не является правильным.
Источники:
https://java9.ru/?p=108
https://exceltable. com/formuly/kak-poschitat-oshibki
Привет, Вы узнаете про метрики кода, Разберем основные ее виды и особенности использования. Еще будет много подробных примеров и описаний. Для того чтобы лучше понимать что такое
метрики кода, метрика программного обеспечения, исходящие зависимости, входящие зависимости, цикломатическая сложность, cyclomatic complexity , настоятельно рекомендую прочитать все из категории Проектирование веб сайта или программного обеспечения.
метрики кода
Это количественные показатели, которые можно измерить и которые могут дать представление о качестве кода
Метрики программного кода, в отличие от Agile или Performance метрик, несут истинную ценность только для программиста. Метрики собираются до и после проведения большого рефакторинга для понимания, что же изменилось и не стало ли хуже. В больших проектах метрики позволят быстро обнаружить проблемные участки кода подобно тому, как performance-профайлеры указывают на проблемы с производительностью в конкретном месте. Метрики встраиваются в CI системы, такие как TeamCity или Jenkins, чтобы иметь возможность контролировать изменения значений метрик с каждым комитом кода в репозиторий.
Достаточно часто программистам приходится поддерживать чужой код, очень часто этот код выглядит не самым лучшим образом, и сопровождать его очень сложно. Если это приложение не придется выбросить в скором времени, то естественно его стоит привести в человеческий вид, т.е. отрефакторить. Было бы хорошо иметь какую-нибудь метрику, которая позволила бы оценить качество кода и определить места, которые стоит улучшить. Такая метрика позволила бы оценить, например, то, как программист пишет исходный код или то, насколько качественен код в том приложении, которое Вы собираетесь поддерживать.
многие ИДЕ предоставляет встроенное средство, которое позволяет оценить код вашего проекта.

Получить оценку вашего кода можно нажав правой кнопкой на проекте и выбрав пункт “Calculate Code Metrics” (Эта функциональность доступна в Visual Studio 2008 Team System и Visual Studio 2010 начиная с Premium версии).
Большинство метрик могут быть подсчитаны для метода, класса, пространства имен и целого проекта. Однако не все метрики одинаково полезны на каждом из уровней. Рассмотрим каждую метрику только для того уровня, для которого она несет наибольшую ценность.
Что можно поменять(количественно оценить):
исходящие зависимости класса
входящие зависимости класса
цикломатическая сложность- Глубина наследования
- Количество строк кода
- Maintainability Index
- Lines of code
- Number of classes
- Inheritance depth
- Maintainability inde
- Cyclomatic index
- покрытость тестами кода
и другие параметры
Maintainability Index
Maintainability Index – комплексный показатель качества кода. Этот показатель разработан специалистами из Carnegie Mellon Software Engineering Institute. Рассчитывается метрика по следующей формуле:
MI = MAX(0, (171 — 5.2 * ln(HV) — 0.23 * CC — 16.2 * ln(LoC)) * 100 / 171)
Эта метрика может принимать значения от 0 до 100 и показывает относительную сложность поддержки кода. Чем больше значение этой метрики, тем легче поддерживать код.
Visual Studio помечает методы/классы зеленым цветом, если значение метрики находится в пределах от 20 до 100, желтым цветом, если значение находится в пределах от 10 до 20, и красным цветом, когда значение меньше 10.
- HV – Halstead Volume, вычислительная сложность. Чем больше операторов, тем больше значение этой метрики;
- CC – Cyclomatic Complexity. Эта метрика описана ниже;
- LoC – количество строк кода.
NDepend. Dependency graph
По умолчанию панель графиков зависимостей NDepend отображает график зависимостей между сборками .NET: NDepend предлагает изучить график зависимостей между пространствами имен проекта Visual Studio. В окне «Редактор решений» (или «Редактор кода») щелкните правой кнопкой мыши меню, NDepend предлагает изучить график зависимостей между типами пространства имен. Обратите внимание, что NDepend поставляется с эвристикой, чтобы попытаться вывести пространство имен из папки в обозревателе решений. В окне «Редактор решений» (или «Редактор кода») щелкните правой кнопкой мыши меню, NDepend предлагает изучить график зависимостей между членами (методы + поля) типа. Обратите внимание, что NDepend поставляется с эвристикой, чтобы попытаться вывести тип из исходного файла в обозревателе решений.
