
Время на прочтение
13 мин
Количество просмотров 75K

Введение
Ошибки, увы, неизбежны, поэтому их обработка занимает очень важное место в программировании. И если алгоритмические ошибки можно выявить и исправить во время написания и тестирования программы, то ошибок времени выполнения избежать нельзя в принципе. Сегодня мы рассмотрим функции стандартной библиотеки (C Standard Library) и POSIX, используемые в обработке ошибок.
Переменная errno и коды ошибок
<errno.h>
errno – переменная, хранящая целочисленный код последней ошибки. В каждом потоке существует своя локальная версия errno, чем и обусловливается её безопасность в многопоточной среде. Обычно errno реализуется в виде макроса, разворачивающегося в вызов функции, возвращающей указатель на целочисленный буфер. При запуске программы значение errno равно нулю.
Все коды ошибок имеют положительные значения, и могут использоваться в директивах препроцессора #if. В целях удобства и переносимости заголовочный файл <errno.h> определяет макросы, соответствующие кодам ошибок.
Стандарт ISO C определяет следующие коды:
- EDOM – (Error domain) ошибка области определения.
- EILSEQ – (Error invalid sequence) ошибочная последовательность байтов.
- ERANGE – (Error range) результат слишком велик.
Прочие коды ошибок (несколько десятков) и их описания определены в стандарте POSIX. Кроме того, в спецификациях стандартных функций обычно указываются используемые ими коды ошибок и их описания.
Нехитрый скрипт печатает в консоль коды ошибок, их символические имена и описания:
#!/usr/bin/perl
use strict;
use warnings;
use Errno;
foreach my $err (sort keys (%!)) {
$! = eval "Errno::$err";
printf "%20s %4d %sn", $err, $! + 0, $!
}
Если вызов функции завершился ошибкой, то она устанавливает переменную errno в ненулевое значение. Если же вызов прошёл успешно, функция обычно не проверяет и не меняет переменную errno. Поэтому перед вызовом функции её нужно установить в 0.
Пример:
/* convert from UTF16 to UTF8 */
errno = 0;
n_ret = iconv(icd, (char **) &p_src, &n_src, &p_dst, &n_dst);
if (n_ret == (size_t) -1) {
VJ_PERROR();
if (errno == E2BIG)
fprintf(stderr, " Error : input conversion stopped due to lack of space in the output buffern");
else if (errno == EILSEQ)
fprintf(stderr, " Error : input conversion stopped due to an input byte that does not belong to the input codesetn");
else if (errno == EINVAL)
fprintf(stderr, " Error : input conversion stopped due to an incomplete character or shift sequence at the end of the input buffern");
/* clean the memory */
free(p_out_buf);
errno = 0;
n_ret = iconv_close(icd);
if (n_ret == (size_t) -1)
VJ_PERROR();
return (size_t) -1;
}
Как видите, описания ошибок в спецификации функции iconv() более информативны, чем в <errno.h>.
Функции работы с errno
Получив код ошибки, хочется сразу получить по нему её описание. К счастью, ISO C предлагает целый набор полезных функций.
<stdio.h>
void perror(const char *s);
Печатает в stderr содержимое строки s, за которой следует двоеточие, пробел и сообщение об ошибке. После чего печатает символ новой строки 'n'.
Пример:
/*
// main.c
// perror example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
if (file) {
// Do something useful.
fclose(file);
}
else {
perror("fopen() ");
}
return EXIT_SUCCESS;
}<string.h>
char* strerror(int errnum);
Возвращает строку, содержащую описание ошибки errnum. Язык сообщения зависит от локали (немецкий, иврит и даже японский), но обычно поддерживается лишь английский.
/*
// main.c
// strerror example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
char *errorbuf = strerror(error_num);
fprintf(stderr, "Error message : %sn", errorbuf);
}
return EXIT_SUCCESS;
}strerror() не безопасная функция. Во-первых, возвращаемая ею строка не является константной. При этом она может храниться в статической или в динамической памяти в зависимости от реализации. В первом случае её изменение приведёт к ошибке времени выполнения. Во-вторых, если вы решите сохранить указатель на строку, и после вызовите функцию с новым кодом, все прежние указатели будут указывать уже на новую строку, ибо она использует один буфер для всех строк. В-третьих, её поведение в многопоточной среде не определено в стандарте. Впрочем, в QNX она объявлена как thread safe.
Поэтому в новом стандарте ISO C11 были предложены две очень полезные функции.
size_t strerrorlen_s(errno_t errnum);
Возвращает длину строки с описанием ошибки errnum.
errno_t strerror_s(char *buf, rsize_t buflen, errno_t errnum);
Копирует строку с описание ошибки errnum в буфер buf длиной buflen.
Пример:
/*
// main.c
// strerror_s example
//
// Created by Ariel Feinerman on 23/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#define __STDC_WANT_LIB_EXT1__ 1
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
#ifdef __STDC_LIB_EXT1__
size_t error_len = strerrorlen_s(errno) + 1;
char error_buf[error_len];
strerror_s(error_buf, error_len, errno);
fprintf(stderr, "Error message : %sn", error_buf);
#endif
}
return EXIT_SUCCESS;
}Функции входят в Annex K (Bounds-checking interfaces), вызвавший много споров. Он не обязателен к выполнению и целиком не реализован ни в одной из свободных библиотек. Open Watcom C/C++ (Windows), Slibc (GNU libc) и Safe C Library (POSIX), в последней, к сожалению, именно эти две функции не реализованы. Тем не менее, их можно найти в коммерческих средах разработки и системах реального времени, Embarcadero RAD Studio, INtime RTOS, QNX.
Стандарт POSIX.1-2008 определяет следующие функции:
char *strerror_l(int errnum, locale_t locale);
Возвращает строку, содержащую локализованное описание ошибки errnum, используя locale. Безопасна в многопоточной среде. Не реализована в Mac OS X, FreeBSD, NetBSD, OpenBSD, Solaris и прочих коммерческих UNIX. Реализована в Linux, MINIX 3 и Illumos (OpenSolaris).
Пример:
/*
// main.c
// strerror_l example – works on Linux, MINIX 3, Illumos
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#include <locale.h>
int main(int argc, const char * argv[])
{
locale_t locale = newlocale(LC_ALL_MASK, "fr_FR.UTF-8", (locale_t) 0);
if (!locale) {
fprintf(stderr, "Error: cannot create locale.");
exit(EXIT_FAILURE);
}
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(tmpnam(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
char *error_buf = strerror_l(errno, locale);
fprintf(stderr, "Error message : %sn", error_buf);
}
freelocale(locale);
return EXIT_SUCCESS;
}Вывод:
Error message : Aucun fichier ou dossier de ce typeint strerror_r(int errnum, char *buf, size_t buflen);
Копирует строку с описание ошибки errnum в буфер buf длиной buflen. Если buflen меньше длины строки, лишнее обрезается. Безопасна в многоготочной среде. Реализована во всех UNIX.
Пример:
/*
// main.c
// strerror_r POSIX example
//
// Created by Ariel Feinerman on 25/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define MSG_LEN 1024
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
char error_buf[MSG_LEN];
errno_t error = strerror_r (error_num, error_buf, MSG_LEN);
switch (error) {
case EINVAL:
fprintf (stderr, "strerror_r() failed: invalid error code, %dn", error);
break;
case ERANGE:
fprintf (stderr, "strerror_r() failed: buffer too small: %dn", MSG_LEN);
case 0:
fprintf(stderr, "Error message : %sn", error_buf);
break;
default:
