
Forward error correction (FEC) is an error correction technique to detect and correct a limited number of errors in transmitted data without the need for retransmission.
In this method, the sender sends a redundant error-correcting code along with the data frame. The receiver performs necessary checks based upon the additional redundant bits. If it finds that the data is free from errors, it executes error-correcting code that generates the actual frame. It then removes the redundant bits before passing the message to the upper layers.
Advantages and Disadvantages
-
Because FEC does not require handshaking between the source and the destination, it can be used for broadcasting of data to many destinations simultaneously from a single source.
-
Another advantage is that FEC saves bandwidth required for retransmission. So, it is used in real time systems.
-
Its main limitation is that if there are too many errors, the frames need to be retransmitted.
Error Correction Codes for FEC
Error correcting codes for forward error corrections can be broadly categorized into two types, namely, block codes and convolution codes.
-
Block codes − The message is divided into fixed-sized blocks of bits to which redundant bits are added for error correction.
-
Convolutional codes − The message comprises of data streams of arbitrary length and parity symbols are generated by the sliding application of a Boolean function to the data stream.
There are four popularly used error correction codes.
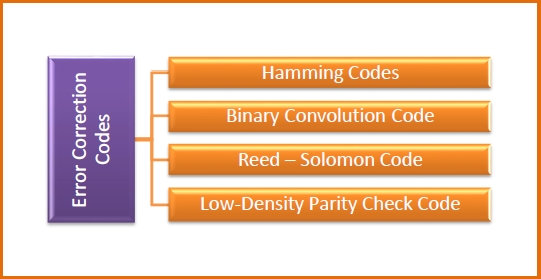
-
Hamming Codes − It is a block code that is capable of detecting up to two simultaneous bit errors and correcting single-bit errors.
-
Binary Convolution Code − Here, an encoder processes an input sequence of bits of arbitrary length and generates a sequence of output bits.
-
Reed — Solomon Code − They are block codes that are capable of correcting burst errors in the received data block.
-
Low-Density Parity Check Code − It is a block code specified by a parity-check matrix containing a low density of 1s. They are suitable for large block sizes in very noisy channels.
Назначение помехоустойчивого кодирования – защита информации от помех и ошибок при передаче и хранении информации. Помехоустойчивое кодирование необходимо для устранения ошибок, которые возникают в процессе передачи, хранения информации. При передачи информации по каналу связи возникают помехи, ошибки и небольшая часть информации теряется.

Без использования помехоустойчивого кодирования было бы невозможно передавать большие объемы информации (файлы), т.к. в любой системе передачи и хранении информации неизбежно возникают ошибки.
Рассмотрим пример CD диска. Там информация хранится прямо на поверхности диска, в углублениях, из-за того, что все дорожки на поверхности, часто диск хватаем пальцами, елозим по столу и из-за этого без помехоустойчивого кодирования, информацию извлечь не получится.

Использование кодирования позволяет извлекать информацию без потерь даже с поврежденного CD/DVD диска, когда какая либо область становится недоступной для считывания.
В зависимости от того, используется в системе обнаружение или исправление ошибок с помощью помехоустойчивого кода, различают следующие варианты:
- запрос повторной передачи (Automatic Repeat reQuest, ARQ): с помощью помехоустойчивого кода выполняется только обнаружение ошибок, при их наличии производится запрос на повторную передачу пакета данных;
- прямое исправление ошибок (Forward Error Correction, FEC): производится декодирование помехоустойчивого кода, т. е. исправление ошибок с его помощью.
Возможен также гибридный вариант, чтобы лишний раз не гонять информацию по каналу связи, например получили пакет информации, попробовали его исправить, и если не смогли исправить, тогда отправляется запрос на повторную передачу.
Исправление ошибок в помехоустойчивом кодировании
Любое помехоустойчивое кодирование добавляет избыточность, за счет чего и появляется возможность восстановить информацию при частичной потере данных в канале связи (носителе информации при хранении). В случае эффективного кодирования убирали избыточность, а в помехоустойчивом кодировании добавляется контролируемая избыточность.
Простейший пример – мажоритарный метод, он же многократная передача, в котором один символ передается многократно, а на приемной стороне принимается решение о том символе, количество которых больше.
Допустим есть 4 символа информации, А, B, С,D, и эту информацию повторяем несколько раз. В процессе передачи информации по каналу связи, где-то возникла ошибка. Есть три пакета (A1B1C1D1|A2B2C2D2|A3B3C3D3), которые должны нести одну и ту же информацию.