Ndepend. Dependency matrix
DSM (Matrix Dependency Structure Matrix) — это компактный способ представления и навигации по зависимостям между компонентами. Для большинства инженеров разговор о зависимостях означает разговор о чем-то, что выглядит так:
DSM используется для представления той же информации, что и граф.
- Элементы заголовка матрицы представляют собой графы
- Матричные непустые ячейки соответствуют стрелкам графика.
Как следствие, в приведенном ниже снимке связь с IronPython с IronMath представлена непустой ячейкой в матрице и стрелкой на графике.
Зачем использовать два разных способа, график и DSM, чтобы представлять одну и ту же информацию? Потому что есть компромисс:
- График более интуитивно понятен, но может быть совершенно непонятным, когда число узлов и ребер растет (нескольких десятков боксов может быть достаточно, чтобы создать слишком сложный график)
- DSM менее интуитивно понятен, но может быть очень эффективным для представления большого и сложного графа. Мы говорим, что шкалыDSM сравниваются с графиком.
Как только один понимает принципы DSM, как правило, один предпочитает DSM над графом для представления зависимостей. Это связано главным образом с тем, что DSM предлагает возможность мгновенно выявлять структурные шаблоны . Это объясняется во второй половине текущего документа.
NDepend предлагает контекстно- зависимую справку для обучения пользователя тому, что он видит в DSM. DSM DDepend опирается на простую 3-красочную схему для ячейки DSM: синий, зеленый и черный. При наведении строки или столбца с помощью мыши в контекстно-зависимой справке объясняется значение этой схемы раскраски:
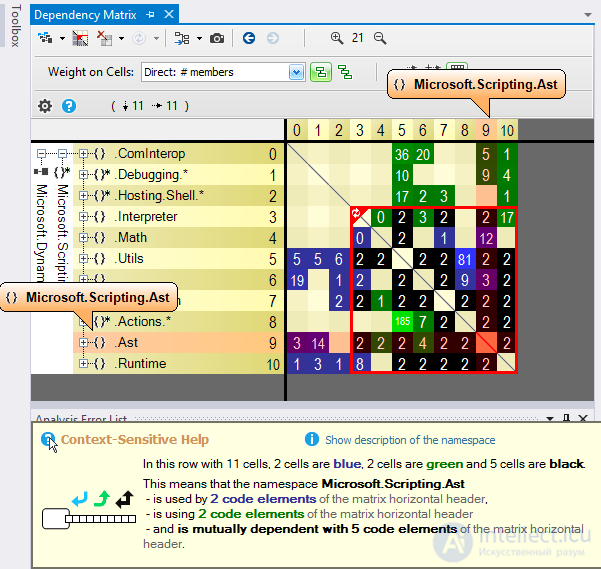
Непустая ячейка DSM содержит число. Это число представляет сильные стороны связи, представленной клеткой. Сила связи может быть выражена в терминах количества членов / методов / полей / типов или пространств имен, участвующих в связи, в зависимости от фактического значения параметра « Вес на ячейках» . В дополнение к Контекстно-чувствительной справке, DSM предлагает также Информационную панель,которая объясняет связь с простым английским описанием:
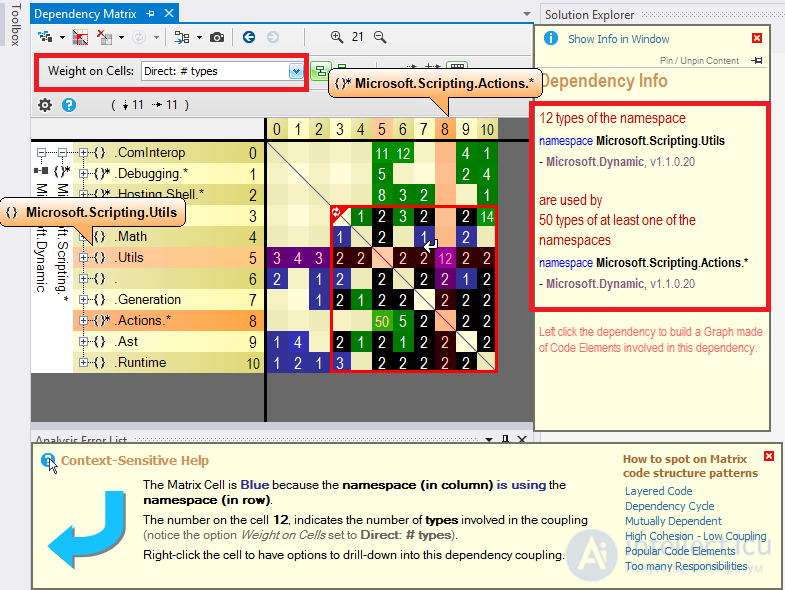
NDepend DSM поставляется с многочисленными опциями, чтобы попробовать:
- Он имеет множество возможностей для поиска в исследовании зависимостей (можно открыть родительский столбец / строку, ячейки можно расширить …)