fprintf (stderr, "strerror_r() failed: unknown error, %dn", error);
break;
}
}
return EXIT_SUCCESS;
}
Увы, никакого аналога strerrorlen_s() в POSIX не определили, поэтому длину строки можно выяснить лишь экспериментальным путём. Обычно 300 символов хватает за глаза. GNU C Library в реализации strerror() использует буфер длиной в 1024 символа. Но мало ли, а вдруг?
Пример:
/*
// main.c
// strerror_r safe POSIX example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
#define MSG_LEN 1024
#define MUL_FACTOR 2
int main(int argc, const char * argv[])
{
// Generate unique filename.
char *file_name = tmpnam((char[L_tmpnam]){0});
errno = 0;
FILE *file = fopen(file_name, "rb");
// Save error number.
errno_t error_num = errno;
if (file) {
// Do something useful.
fclose(file);
}
else {
errno_t error = 0;
size_t error_len = MSG_LEN;
do {
char error_buf[error_len];
error = strerror_r (error_num, error_buf, error_len);
switch (error) {
case 0:
fprintf(stderr, "File : %snLine : %dnCurrent function : %s()nFailed function : %s()nError message : %sn", __FILE__, __LINE__, __func__, "fopen", error_buf);
break;
case ERANGE:
error_len *= MUL_FACTOR;
break;
case EINVAL:
fprintf (stderr, "strerror_r() failed: invalid error code, %dn", error_num);
break;
default:
fprintf (stderr, "strerror_r() failed: unknown error, %dn", error);
break;
}
} while (error == ERANGE);
}
return EXIT_SUCCESS;
}Вывод:
File : /Users/ariel/main.c
Line : 47
Current function : main()
Failed function : fopen()
Error message : No such file or directoryМакрос assert()
<assert.h>
void assert(expression)
Макрос, проверяющий условие expression (его результат должен быть числом) во время выполнения. Если условие не выполняется (expression равно нулю), он печатает в stderr значения __FILE__, __LINE__, __func__ и expression в виде строки, после чего вызывает функцию abort().
/*
// main.c
// assert example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <math.h>
int main(int argc, const char * argv[]) {
double x = -1.0;
assert(x >= 0.0);
printf("sqrt(x) = %fn", sqrt(x));
return EXIT_SUCCESS;
}Вывод:
Assertion failed: (x >= 0.0), function main, file /Users/ariel/main.c, line 17.
Если макрос NDEBUG определён перед включением <assert.h>, то assert() разворачивается в ((void) 0) и не делает ничего. Используется в отладочных целях.
Пример:
/*
// main.c
// assert_example
//
// Created by Ariel Feinerman on 23/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#NDEBUG
#include <stdio.h>
#include <stdlib.h>
#include <assert.h>
#include <math.h>
int main(int argc, const char * argv[]) {
double x = -1.0;
assert(x >= 0.0);
printf("sqrt(x) = %fn", sqrt(x));
return EXIT_SUCCESS;
}Вывод:
sqrt(x) = nanФункции atexit(), exit() и abort()
<stdlib.h>
int atexit(void (*func)(void));
Регистрирует функции, вызываемые при нормальном завершении работы программы в порядке, обратном их регистрации. Можно зарегистрировать до 32 функций.
_Noreturn void exit(int exit_code);
Вызывает нормальное завершение программы, возвращает в среду число exit_code. ISO C стандарт определяет всего три возможных значения: 0, EXIT_SUCCESS и EXIT_FAILURE. При этом вызываются функции, зарегистрированные через atexit(), сбрасываются и закрываются потоки ввода — вывода, уничтожаются временные файлы, после чего управление передаётся в среду. Функция exit() вызывается в main() при выполнении return или достижении конца программы.
Главное преимущество exit() в том, что она позволяет завершить программу не только из main(), но и из любой вложенной функции. К примеру, если в глубоко вложенной функции выполнилось (или не выполнилось) некоторое условие, после чего дальнейшее выполнение программы теряет всякий смысл. Подобный приём (early exit) широко используется при написании демонов, системных утилит и парсеров. В интерактивных программах с бесконечным главным циклом exit() можно использовать для выхода из программы при выборе нужного пункта меню.
Пример:
/*
// main.c
// exit example
//
// Created by Ariel Feinerman on 17/03/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
void third_2(void)
{
printf("third #2n"); // Does not print.
}
void third_1(void)
{
printf("third #1n"); // Does not print.
}
void second(double num)
{
printf("second : before exit()n"); // Prints.
if ((num < 1.0f) && (num > -1.0f)) {
printf("asin(%.1f) = %.3fn", num, asin(num));
exit(EXIT_SUCCESS);
}
else {
fprintf(stderr, "Error: %.1f is beyond the range [-1.0; 1.0]n", num);
exit(EXIT_FAILURE);
}
printf("second : after exit()n"); // Does not print.
}
void first(double num)
{
printf("first : before second()n")
second(num);
printf("first : after second()n"); // Does not print.
}
int main(int argc, const char * argv[])
{
atexit(third_1); // Register first handler.
atexit(third_2); // Register second handler.
first(-3.0f);
return EXIT_SUCCESS;
}Вывод:
first : before second()
second : before exit()
Error: -3.0 is beyond the range [-1.0; 1.0]
third #2
third #1_Noreturn void abort(void);
Вызывает аварийное завершение программы, если сигнал не был перехвачен обработчиком сигналов. Временные файлы не уничтожаются, закрытие потоков определяется реализацией. Самое главное отличие вызовов abort() и exit(EXIT_FAILURE) в том, что первый посылает программе сигнал SIGABRT, его можно перехватить и произвести нужные действия перед завершением программы. Записывается дамп памяти программы (core dump file), если они разрешены. При запуске в отладчике он перехватывает сигнал SIGABRT и останавливает выполнение программы, что очень удобно в отладке.
Пример:
/*
// main.c
// abort example
//
// Created by Ariel Feinerman on 17/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
void third_2(void)
{
printf("third #2n"); // Does not print.
}
void third_1(void)
{
printf("third #1n"); // Does not print.
}
void second(double num)
{
printf("second : before exit()n"); // Prints.
if ((num < 1.0f) && (num > -1.0f)) {
printf("asin(%.1f) = %.3fn", num, asin(num));
exit(EXIT_SUCCESS);
}
else {
fprintf(stderr, "Error: %.1f is beyond the range [-1.0; 1.0]n", num);
abort();
}
printf("second : after exit()n"); // Does not print.
}
void first(double num)
{
printf("first : before second()n");
second(num);
printf("first : after second()n"); // Does not print.
}
int main(int argc, const char * argv[])
{
atexit(third_1); // register first handler
atexit(third_2); // register second handler
first(-3.0f);
return EXIT_SUCCESS;
}Вывод:
first : before second()
second : before exit()
Error: -3.0 is beyond the range [-1.0; 1.0]
Abort trap: 6Вывод в отладчике:
$ lldb abort_example
(lldb) target create "abort_example"
Current executable set to 'abort_example' (x86_64).
(lldb) run
Process 22570 launched: '/Users/ariel/abort_example' (x86_64)
first : before second()
second : before exit()
Error: -3.0 is beyond the range [-1.0; 1.0]
Process 22570 stopped
* thread #1: tid = 0x113a8, 0x00007fff89c01286 libsystem_kernel.dylib`__pthread_kill + 10, queue = 'com.apple.main-thread', stop reason = signal SIGABRT
frame #0: 0x00007fff89c01286 libsystem_kernel.dylib`__pthread_kill + 10
libsystem_kernel.dylib`__pthread_kill:
-> 0x7fff89c01286 <+10>: jae 0x7fff89c01290 ; <+20>
0x7fff89c01288 <+12>: movq %rax, %rdi
0x7fff89c0128b <+15>: jmp 0x7fff89bfcc53 ; cerror_nocancel
0x7fff89c01290 <+20>: retq
(lldb)