Но из картинки справа, видно, что второй символ (B1 и C1) они отличаются друг от друга, хотя должны были быть одинаковыми. То что они отличаются, говорит о том, что есть ошибка.
Необходимо найти ошибку с помощью голосования, каких символов больше, символов В или символов С? Явно символов В больше, чем символов С, соответственно принимаем решение, что передавался символ В, а символ С ошибочный.
Для исправления ошибок нужно, как минимум 3 пакета информации, для обнаружения, как минимум 2 пакета информации.
Параметры помехоустойчивого кодирования
Первый параметр, скорость кода R характеризует долю информационных («полезных») данных в сообщении и определяется выражением: R=k/n=k/m+k
- где n – количество символов закодированного сообщения (результата кодирования);
- m – количество проверочных символов, добавляемых при кодировании;
- k – количество информационных символов.
Параметры n и k часто приводят вместе с наименованием кода для его однозначной идентификации. Например, код Хэмминга (7,4) значит, что на вход кодера приходит 4 символа, на выходе 7 символов, Рида-Соломона (15, 11) и т.д.
Второй параметр, кратность обнаруживаемых ошибок – количество ошибочных символов, которые код может обнаружить.
Третий параметр, кратность исправляемых ошибок – количество ошибочных символов, которые код может исправить (обозначается буквой t).
Контроль чётности
Самый простой метод помехоустойчивого кодирования это добавление одного бита четности. Есть некое информационное сообщение, состоящее из 8 бит, добавим девятый бит.
Если нечетное количество единиц, добавляем 0.
1 0 1 0 0 1 0 0 | 0
Если четное количество единиц, добавляем 1.
1 1 0 1 0 1 0 0 | 1
Если принятый бит чётности не совпадает с рассчитанным битом чётности, то считается, что произошла ошибка.
1 1 0 0 0 1 0 0 | 1
Под кратностью понимается, всевозможные ошибки, которые можно обнаружить. В этом случае, кратность исправляемых ошибок 0, так как мы не можем исправить ошибки, а кратность обнаруживаемых 1.
Есть последовательность 0 и 1, и из этой последовательности составим прямоугольную матрицу размера 4 на 4. Затем для каждой строки и столбца посчитаем бит четности.
Прямоугольный код – код с контролем четности, позволяющий исправить одну ошибку:

И если в процессе передачи информации допустим ошибку (ошибка нолик вместо единицы, желтым цветом), начинаем делать проверку. Нашли ошибку во втором столбце, третьей строке по координатам. Чтобы исправить ошибку, просто инвертируем 1 в 0, тем самым ошибка исправляется.
Этот прямоугольный код исправляет все одно-битные ошибки, но не все двух-битные и трех-битные.
Рассчитаем скорость кода для:
- 1 1 0 0 0 1 0 0 | 1
Здесь R=8/9=0,88
- И для прямоугольного кода:
Здесь R=16/24=0,66 (картинка выше, двадцать пятую единичку (бит четности) не учитываем)
Более эффективный с точки зрения скорости является первый вариант, но зато мы не можем с помощью него исправлять ошибки, а с помощью прямоугольного кода можно. Сейчас на практике прямоугольный код не используется, но логика работы многих помехоустойчивых кодов основана именно на прямоугольном коде.
Классификация помехоустойчивых кодов
- Непрерывные — процесс кодирования и декодирования носит непрерывный характер. Сверточный код является частным случаем непрерывного кода. На вход кодера поступил один символ, соответственно, появилось несколько на выходе, т.е. на каждый входной символ формируется несколько выходных, так как добавляется избыточность.
- Блочные (Блоковые) — процесс кодирования и декодирования осуществляется по блокам. С точки зрения понимания работы, блочный код проще, разбиваем код на блоки и каждый блок кодируется в отдельности.
По используемому алфавиту:
- Двоичные. Оперируют битами.
- Не двоичные (код Рида-Соломона). Оперируют более размерными символами. Если изначально информация двоичная, нужно эти биты превратить в символы. Например, есть последовательность 110 110 010 100 и нужно их преобразовать из двоичных символов в не двоичные, берем группы по 3 бита — это будет один символ, 6, 6, 2, 4 — с этими не двоичными символами работают не двоичные помехоустойчивые коды.
Блочные коды делятся на
- Систематические — отдельно не измененные информационные символы, отдельно проверочные символы. Если на входе кодера присутствует блок из k символов, и в процессе кодирования сформировали еще какое-то количество проверочных символов и проверочные символы ставим рядом к информационным в конец или в начало. Выходной блок на выходе кодера будет состоять из информационных символов и проверочных.
- Несистематические — символы исходного сообщения в явном виде не присутствуют. На вход пришел блок k, на выходе получили блок размером n, блок на выходе кодера не будет содержать в себе исходных данных.
В случае систематических кодов, выходной блок в явном виде содержит в себе, то что пришло на вход, а в случае несистематического кода, глядя на выходной блок нельзя понять что было на входе.

Смотря на картинку выше, код 1 1 0 0 0 1 0 0 | 1 является систематическим, на вход поступило 8 бит, а на выходе кодера 9 бит, которые в явном виде содержат в себе 8 бит информационных и один проверочный.

Код Хэмминга
Код Хэмминга — наиболее известный из первых самоконтролирующихся и самокорректирующихся кодов. Позволяет устранить одну ошибку и находить двойную.

Код Хэмминга (7,4) — 4 бита на входе кодера и 7 на выходе, следовательно 3 проверочных бита. С 1 по 4 информационные биты, с 6 по 7 проверочные (см. табл. выше). Пятый проверочный бит y5, это сумма по модулю два 1-3 информационных бит. Сумма по модулю 2 это вычисление бита чётности.
Декодирование кода Хэмминга
Декодирование происходит через вычисление синдрома по выражениям:

Синдром это сложение бит по модулю два. Если синдром не нулевой, то исправление ошибки происходит по таблице декодирования:

Расстояние Хэмминга
Расстояние Хэмминга — число позиций, в которых соответствующие символы двух кодовых слов одинаковой длины различны. Если рассматривать два кодовых слова, (пример на картинке ниже, 1 0 1 1 0 0 1 и 1 0 0 1 1 0 1) видно что они отличаются друг от друга на два символа, соответственно расстояние Хэмминга равно 2.

Кратность исправляемых ошибок и обнаруживаемых, связано минимальным расстоянием Хэмминга. Любой помехоустойчивый код добавляет избыточность с целью увеличить минимальное расстояние Хэмминга. Именно минимальное расстояние Хэмминга определяет помехоустойчивость.
Помехоустойчивые коды
Современные коды более эффективны по сравнению с рассматриваемыми примерами. В таблице ниже приведены Коды Боуза-Чоудхури-Хоквингема (БЧХ)

Из таблицы видим, что там один класс кода БЧХ, но разные параметры n и k.
- n — количество символов на входе.
- k — количество символов на выходе.
- t — кратность исправляемых ошибок.
- Отношение k/n — скорость кода.
- G (энергетический выигрыш) — величина, показывающая на сколько можно уменьшить отношение сигнал/шум (Eb/No) для обеспечения заданной вероятности ошибки.
Несмотря на то, что скорость кода близка, количество исправляемых ошибок может быть разное. Количество исправляемых ошибок зависит от той избыточности, которую добавим и от размера блока. Чем больше блок, тем больше ошибок он исправляет, даже при той же самой избыточности.
Пример: помехоустойчивые коды и двоичная фазовая манипуляция (2-ФМн). На графике зависимость отношения сигнал шум (Eb/No) от вероятности ошибки. За счет применения помехоустойчивых кодов улучшается помехоустойчивость.