- Он может иметь дело с квадратичным симметричным DSM и прямоугольным несимметричным DSM
- Строки и столбцы могут быть связаны, чтобы постоянно иметь квадратную симметричную матрицу
- Он поставляется с опцией « Косвенное использование» , где ячейка показывает прямое и косвенное использование
- Строки могут содержать сторонние элементы кода
- …
Рекомендуется использовать все эти функции самостоятельно, анализируя зависимости в вашей базе кода.
Ndepend. Metrics view
NDepend Metric View предлагает множество возможностей для визуализации метрик кода приложения. Таким образом, недостатки кода и шаблоны кода становятся более очевидными. Такие перспективы направлены на то, чтобы улучшить ваше понимание базы кода, чтобы вы могли принять лучшее решение увеличить качество кода и удобство обслуживания кода.
Метричность и трекинг
в метрике В метрическом представлении база кода представлена через Treemap . Об этом говорит сайт https://intellect.icu . Treemapping — это алгоритм визуализации для отображения древовидных данных с использованием иерархии вложенных прямоугольников.Древовидная структура, используемая в NDepend treemap, является обычной иерархией кода:
- Сборки .NET содержат пространства имен
- пространства имен содержат типы
- типы содержат методы и поля
Треугольные прямоугольники представляют собой элементы кода. Параметр уровень определяет тип элемента кода ,представленный единичных прямоугольники. Параметр уровня может принимать значения 5: сборки, пространство имен, тип, метод и поле. Две картинки ниже показывают один и тот же базовый код , отображаемый Method уровня (слева) ипространство имен уровень (справа).
Обратите внимание, что элементы кода, принадлежащие к тем же элементам родительского кода (например, методы в классе или классы в пространствах имен), расположены рядом с treemap.
Параметр Размер treemap определяет размер прямоугольников. Например, если уровень установлен на тип, а метрика — на число строк кода , каждый прямоугольник единицы представляет собой тип, а размер прямоугольника единицы пропорционален количеству строк кода соответствующего типа.
Для каждого уровня элемента кода предлагается несколько кодовых показателей. Также, как объясняется далее в этом документе, можно определить собственные метрики кода и визуализировать их посредством treemaping.
Опция позволяет сгенерировать кодовый запрос CQLinq дляВыберите элементы верхнего кода N в соответствии с выбранными метриками кода.