В случае критической ошибки нужно использовать функцию abort(). К примеру, если при выделении памяти или записи файла произошла ошибка. Любые дальнейшие действия могут усугубить ситуацию. Если завершить выполнение обычным способом, при котором производится сброс потоков ввода — вывода, можно потерять ещё неповрежденные данные и временные файлы, поэтому самым лучшим решением будет записать дамп и мгновенно завершить программу.
В случае же некритической ошибки, например, вы не смогли открыть файл, можно безопасно выйти через exit().
Функции setjmp() и longjmp()
Вот мы и подошли к самому интересному – функциям нелокальных переходов. setjmp() и longjmp() работают по принципу goto, но в отличие от него позволяют перепрыгивать из одного места в другое в пределах всей программы, а не одной функции.
<setjmp.h>
int setjmp(jmp_buf env);
Сохраняет информацию о контексте выполнения программы (регистры микропроцессора и прочее) в env. Возвращает 0, если была вызвана напрямую или value, если из longjmp().
void longjmp(jmp_buf env, int value);
Восстанавливает контекст выполнения программы из env, возвращает управление setjmp() и передаёт ей value.
Пример:
/*
// main.c
// setjmp simple
//
// Created by Ariel Feinerman on 18/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <setjmp.h>
static jmp_buf buf;
void second(void)
{
printf("second : before longjmp()n"); // prints
longjmp(buf, 1); // jumps back to where setjmp was called – making setjmp now return 1
printf("second : after longjmp()n"); // does not prints
// <- Here is the point that is never reached. All impossible cases like your own house in Miami, your million dollars, your nice girl, etc.
}
void first(void)
{
printf("first : before second()n");
second();
printf("first : after second()n"); // does not print
}
int main(int argc, const char * argv[])
{
if (!setjmp(buf))
first(); // when executed, setjmp returned 0
else // when longjmp jumps back, setjmp returns 1
printf("mainn"); // prints
return EXIT_SUCCESS;
}Вывод:
first : before second()
second : before longjmp()
main
Используя setjmp() и longjmp() можно реализовать механизм исключений. Во многих языках высокого уровня (например, в Perl) исключения реализованы через них.
Пример:
/*
// main.c
// exception simple
//
// Created by Ariel Feinerman on 18/02/17.
// Copyright 2017 Feinerman Research, Inc. All rights reserved.
*/
#include <stdio.h>
#include <stdlib.h>
#include <math.h>
#include <setjmp.h>
#define str(s) #s
static jmp_buf buf;
typedef enum {
NO_EXCEPTION = 0,
RANGE_EXCEPTION = 1,
NUM_EXCEPTIONS
} exception_t;
static char *exception_name[NUM_EXCEPTIONS] = {
str(NO_EXCEPTION),
str(RANGE_EXCEPTION)
};
float asin_e(float num)
{
if ((num < 1.0f) && (num > -1.0f)) {
return asinf(num);
}
else {
longjmp(buf, RANGE_EXCEPTION); // | @throw
}
}
void do_work(float num)
{
float res = asin_e(num);
printf("asin(%f) = %fn", num, res);
}
int main(int argc, const char * argv[])
{
exception_t exc = NO_EXCEPTION;
if (!(exc = setjmp(buf))) { // |
do_work(-3.0f); // | @try
} // |
else { // |
fprintf(stderr, "%s was hadled in %s()n", exception_name[exc], __func__); // | @catch
} // |
return EXIT_SUCCESS;
}Вывод:
RANGE_EXCEPTION was hadled in main()
Внимание! Функции setjmp() и longjmp() в первую очередь применяются в системном программировании, и их использование в клиентском коде не рекомендуется. Их применение ухудшает читаемость программы и может привести к непредсказуемым ошибкам. Например, что произойдёт, если вы прыгните не вверх по стеку – в вызывающую функцию, а в параллельную, уже завершившую выполнение?
Информация
- стандарт ISO/IEC C (89/99/11)
- Single UNIX Specifcation, Version 4, 2016 Edition
- The Open Group Base Specifcations Issue 7, 2016 Edition (POSIX.1-2008)
- SEI CERT C Coding Standard
- cправочная информация среды программирования
- справочная информация операционной системы (man pages)
- заголовочные файлы (/usr/include)
- исходные тексты библиотеки (C Standard Library)
Теория
кодирования занимается проблемами
построения разнообразных кодов. При
этом для конкретного класса кодов
решаются три основные задачи: 1) код
должен корректировать заданный класс
ошибок; 2) процедуры кодирования и
декодирования должны быть формализованы,
т. е. выполняться по определенным
правилам; 3) схемы кодирования и
декодирования должны быть простыми.
Рассмотрим
наиболее распространенные коды с
обнаружением ошибок. Каждый такой код
должен обнаруживать все одиночные
ошибки как наиболее вероятные. Кроме
того, он может и исправлять некоторые
ошибки.
Код
с контролем на четность.(1а) У
этого кода все разрешенные кодовые
слова содержат четное число единиц. Для
его формирования к обыкновенному
коду достаточно добавить один избыточный
контрольный разряд.
Пусть
надо передать S
= 4 сообщения. Тогда обыкновенный код
имеет два разряда, которые несут
информацию, а третий контрольный разряд
определяется исходя из четности числа
единиц в слове:
123
000 011 101
110 (столбик)
Такой
код, у которого разряды делятся на
информационные, служащие для передачи
сообщения, и контрольные (избыточные),
служащие для коррекции ошибок, называется
разделимым.
 1а
1а
Равновесный
код (код с постоянным числом единиц). У
этого кода
все кодовые слова имеют постоянное
число единиц. Поэтому его еще называют
кодом «т
из
п»,
так
как каждое слово имеет т
единиц
из п
разрядов.
Число т
называют
весом
кода.
S=Cm,n
Корреляционные
коды. У этих кодов существует зависимость
(корреляция) между определенными
элементами кода. Примером является код
с повторением, у которого каждое слово
обыкновенного кода повторяется
дважды. Ниже приведен данный код для
передачи S
= 4 сообщений:
-
1
2
3
4
0
0
0
0
0
1
0
1
1
0
1
0
1
1 1 1
Он
является разделимым. Первый и второй
разряды можно считать информационными,
а третий и четвертый — контрольными.
34
Код
с суммированием (код Бергера). Этот
код позволяет обна руживать однонаправленные
ошибки любой кратности. Однонаправленным
назыв-ся кратные
Ошибки,
содержащие только искажения вида 1-0 или
0-1.код применяется в тех случаях,
Когда
в канале свзи возникают помехи,
длительность которых больше длительности
одного импульса тока.
35
11.5. Код Хемминга
Среди
кодов с исправлением ошибок наибольшее
распространение на практике имеет
код Хэмминга. Код
Хэмминга исправляет
ошибки кратности 1 и является разделимым.
Число информационных разрядов т
=
]log2N[,
где N
—
число сообщений, которые необходимо
передать. Длина кода определяется из
неравенства (11.14).
41
12.4.
Программируемые
распределители
Распределители,
работающие с использованием двоичного
кода,
имеют
2п
позиций.
Это число в системе ТУ — ТС обычно должно
быть равно длине используемого кода.
Поэтому возникает задача построения
распределителя (а фактически счетчика)
с модулем счета не равным 2″ Такие
распределители называют программируемыми.
42
Генераторы
в системах ТУ — ТС используются для
выполнения
двух
функций. Тактовые генераторы определяют
временное такты функционирования
системы. Они управляют работой счетчика
или распределителя и обеспечивают
синхронизацию. Генераторы качеств
формируют импульсы тока с определенным
качеством и воздействуют на линейные
устройства.
Генератором
называется
устройство, которое благодаря энергии
непериодического источника питания
создает периодически изменяющееся
электрическое напряжение или ток и
обеспечивает периодическое замыкание
и размыкание электрической цепи (1а).