Из графика видим, код Хэмминга (7,4) на сколько увеличилась помехоустойчивость? Всего на пол Дб это мало, если применить код БЧХ (127, 64) выиграем порядка 4 дБ, это хороший показатель.
Компромиссы при использовании помехоустойчивых кодов
Чем расплачиваемся за помехоустойчивые коды? Добавили избыточность, соответственно эту избыточность тоже нужно передавать. Нужно: увеличивать пропускную способность канала связи, либо увеличивать длительность передачи.

Компромисс:
- Достоверность vs полоса пропускания.
- Мощность vs полоса пропускания.
- Скорость передачи данных vs полоса пропускания
Необходимость чередования (перемежения)
Все помехоустойчивые коды могут исправлять только ограниченное количество ошибок t. Однако в реальных системах связи часто возникают ситуации сгруппированных ошибок, когда в течение непродолжительного времени количество ошибок превышает t.
Например, в канале связи шумов мало, все передается хорошо, ошибки возникают редко, но вдруг возникла импульсная помеха или замирания, которые повредили на некоторое время процесс передачи, и потерялся большой кусок информации. В среднем на блок приходится одна, две ошибки, а в нашем примере потерялся целый блок, включая информационные и проверочные биты. Сможет ли помехоустойчивый код исправить такую ошибку? Эта проблема решаема за счет перемежения.
Пример блочного перемежения:

На картинке, всего 5 блоков (с 1 по 25). Код работает исправляя ошибки в рамках одного блока (если в одном блоке 1 ошибка, код его исправит, а если две то нет). В канал связи отдается информация не последовательно, а в перемешку. На выходе кодера сформировались 5 блоков и эти 5 блоков будем отдавать не по очереди а в перемешку. Записали всё по строкам, но считывать будем, чтобы отправлять в канал связи, по столбцам. Информация в блоках перемешалась. В канале связи возникла ошибка и мы потеряли большой кусок. В процессе приема, мы опять составляем таблицу, записываем по столбцам, но считываем по строкам. За счет того, что мы перемешали большое количество блоков между собой, групповая ошибка равномерно распределится по блокам.
Введение
В качестве примера можно привести повсеместно распространенные технологии Ethernet+TCP/IP. В случае беспроводных сетей разработчики наряду с теми или иными способами обнаружения ошибок дополнительно применяют средства их исправления.
Общая идея как обнаружения, так и исправления ошибок основывается на использовании избыточных кодов. Простейший пример — это введение так называемого «бита четности» — такой прием позволяет обнаружить единичную ошибку.
На передающей стороне значение бита четности определяется следующим правилом: при четном количестве единиц в блоке информации проверочный бит должен быть равен нулю, в противном случае — единице. Таким образом, общее количество единиц в блоке (включая избыточный бит) должно быть четным. Если на приемной стороне количество единиц оказалось нечетным, этот блок считается поврежденным. Добавление одного бита фактически увеличивает число возможных кодовых слов в два раза, но при этом только половина из них является допустимо, разрешенными, а другая половина в силу обозначенных правил невозможна, запрещена.
Декодер, встретив какую-либо комбинацию битов, которая входит в число невозможных, делает вывод, что кодовое слово было передано с ошибкой. Более сложные схемы основаны на аналогичной идее, но подразумевают большее количество добавочных битов и более сложные правила формирования их комбинаций; при этом эти правила дают возможность на приемной стороне определить, какой именно бит (или биты) были повреждены.
Поскольку применение рассматриваемых методов обнаружения и/или коррекции ошибок связано с передачей дополнительных проверочных битов, то совершенно ясно, что применение средств такого рода оправданно именно в ситуациях, когда велика вероятность сбоя при передаче — в противном случае введение дополнительных данных приведет лишь к уменьшению полезной пропускной способности канала передачи.
Общая теория помехоустойчивых кодов (кодов с исправлением ошибок) изложена в книге [1]. В англоязычной литературе схемы кодирования с избыточностью с целью исправления ошибок называются FEC (сокращение от Forward Error Correction). С общими сведениями о способах обнаружения и коррекции ошибок можно ознакомиться, например, в RFC2354 [2].
В соответствии с описанием стандарта nanoNET [3] передаваемые данные подвергаются многоступенчатой побитовой обработке (рис. 1).