Color Metric
В приведенном выше разделе объясняется, как визуализировать кодовую метрику благодаря трекингованию. Вторая метрика кода может быть представлена красными элементами элементов прямоугольника. Следовательно, метрический вид NDepend удобен для корреляции двух кодовых метрик. Например, снимок экрана ниже показывает покрытие кода на основе тестов на базе кода NDepend. С помощью NDepend или некоторых других инструментов можно получить коэффициент покрытия кода для каждого метода / типа / пространства имен / сборки. Но, объединив # строк кода с коэффициентом покрытия цвета, цветной treemaping, мы получаем уникальное проницательное представление о том, что покрывается или нет с помощью тестов. Например, несмотря на то, что база кода NDepend более 80% покрыта тестами, что является хорошим показателем, цветной treemap показывает красные области, такие как NDepend.Addin.dll
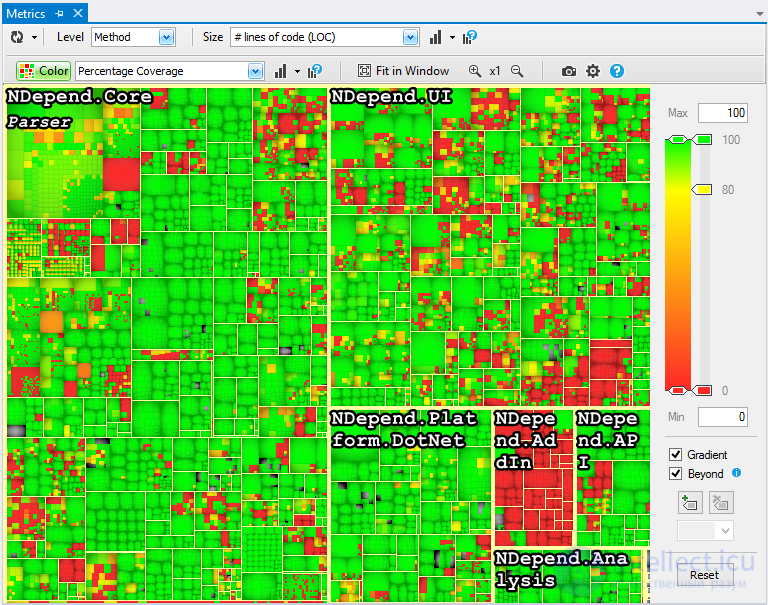
CQL Query Explorer
NDepend. CQL
SQL подобный синтакс
Запросы к базе кода (code base), чтобы получить метрики
SELECT TOP 10 METHODS ORDER BY NbLinesOfCode DESC
SELECT METHODS WHERE NbLinesOfCode > 10
SELECT FIELDS WHERE HasAttribute «System.ThreadStaticAttribute»
Метрики

Coupling
Efferent coupling (Ce): внутренняя связанность, число типов внутри сборки, которые зависят от типов из вне сборки
Afferent coupling (Ca): внешняя связанность, число типов вне сборки которые зависят от типов в внутри сборки
Instability (I)
Instability (I): отношение внутренней связанности(Ce) к общей связанности, индикатор устойчивости к изменениям. I = Ce / (Ce + Ca) I=0 – полностью стабильная сборка, сложная для модификации. I=1 – нестабильная сборка, внутри слабая связанность
Abstractness (A)
Abstractness (A): абстрактность, отношение числа внутренних абстрактных типов к числу внутренних типов
. A=0 – полностью «конкретная» сборка
A=1 – полностью абстрактная сборка
Relational Cohesion (H)
Relational Cohesion (H): относительная сцепленность, среднее число внутренних отношений на тип: H = (R + 1) / N, где R = число отношений внутри сборки,
N = число типов сборки
Классы внутри сборки должны сильно соотносится друг с другом, и сцепленность должна быть высокой.