В
зависимости от формы генерируемых
импульсов различают генераторы
синусоидальных колебаний (1 б) и
релаксационные генераторы. Последние
генерируют импульсы специальной
формы с наличием скачков — прямоугольные,
экспоненциальные, пилообразные (1 в,
г, д) и
др. При этом импульсные последовательности
характеризуются длительностями импульса
tи
и
паузы tn,
периодом
колебаний T
= tи
+tn,
частотой
следования f
= 1/Т
и
скважностью Q
=
T/tп.
Простейший
тактовый генератор (2 а)состоит из
источника питания ИП,
устройства
управления УУ,
накопителя
энергии Я и обратной связи ОС. В качестве
У
У используется
переключательный элемент (реле,
транзистор, тиристор и т. п.). Накопителем
энергии обычно служит конденсатор.

Пример
релейно-контактного генератора
(пульс-пара) рассмотрен в п. 5.3.
В
бесконтактной технике аналогами
пульс-пары являются мультивибраторы.
Простейшая схема мультивибратора
состоит из двух инверторов с емкостными
обратными связями (3а).
При
включении питания эта схема оказывается
в состоянии неустойчивого равновесия,
когда оба транзистора открыты с некоторой
степенью насыщения. Возрастание
коллекторного тока iК2
транзистора VT2
приводит
к увеличению тока заряда tc1
и увеличению падения напряжения на
резисторе Rb1.
В результате потенциал базы транзистора
VT1
становится более положительным и
уменьшается ток iK1.
Потенциал коллектора транзистора VT1
становится
более отрицательным и поэтому увеличивается
ток заряда ic2.
Так как последний является базовым
током транзистора VT2,
то
возрастает ток iK2
и
снова возрастает ток гс!
и т. д. Описанный процесс приводит к
тому, что транзистор VT2
полностью
открывается, а транзистор VT1
полностью
закрывается. Это состояние схемы также
неустойчиво, так как продолжается заряд
конденсатора С1 и ток icl
начинает уменьшаться. Снижается падение
напряжения на резисторе Rb1,
потенциал
базы транзистора VT1
становится
более отрицательным. При некотором
значении этого потенциала транзистор
VT1
начинает
открываться, возрастает его ток iK1
и
процесс протекает в обратную сторону.
На выходе схемы формируются импульсы
(3б), частота следования которых
определяется постоянной времени R6C.