С другой стороны, слишком большие значение могут означать излишнюю связанность. Хорошие значения сцепленности 1.5 <=H<= 4.0
Coupling, Cohesion, Abstractness and Instability metrics on example
Се = внутренняя связанность, Са – внешняя, I – стабильность, N – число типов сборки, А – абстрактность, Н – относительная сцепленность
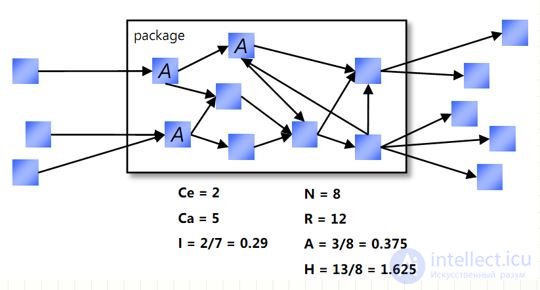
Lack of cohesion (LCOM)
Принцип SRP утверждает, что класс должен иметь не более чем одну причину для изменения. Такой класс сцепленный (cohesive). Высокое значение означает плохо сцеплений класс. Типы, у которых LCOM > 0.8 могут быть проблемными. Тем не менее, очень сложно избежать таких не- сцепленных типов
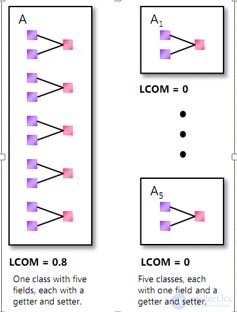
Cyclomatic Complexity (CC)
Число следующих выражений в методе: if, while, for, foreach, case, default, continue, goto, &&, ||, catch, ? : (ternary operator), ?? (nonnull operator)
Эти выражения не учитываются: else, do, switch, try, using, throw, finally, return, object creation, method call, field access
CC > 15 сложно понимать, CC > 30 очень сложные и должны быть разбиты на более мелкие методы (кроме сгенерированного кода)
Distance from main sequence: zone of pain and zone of uselessness
Main sequence в терминах NDepend, A + I = 1, Представляет оптимальный баланс между абстрактностью и стабильностью D – это нормализированное расстояние от main sequence, 0 <=D <=1 Сборки с D > проблематичны Но, в реальной жизни, сложно избежать таких сборок. Просто необходимо удерживать число таких сборок минимальным.

Исходящие зависимости класса (Efferent Couplings или Outgoing dependencies)
Метрика показывает количество классов, которые используются внутри измеряемого класса. Например, для класса Calculator ниже метрика будет равна 2.
public class Calculator
{
private DataSource1 _DS1 { get; } = new DataSource1();
private DataSource2 _DS2 { get; } = new DataSource2();
public int Calculate()
{
return _DS1.GetNumber1() * _DS2.GetNumber2();
}
}
Чем больше у класса исходящих зависимостей, тем больше требуется времени для внесения в него изменений, так как дополнительно приходится изучать поведение зависимых классов. Для уверенного внесения изменения в метод Calculate не достаточно изучить только его реализацию, так как она не является изолированной от окружающего мира. Необходимо понять, как работают классы DataSource1 и DataSource2.
Большое количество исходящих зависимостей (5+) обычно говорит о том, что класс делает слишком много, то есть нарушает принцип единой ответственности. Такие классы тяжело сопровождать и они имеют риск бесконечно увеличиваться в размерах. Привести к норме значение метрики поможет выбор более конкретного имени для класса (не Calculator, а например EmployeeCompensationCalculator), вынесение неподходящей логики в отдельные классы, уместное применение шаблонов, помогающих соблюдать принцип единой ответственности (Decorator, Mediator, Chain o Responsibility, Command и тд).
Если класс спроектирован так, что все его зависимости инициализируются в конструкторе, то их количество легко подсчитать вручную, только изучив тело конструктора. Для автоматического подсчета метрик в Visual Studio 2017 можно перейти во вкладку Analyze -> Calculate Code Metrics -> For Solution. Появится окно с метриками под названием Code Metric Results. Сама метрика будет называться Class Coupling.
Входящие зависимости класса (Afferent Couplings или Incoming Dependencies)
Метрика показывает количество классов, которые ссылаются на измеряемый класс. Чем выше значение метрики для некоторого класса, тем потенциально возрастает количество мест системы, которые могут быть поломаны в следствии внесенных в него изменений. Однако, если входящие зависимости на некоторый класс отсутствуют совсем, то он является мусором.
public class DataStorage
{
public int GetValue()
=> 5;
}
public class Calculator
{
public int Calculate() =>
new DataStorage().GetValue() * 5;
}
public class AnotherCalculator
{
public int Calculate() =>
new DataStorage().GetValue() * 10;
}
Класс DataStorage используется в классах Calculator и AnotherCalculator, следовательно, логика обоих может быть поломана в результате изменения в методе GetValue.