44
Добавлено 30 мая 2021 в 21:14
В уроке «7.14 – Распространенные семантические ошибки при программировании на C++» мы рассмотрели многие типы распространенных семантических ошибок, с которыми сталкиваются начинающие программисты при работе с языком C++. Если ошибка является результатом неправильного использования языковой функции или логической ошибки, исправить ее можно просто.
Но большинство ошибок в программе возникает не в результате непреднамеренного неправильного использования языковых функций – скорее, большинство ошибок возникает из-за ошибочных предположений, сделанных программистом, и/или из-за отсутствия надлежащего обнаружения/обработки ошибок.
Например, в функции, предназначенной для поиска оценки учащегося, вы могли предположить, что:
- просматриваемый студент будет существовать;
- имена всех студентов будут уникальными;
- в предмете используется числовая оценка (вместо «зачет/незачет»).
Что, если какое-либо из этих предположений неверно? Если программист не предвидел этих случаев, программа при возникновении таких случаев, скорее всего, завершится со сбоем (обычно в какой-то момент в будущем, через долгое время после того, как функция была написана).
Есть три ключевых места, где обычно возникают ошибки предположений:
- Когда функция возвращает значение, программист мог предположить, что вызов функции будет успешным, хотя это не так.
- Когда программа получает входные данные (либо от пользователя, либо из файла), программист мог предположить, что ввод будет в правильном формате и семантически корректен, хотя это не так.
- Когда функция была вызвана, программист мог предположить, что параметры будут семантически допустимыми, хотя это не так.
Многие начинающие программисты пишут код, а затем проверяют только счастливый путь: только те случаи, когда ошибок нет. Но вы также должны планировать и проверять печальные пути, на которых что-то может пойти и пойдет не так. В уроке «3.10 – Поиск проблем до того, как они станут проблемами», мы определили защитное программирование как попытку предвидеть все способы неправильного использования программного обеспечения конечными пользователями или разработчиками (либо самим программистом, либо другими). Как только вы ожидаете (или обнаруживаете) какое-то неправильное использование, следующее, что вам нужно сделать, – это обработать его.
В этом уроке мы поговорим о стратегиях обработки ошибок (что делать, если что-то пойдет не так) внутри функции. В следующих уроках мы поговорим о проверке ввода данных пользователем, а затем представим полезный инструмент, помогающий документировать и проверять предположения.
Обработка ошибок в функциях
Функции могут давать сбой по любому количеству причин – вызывающий мог передать аргумент с недопустимым значением, или что-то может дать сбой в теле функции. Например, функция, открывающая файл для чтения, может не работать, если файл не может быть найден.
Когда это произойдет, в вашем распоряжении будет несколько вариантов. Лучшего способа справиться с ошибкой нет – это на самом деле зависит от характера проблемы и от того, можно ли устранить проблему или нет.
Можно использовать 4 основные стратегии:
- обработать ошибку в функции;
- передать ошибку вызывающему, чтобы он разобрался с ней;
- остановить программу;
- выбросить исключение.
Обработка ошибки в функции
Если возможно, наилучшей стратегией является восстановление после ошибки в той же функции, в которой возникла ошибка, так, чтобы ошибку можно было локализовать и исправить, не влияя на какой-либо код вне функции. Здесь есть два варианта: повторять попытки до успешного завершения или отменить выполняемую операцию.
Если ошибка возникла из-за чего-то, не зависящего от программы, программа может повторять попытку, пока не будет достигнут успех. Например, если программе требуется подключение к Интернету, и пользователь потерял соединение, программа может отобразить предупреждение, а затем использовать цикл для периодической повторной проверки подключения к Интернету. В качестве альтернативы, если пользователь ввел недопустимые входные данные, программа может попросить пользователя повторить попытку и выполнять этот цикл до тех пор, пока пользователь не введет корректные входные данные. Мы покажем примеры обработки недопустимого ввода и использования циклов для повторных попыток в следующем уроке (7.16 – std::cin и обработка недопустимого ввода).
Альтернативная стратегия – просто игнорировать ошибку и/или отменить операцию. Например:
void printDivision(int x, int y)
{
if (y != 0)
std::cout << static_cast<double>(x) / y;
}В приведенном выше примере, если пользователь ввел недопустимое значение для y, мы просто игнорируем запрос на печать результата операции деления. Основная проблема при этом заключается в том, что у вызывающей функции или у пользователя нет возможности определить, что что-то пошло не так. В таком случае может оказаться полезным напечатать сообщение об ошибке:
void printDivision(int x, int y)
{
if (y != 0)
std::cout << static_cast<double>(x) / y;
else
std::cerr << "Error: Could not divide by zeron";
}Однако если вызывающая функция ожидает, что вызываемая функция выдаст возвращаемое значение или какой-либо полезный побочный эффект, тогда просто игнорирование ошибки может быть недопустимым вариантом.
Передача ошибок вызывающей функции
Во многих случаях обработать ошибку с помощью функции, которая ее обнаруживает, невозможно. Например, рассмотрим следующую функцию:
double doDivision(int x, int y)
{
return static_cast<double>(x) / y;
}Если y равно 0, что нам делать? Мы не можем просто пропустить логику программы, потому что функция должна возвращать какое-то значение. Мы не должны просить пользователя ввести новое значение для y, потому что это функция вычисления, и введение в нее процедур ввода может быть или не быть подходящим для программы, вызывающей эту функцию.
В таких случаях лучшим вариантом может быть передача ошибки обратно вызывающей функции в надежде, что вызывающая сторона сможет с ней справиться.
Как мы можем это сделать?
Если функция имеет тип возвращаемого значения void, его можно изменить, чтобы она возвращала логическое значение, указывающее на успех или на неудачу. Например, вместо:
void printDivision(int x, int y)
{
if (y != 0)
std::cout << static_cast<double>(x) / y;
else
std::cerr << "Error: Could not divide by zeron";
}Мы можем сделать так:
bool printDivision(int x, int y)
{
if (y == 0)
{
std::cerr << "Error: could not divide by zeron";
return false;
}
std::cout << static_cast<double>(x) / y;
return true;
}Таким образом, вызывающий может проверить возвращаемое значение, чтобы узнать, не завершилась ли функция по какой-либо причине неудачей.
Если функция возвращает обычное значение, всё немного сложнее. В некоторых случаях полный диапазон возвращаемых значений не используется. В таких случаях, чтобы указать на ошибку, мы можем использовать возвращаемое значение, которое иначе было бы невозможно. Например, рассмотрим следующую функцию:
// Обратное (reciprocal) к x равно 1/x
double reciprocal(double x)
{
return 1.0 / x;
}Обратное к некоторому числу x определяется как 1/x, а число, умноженное на обратное, равно 1.
Однако что произойдет, если пользователь вызовет эту функцию как reciprocal(0.0)? Мы получаем ошибку деления на ноль и сбой программы, поэтому очевидно, что мы должны защититься от этого случая. Но эта функция должна возвращать значение doube, так какое же значение мы должны вернуть? Оказывается, эта функция никогда не выдаст 0.0 как допустимый результат, поэтому мы можем вернуть 0.0, чтобы указать на случай ошибки.
// Обратное (reciprocal) к x равно 1/x; возвращает 0.0, если x=0
double reciprocal(double x)
{
if (x == 0.0)
return 0.0;
return 1.0 / x;
}Однако если требуется полный диапазон возвращаемых значений, то использование возвращаемого значения для указания ошибки будет невозможно (поскольку вызывающий не сможет определить, является ли возвращаемое значение допустимым значением или значением ошибки). В таком случае выходной параметр (рассмотренный в уроке «11.3 – Передача аргументов по ссылке») может быть жизнеспособным вариантом.
Фатальные ошибки
Если ошибка настолько серьезна, что программа не может продолжать работать правильно, она называется неисправимой ошибкой (или фатальной ошибкой). В таких случаях лучше всего завершить программу. Если ваш код находится в main() или в функции, вызываемой непосредственно из main(), лучше всего позволить main() вернуть ненулевой код состояния. Однако если вы погрузились в какую-то глубоко вложенную подфункцию, передать ошибку обратно в main() может быть неудобно или невозможно. В таком случае можно использовать инструкцию остановки (например, std::exit()).
Например:
double doDivision(int x, int y)
{
if (y == 0)
{
std::cerr << "Error: Could not divide by zeron";
std::exit(1);
}
return static_cast<double>(x) / y;
}Исключения
Поскольку возврат ошибки из функции обратно вызывающей функции сложен (и множество различных способов сделать это приводит к несогласованности, а несогласованность ведет к ошибкам), C++ предлагает совершенно отдельный способ передачи ошибок обратно вызывающей стороне: исключения.
Основная идея состоит в том, что при возникновении ошибки «выбрасывается» исключение. Если текущая функция не «улавливает» ошибку, то уловить ошибку есть шанс у вызывающей функции. Если вызывающая функция не обнаруживает ошибку, то обнаружить ошибку есть шанс у функции, вызвавшей вызывающую функцию. Ошибка постепенно перемещается вверх по стеку вызовов до тех пор, пока она не будет обнаружена и обработана (в этот момент выполнение продолжается в обычном режиме), или пока main() не сможет обработать ошибку (в этот момент программа завершится с ошибкой исключения).
Мы рассмотрим обработку исключений в главе 20 этой серии обучающих статей.
Теги
C++ / CppException / ИсключениеLearnCppstd::exit()Для начинающихОбнаружение ошибокОбработка ошибокОбучениеПрограммирование
Коды с обнаружением
ошибок
1.
Код с проверкой на четность.
Такой
код образуется путем добавления к
передаваемой комбинации, состоящей из k
информационных символов, одного
контрольного символа (0 или 1), так, чтобы
общее число единиц в передаваемой
комбинации было четным.
Пример
5.1.
Построим коды для проверки на четность, где k
—
исходные комбинации, r
—
контрольные символы.
| k |
r
|
n
|
| 11011 |
0 |
110110 |
| 11100 |
1 |
111001
|
Определим, каковы обнаруживающие свойства
этого кода. Вероятность Poo
обнаружения ошибок будет равна
![]()
Так как вероятность ошибок
![]()
является
весьма малой величиной, то можно
ограничится
![]()
Вероятность
появления всевозможных ошибок, как
обнаруживаемых так и не обнаруживаемых,
равна
![]()
,
где
![]()
—
вероятность отсутствия искажений в кодовой
комбинации. Тогда
![]()
.
При
передаче большого количества кодовых
комбинаций Nk