Обычно чрезмерное использование некоторого класса во многих местах проекта говорит о том, что он нарушает принцип единой ответственности и является God Object’ом, храня в себе функционал на все случаи жизни. Такой класс требует рефакторинга. Однако, класс может соблюдать SRP и также являться часто используемым в силу своей специфики. В таком случае высокое значение метрики говорит о высоком уровне повторного использования кода.
Visual Studio 2017 позволяет отыскать все ссылки на тип при помощи опции Find All References. Также значение метрики показывают различные статические анализаторы кода.
Цикломатическая сложность (Cyclomatic Complexity)
Метрика определяет сложность некоторого участка кода, например, метода, путем подсчета в нем количества условных операторов, циклов, switch и case операторов.
Cyclomatic Complexity – показывает структурную сложность кода, т.е. количество различных ветвей в коде. Чем больше этот показатель, тем больше тестов должно быть написано, для полного покрытия кода.
//Цикломатическая сложность - 1
int Calculate(int x, int y)
{
return x / y;
}
//Цикломатическая сложность - 2
int Calculate(int x, int y)
{
if (y == 0)
throw new ArgumentException();
return x / y;
}
//Цикломатическая сложность - 3
int Calculate(int x, int y)
{
if (x == 0)
throw new ArgumentException();
else if (y == 0)
throw new ArgumentException();
else //блок else не влияет на значение метрики
return x / y;
}
//Цикломатическая сложность - 4
static int Calculate(int x, int y)
{
if (x > y)
throw new ArgumentException();
else if (x == y)
return x;
int rangeSum = 0;
for (int i = x; i <= y; i++)
rangeSum += i;
return rangeSum;
}
Чем выше значение метрики для участка кода, тем сложнее его читать и вносить изменения. Также усложняется написание юнит-тестов, которые бы покрывали все возможные пути выполнения метода (кстати, метрика в юнит-тестировании, которая подсчитывает степень покрытия путей выполнения кода, называется Branch Coverage).
Рефакторить код с высокой цикломатической сложностью (больше 25 считается высокой) можно пересмотром выбранного решения в сторону более красивого, повторным использованием дублирующейся логики, применением шаблона проектирования (например, Rules) либо подхода Table-Driven Methods.
В Visual Studio 2017 метрика отображается в окне Code Metric Results.
Глубина наследования (Depth of Inheritance)
Depth of Inheritance – глубина наследования. Эта метрика показывает для каждого класса, какой он по счету в цепочке наследования. Например, есть 3 класса A, B, C, B унаследован от А, а С унаследован от В, то значение этой метрики для классов A,B и C будет равно соответственно 1, 2 и 3.
Показывает порядковый номер класса в иерархии наследования.
public class A { } // Глубина наследования - 1
public class B : A { } //Глубина наследования - 2
public class C : B { } //Глубина наследования - 3
Наследование добавляет классу новую функциональность в виде свойств и методов. Следовательно, класс со значением метрики 5 будет содержать в себе функционал четырех классов выше по иерархии и анализ его поведения будет затруднительным. C другой стороны, классы, находящиеся «на дне» иерархии, повторно используют функционал, описанный в родителях, что есть хорошо. По этой причине нельзя точно сказать хорошо или плохо наличие в проекте классов с большим значением данной метрики. Необходимо анализировать каждый конкретный случай.
В Visual Studio 2017 метрика отображается в окне Code Metric Results.
Количество строк кода (Lines of Code)
Метрика показывает количество строк кода, причем строки с комментариями, пустые строки или фигурные скобки в расчет не принимаются. В основном метрика применяется для обнаружения больших методов и классов.
В Visual Studio 2017 метрика отображается в окне Code Metric Results.
Lines of Code – показывает количество строк кода. Этот показатель показывает не точное количество строк в вашем файле, т.к. подсчет основан на IL-коде. В расчет не берутся пустые строчки, комментарии, строчки со скобками, объявление типов и пространств имен. Большое количество строк в методе/классе может показывать на ошибки в проектировании и на то, что этот код можно разделить на несколько частей.
Class Coupling
Class Coupling – показывает степень зависимости классов друг с другом. В расчет берутся уникальные классы из параметров, локальных переменных, возвращаемого типа, базового класса, атрибутов (полный список можно найти в MSDN). Хороший дизайн программного обеспечения предполагает небольшое количество связанных классов. Чем их больше, тем сложнее в дальнейшем переиспользовать этот класс, а также поддерживать, т.к. существует очень много зависимостей.
Maintainability Index
Maintainability Index является комплексной метрикой, которая рассчитывается исходя из цикломатической сложности, количества строк метода и вычислительной сложности (Halstead Volume, чем выше общее количество операторов и операндов в коде, тем выше значение метрики).
Метрика показывает значения от 0 (наихудшее) до 100 (наилучшее).
В Visual Studio 2017 метрика отображается в окне Code Metric Results.
Как определить и повышать внутреннее качество продукта с использованием метрик кода и других оценок?
Необходимость качественного и грамотного написания кода — вот одна из основополагающих вещей, которым мы обучаем будущих программистов при выполнении учебных проектов.
И это не только то, чему мы учим, это еще и то, что принято у нас в компании при работе над проектами заказчиков — мы стараемся делать их так, чтобы внутреннее качество продукта (как написан код) не уступало внешнему (как отрабатывает функционал).
Многие зачастую уделяют внимание только второму — главное функционал, чтобы заказчик принял и заплатил. А после нас — хоть трава не расти — какая разница, кто и как будет поддерживать, или пытаться изменить этот код — пусть мучаются, мы же в свое время мучились с чужими макаронами.
Внутреннее качество важно не только из-за того, что мы гуманисты и думаем о том, кто этот код будет поддерживать. Еще мы честолюбивы и эгоистичны.
Итак, внутреннее качество нам обеспечивает:
- Понятность (что помогает легко выполнять bug fixing, быстрее и легче включаться в работу новым членам команды, легко поддерживать код)
- Уменьшение работы в перспективе (количество ошибок снижается, количество времени на разбор кода сокращается, облегчается поддержка кода)
- Адаптируемость (мы работаем по Agile, а это предполагает, что требования заказчиков меняются часто, и реагировать на изменения нужно быстро)
Как же это внутреннее качество контролировать? Подходов есть несколько. Мы применяем все.
1. Проводить code review
Причем review у нас проводят не тех лиды, а все члены команды. Здесь мы убиваем двух зайцев одним махом: проверяется качество кода, и знание кода распределяется между членами команды.
На что мы проверяем код во время code review? На соответствие стандартам, отсутствие антипаттернов (как в коде, так и в построении схемы БД), следование практик ООП/ООД, качество документации.
На проведение code review мы отдельно закладываем время, у нас есть специальный статус для задач (Open->In Progress->Ready for Code Review->In Review-> Ready for Testing…). Так что не сделать не выйдет.
2. Использовать сторонние инструменты контроля качества кода
Мы используем Sonar и для Java, и для .NET проектов. На что мы инспектируем код с помощью Sonar?
Покрытие кода юнит тестами (Code coverage). Да-да, мы пишем юнит тесты:
- Line Coverage — сколько строк кода выполнено и протестировано. Наша метрика, которую мы соблюдаем — 80%.
- Branch coverage — каждое ли условное выражение (true/false) было выполнено и протестировано. Аналогично — 80%. Более важный, чем line coverage, т.к. показывается реальную степень тестируемости бизнес-логики.
Комментарии (Comments):
- Документируемость API — следим, чтобы код содержал пояснения. Особенно важно для распределенных Agile проектов. Метрика — 80% публичных методов должны быть задокументированы.
- Следим, чтобы не было закомментированного кода — 0 строк.