, число кодовых
комбинаций, в которых ошибки
обнаруживаются, равно:
![]()
Общее
количество комбинаций с обнаруживаемыми и
не обнаруживаемыми ошибками равно
![]()
Тогда
коэффициент обнаружения Kобн
для кода с четной защитой будет равен
![]()
Например,
для кода с k=5
и вероятностью ошибки
![]()
коэффициент
обнаружения составит
![]()
. То есть 90% ошибок
обнаруживаем, при этом избыточность будет
составлять
![]()
или
17%.
2.
Код с
постоянным весом.
Этот
код содержит постоянное число единиц и
нулей. Число кодовых комбинаций составит
![]()
Пример 5.2. Коды с двумя единицами из пяти и
тремя единицами из семи.
| 11000 10010 00101 |
0000111 1001001 1010100 |
Этот код позволяет обнаруживать любые
одиночные ошибки и часть многократных
ошибок. Не обнаруживаются этим кодом только
ошибки смещения, когда одновременно одна
единица переходит в ноль и один ноль
переходит в единицу, два ноля и две единицы
меняются на обратные символы и т.д.
Рассмотрим
код с тремя единицами из семи. Для этого
кода возможны смещения трех типов.
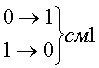
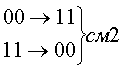
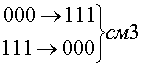
Вероятность появления
не обнаруживаемых ошибок смещения
![]()
, где
![]()
![]()
![]()
При
p<<1
![]()
, тогда
![]()
Вероятность
появления всевозможных ошибок как
обнаруживаемых, так и не обнаруживаемых
будет составлять
![]()
Вероятность
обнаруживаемых ошибок
![]()
. Тогда
коэффициент обнаружения будет равен
![]()
Например,
код
![]()
при
![]()
коэффициент обнаружения составит
![]()
,
избыточность L=27%.
3.
Корреляционный код
(Код с удвоением). Элементы
данного кода заменяются двумя символами,
единица ‘1’ преобразуется в 10, а ноль ‘0’ в
01.
Вместо комбинации 1010011
передается 10011001011010.
Ошибка обнаруживается в том случае, если в
парных элементах будут одинаковые символы
00 или 11 (вместо 01 и 10).
Например,
при k=5,
n=10
и вероятности ошибки
![]()
,
![]()
.
Но при этом избыточность будет
составлять 50%.
4.
Инверсный код. К
исходной комбинации добавляется такая же
комбинация по длине. В линию посылается
удвоенное число символов. Если в исходной
комбинации четное число единиц, то
добавляемая комбинация повторяет исходную
комбинацию, если нечетное, то добавляемая
комбинация является инверсной по отношению
к исходной.
| k |
r
|
n
|
| 11011 |
11011 |
1101111011 |
| 11100 |
00011 |
1110000011 |
Прием
инверсного кода осуществляется в два этапа.
На первом этапе суммируются единицы в
первой основной группе символов. Если число
единиц четное, то контрольные символы
принимаются без изменения, если нечетное,
то контрольные символы инвертируются. На
втором этапе контрольные символы
суммируются с информационными символами по
модулю два. Нулевая сумма говорит об
отсутствии ошибок. При ненулевой сумме,
принятая комбинация бракуется. Покажем
суммирование для принятых комбинаций без
ошибок (1,3) и с ошибками (2,4).
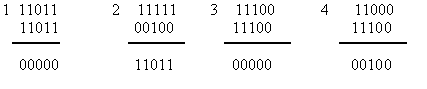
Обнаруживающие способности
данного кода достаточно велики. Данный код
обнаруживает практически любые ошибки,
кроме редких ошибок смещения, которые
одновременно происходят как среди
информационных символов, так и среди
соответствующих контрольных. Например, при k=5, n=10
и
![]()
. Коэффициент обнаружения будет
составлять
![]()
.
5.
Код Грея.
Код Грея используется для
преобразования угла поворота тела вращения
в код. Принцип
работы можно представить по рис.5.2. На
пластине, которая вращается на
валу, сделаны отверстия, через
которые может
проходить свет.
Причём, диск разбит
на сектора, в
которых и
сделаны эти
отверстия. При вращении, свет
проходит через
них, что приводит
к срабатыванию фотоприёмников. При
снятии информации в виде двоичных кодов
может произойти существенная ошибка.
Например, возьмем две соседние цифры 7 и 8.
Двоичные коды этих цифр отличаются во всех
разрядах.
7 0111
—> 1111
8 1000
—>
0000
Если ошибка произойдет в старшем разряде,
то это приведет к максимальной ошибке, на 3600.
А код Грея,
это такой код в котором все соседние
комбинации отличаются только одним
символом, поэтому при переходе от
изображения одного числа к изображению
соседнего происходит изменение только на
единицу младшего разряда. Ошибка будет
минимальной.
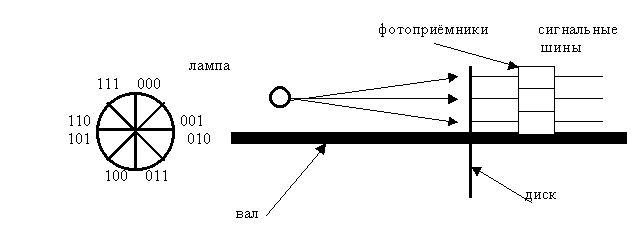
Рис.5.2. Схема съема
информации угла поворота вала в код
Код Грея
записывается следующим образом
| Номер |
Код Грея |
| 0 |
0 0 0 0 |
| 1 |
0 0 0 1 |
| 2 |
0 0 1 1 |
| 3 |
0 0 1 0 |
| 4 |
0 1 1 0 |
| 5 | 0 1 1 1 |
| 6 |
0 1 0 1 |
| 7 |
0 1 0 0 |
| 8 |
1 1 0 0 |
| 9 |
1 1 0 1 |
| 10 |
1 1 1 1 |
| 11 |
1 1 1 0 |
| 12 |
1 0 1 0 |
| 13 |
1 0 1 1 |
| 14 |
1 0 0 1 |
| 15 |
1 0 0 0 |
Разряды
в коде Грея не имеют постоянного веса. Вес k—разряда
определяется следующим образом
![]()
.
При этом все нечетные
единицы, считая слева направо, имеют
положительный вес, а все четные единицы
отрицательный.
Например,
![]()
Непостоянство
весов разрядов затрудняет выполнение
арифметических операций в коде Грея,
поэтому необходимо уметь делать перевод
кода Грея в обычный двоичный код и наоборот.
Алгоритм перевода чисел можно представить
следующим образом.
Пусть
![]()
— двоичный код,
![]()
— код Грея
Тогда
переход из двоичного кода
в код Грея выполнится
по следующему алгоритму
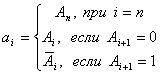
Например,
![]() .
.
Обратный переход из кода Грея в
двоичный код
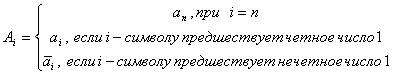
![]()
Например,
![]() .
.
![]()