Отсутствие связности внутри методов (LCOM4) — чем эта метрика больше, тем риск падения системы выше при изменении функционала. Особенно из-за тех мест, которые дают увеличение этой метрики (Sonar выдает усредненную).
Индикатор спутанности пакетов (Package tangle index) — количество циклический зависимостей между пакетами и общим числом зависимостей должно стремиться к 0.
Процент дублирования кода (Duplications) — отсутствие копипаста кода — должно стремиться к 0%
Цикломатическая сложность (Сomplexity) кода определяет сложность структуры кода: чем меньше вложенных операторов ветвления и циклов, тем лучше:
- На метод мы придерживаемся метрики — до 7. Больше — рефакторим.
- На класс — до 15.
- На файл — мы отключаем.
Также мы внимательны к замечаниям (violations), которые выдает Sonar — мы исправляем блокеры, критикалы и мажоры.
Sonar — настраиваемый инструмент, и есть еще множество метрик, которые можно собирать и анализировать. Иногда мы к ним прибегаем, но зачастую останавливаемся на вышеперечисленных стандартных.
Что влияет на возможность отслеживать внутренне качество?
- Грамотный CI. Не будет его — не будет возможности собирать метрики.
- Выстроенные процессы. Во время спринта разработчики отслеживают метрики на своих машинах, проводят code review В конце спринта, на ретроспективе, метрики — один из обязательных предметов обсуждения, если что-то осталось не так — закладываем задачу на коррекцию на след спринт.
Реальное использование
Когда я первый раз запустил анализ на одном из проектов, все значения Maintainability Index были зеленые. Это казалось несколько странным, т.к. там явно был код, который надо было бы переписать. Значения MI для таких участков кода были около 30-40. Получается, что показатели по умолчанию являются, скорее всего, субъективными, и решение о том, какой код считать некачественным, придется принимать самим программистам.
Для своих проектов я стараюсь для большинства методов поддерживать показатель MI около 70-90. Бывают методы, у которых этот показатель равен 50-60, и их можно переписать, но стоит оценивать затраты и выгоды.
Благодаря этому инструменту можно достаточно легко провести code review большого проекта, найти места, которые необходимо переписать. Также достаточно полезно следить за процессом изменения вышеописанных метрик. Это может показать руководителю об отношении программистов к разработке того или иного проекта, а также динамику изменения качества кода по каждому программисту, что немаловажно в нашей профессии. Другой причиной слежения за метриками, являются, определенные программистами, пороговые значения, при достижении которых, необходимо заняться рефакторингом.
Заключение
Метрики умеют показывать на проблемные участки кода, но если все метрики находятся в пределах нормы, то не обязательно код является качественным. Метод GeneratePDF, с зашкаливающей цикломатической сложностью, можно разбить на три, назвав их GeneratePDF1, GeneratePDF2 и GeneratePDF3. Метрика на уровне методов придет в норму, однако решение сильно рискует быть высмеянным на код-ревью. Соблюдение метрик никак не должно являться самоцелью. Цель метрик — помочь программисту увидеть проблему, которую нужно решать переосмыслением существующего кода, поиском лучшего алгоритма и выбором более элегантного решения проблемы.
Вау!! 😲 Ты еще не читал? Это зря!
- управление качеством программного обеспечения , надежность программного обеспечения , pum , метрики качества программного обеспечения ,
- типы тестирования , уровни тестирования ,
В общем, мой друг ты одолел чтение этой статьи об метрики кода. Работы в переди у тебя будет много. Смело пишикоментарии, развивайся и счастье окажется в ваших руках.
Надеюсь, что теперь ты понял что такое метрики кода, метрика программного обеспечения, исходящие зависимости, входящие зависимости, цикломатическая сложность, cyclomatic complexity
и для чего все это нужно, а если не понял, или есть замечания,
то нестесняся пиши или спрашивай в комментариях, с удовольствием отвечу. Для того чтобы глубже понять настоятельно рекомендую изучить всю информацию из категории
Проектирование веб сайта или программного обеспечения