Проверка четности. Контрольная сумма. Блочные и древовидные коды. Вес и расстояние Хэмминга между двоичными словами.

Коды делятся на два больших класса
Коды с исправлением ошибок
Цель восстановить с вероятностью, близкой к единице, посланное сообщение.
Коды с обнаружением ошибок
Цель выявить с вероятностью, близкой к единице, наличие ошибок.

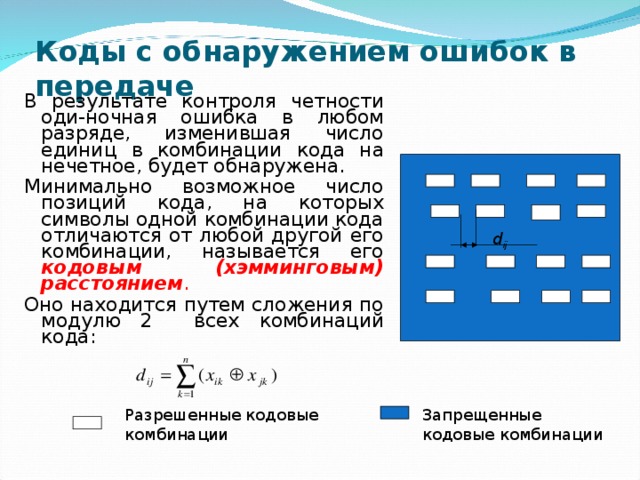
Коды с обнаружением ошибок в передаче
Введение в передаваемые кодовые комбинации избыточных разрядов все множество кодовых комбинаций разбивает на два подмножества, что снижает мощность и информационную скорость кода, но позволяет, при принятой запрещенной кодовой комбинации, обнаружить ошибку в передаче.
Например,
введение дополнительного бита контроля по четности делает четным число единиц в каждой кодовой комбинации равнодоступного кода и одновременно увеличивает их отличия не менее чем до двух разрядов.
Разрешенные кодовые комбинации
Запрещенные кодовые комбинации
Коды с обнаружением ошибок в передаче
В результате контроля четности оди-ночная ошибка в любом разряде, изменившая число единиц в комбинации кода на нечетное, будет обнаружена.
Минимально возможное число позиций кода, на которых символы одной комбинации кода отличаются от любой другой его комбинации, называется его кодовым (хэмминговым) расстоянием .
Оно находится путем сложения по модулю 2 всех комбинаций кода:
d ij
Разрешенные кодовые комбинации
Запрещенные кодовые комбинации

Виды корректирующих кодов

Коды с исправлением ошибок в передаче
Коды, которые позволяют не только обнаружить ошибку, но и определить номер искаженного символа (позиции), называются кодами с исправлением ошибок .
Для исправления одиночной ошибки придется увеличить кодовое расстояние минимум до 3, двухкратной до 4 и т. п.
В блоковых (блочных) кодах входная непрерывная последовательность информационных символов разбивается на блоки, содержащие k сим — волов.
 k . Этот набор, называемый кодовым словом , передается по каналу связи, искажается шумами и помехами, а затем декодируется независимо от всех других кодовых слов. Величина n называется длиной канального кода или длиной канального блока . Каждое сообщение в этом случае передаётся собственным кодовым словом. Кодовые слова могут объединяться в группы – кодовые предложения или фразы, объединённые некоторой общностью, например, способом защиты от помех кодовых слов, входящих в блок, и т. п. » width=»640″
k . Этот набор, называемый кодовым словом , передается по каналу связи, искажается шумами и помехами, а затем декодируется независимо от всех других кодовых слов. Величина n называется длиной канального кода или длиной канального блока . Каждое сообщение в этом случае передаётся собственным кодовым словом. Кодовые слова могут объединяться в группы – кодовые предложения или фразы, объединённые некоторой общностью, например, способом защиты от помех кодовых слов, входящих в блок, и т. п. » width=»640″
Все дальнейшие операции в кодере производятся над каждым блоком отдельно и независимо от других блоков.
Каждому информационному блоку из k символов ставится в соответствие набор из n символов кода канала передачи сообщений, где n k . Этот набор, называемый кодовым словом , передается по каналу связи, искажается шумами и помехами, а затем декодируется независимо от всех других кодовых слов.
Величина n называется длиной канального кода или длиной канального блока . Каждое сообщение в этом случае передаётся собственным кодовым словом.
Кодовые слова могут объединяться в группы – кодовые предложения или фразы, объединённые некоторой общностью, например, способом защиты от помех кодовых слов, входящих в блок, и т. п.

К онтрольная сумма — это некоторое значение, вычисленное по определённой схеме на основе кодируемого сообщения.
Проверочная информация при систематическом кодировании приписывается к передаваемым данным.
На принимающей стороне абонент знает алгоритм вычисления контрольной суммы: соответственно, программа имеет возможность проверить корректность принятых данных.

Без контрольной суммы, передавать данные опасно, так как помехи присутствуют везде и всегда, весь вопрос только в их вероятности возникновения и вызываемых ими побочных эффектах.
В зависимости от условий и выбирается алгоритм выявления ошибок и количество данных в контрольной сумме.
Чем сложнее алгоритм, и больше контрольная сумма, тем меньше не распознанных ошибок.

Все алгебраические коды можно разделить на два больших класса:
Блочные (блоковые)
Непрерывные
(древовидные)

Блочные коды представляют собой совокупность кодовых символов, состоящих из отдельных комбинаций (блоков) элементов символов кода, которые кодируются и декодируются независимо.

Непрерывные (древовидные) коды представляют собой непрерывную последовательность кодовых символов, причем введение проверочных элементов производится непрерывно, без разделения ее на независимые блоки.

В древовидных (непрерывных) кодах информационная последовательность подвергается обработке без предварительного разбиения на независимые блоки. Длинной, полубесконечной информационной последовательности ставится в соответствие кодовая последовательность, состоящая из большего числа символов.
Непрерывными эти коды называются потому, что операции кодирования и декодирования в них совершаются непрерывно. Они способны исправлять пакетные ошибки при сравнительно простых алгоритмах кодирования и декодирования .

Свойства кодов с исправлением ошибок в передаче
Кодированный цифровой сигнал приобретает свойства обнаружения, а иногда и исправления ошибок, возникающих в процессе передачи и приёма сообщений, т. е. свойство помехозащищенности .
Применение специальных криптографических кодов, известных только соответствующим абонентам, обеспечивает секретность передачи, а зашифрованное сообщение приобретает свойство криптографической стойкости .
Первыми появились блоковые коды, они же также лучше теоретически исследованы. Из древовидных кодов проще всего с точки зрения реализации свёрточные и цепные коды .
Возможности блоковых и древовидных кодов по исправлению ошибок передачи примерно одинаковы. Наибольшее распространение в существующих системах передачи получили разделимые систематические коды , а из них – коды Хэмминга и циклические коды.

Расстоя́ние и вес Хэ́мминга

Пусть u =( u 1 , u 2 , … , u n ) – двоичная последовательность длиной n .
Число единиц в этой последовательности называется весом Хэмминга вектор а u и обозначается как w(u).
Например: u =( 1 0 0 1 0 1 1 ), тогда w ( u )= 4 .
Пусть u и v – двоичные слова длиной n .
Число разрядов, в которых эти слова различаются, называется расстоянием Хэмминга между u и v и обозначается как d(u, v) .
Например: u =( 1 0 0 1 0 1 1 ), v =( 0 1 0 0 0 1 1 ), тогда d ( u , v )= 3 .

Самостоятельно
Найти вес и кодовое расстояние для двоичных слов
- a=011011100
- b=100111001
Решение: Вес для двоичных слов w(a)=5 ; w(b)= 5 .
Кодовое расстояние d(A,B) = 6.