Рис. 1. Битовые преобразования в трансмиттере и ресивере
После формирования кадра (составления заголовков и записи данных в трансивер) и получения команды начать передачу вычисляются контрольные суммы заголовков кадра CRC1 и поля данных CRC2. Затем (при включении соответствующей опции) поле данных и контрольная сумма CRC2 шифруются с помощью 128-битного ключа. После этого весь кадр подвергается так называемому скремблированию (перемешиванию битов) — это делается для минимизации вероятности появления длинных цепочек нулей и повышения надежности передачи. Далее битовая последовательность проходит через описанную ниже схему помехоустойчивого кодирования FEC и только потом преобразуется в чирп-сигналы (импульсы длительностью 1 мкс с наполнением возрастающей и (или) убывающей частотой).
На приемной стороне процесс происходит в обратном порядке, то есть сначала из помехоустойчивого кода получаются информационные биты, возможно, с исправлением ошибок, затем производится процедура, обратная перемешиванию, расшифровка и проверка контрольных сумм. При этом контрольное суммирование и перемешивание являются обязательными стадиями (скремблирование рекомендовано к применению), в то время как шифрование и помехоустойчивое кодирование таковыми не являются (помечены на рис. 1 серым фоном).
Отметим, что трансиверы nanoNET можно конфигурировать на прием или передачу как с использованием корректирующих кодов, так и без их использования. При этом в передаваемом кадре не содержится никаких сведений о том, подвергался ли он такому кодированию FEC или нет. Это означает, что для того чтобы передатчик и приемник, выражаясь образно, «разговаривали на одном языке», нужно, чтобы они были одинаковым образом сконфигурированы в плане использования или неиспользования FEC.
Для кодирования FEC с возможностью исправления ошибок передачи трансиверы nanoNET используют классический код Хэмминга (7,4), то есть к каждой четверке информационных битов добавляется 3 проверочных, общая длина кодового слова равна 7. Из теории корректирующих кодов известно, что такой код имеет минимальное кодовое расстояние 3, и, следовательно, приемник способен либо исправить одиночную ошибку, либо обнаружить двойную. Особенностью реализации помехоустойчивого кодирования в передатчиках рассматриваемого стандарта является совместное кодирование двух соседних полубайтов за счет перемежения битов кодовых слов, полученных при кодировании этих двух полубайтов: сначала кодируется один полубайт, то есть из комбинации битов (b0, b1, b2, b3) получается кодовое слово:
![]()
(символами bi обозначены информационные биты, а символами Pk – проверочные биты), затем кодируется другой полубайт, получается кодовое слово:
![]()
далее эти два кодовых слова перемежаются следующим образом:
![]()
Это позволяет исправлять двойные ошибки в результирующем 14-разрядном кодовом слове даже в том случае, если эти ошибки произошли в соседних битах. Данное свойство особенно важно при использовании четверичной системы счисления, которая используется в nanoNET для кодирования одного символа данных двумя битами и позволяет передавать данные на скорости 2 Мбит/с.
Регистры модулей nanoPAN, связанные с FEC
FEC, CRC2 type, Symbols and Modulation (адрес 0х39 — регистр, отвечающий за включение FEC, тип контрольной суммы CRC2, систему модуляции и длину символа):

TxRxMode — выбор режима (Auto или Transparent, по умолчанию TxRxMode=0=Auto).
TxRxFwdEc — включение или выключение FEC, по умолчанию TxRxFwdEc=0, FEC отключен.
TxRxCrcType — указание типа контрольной суммы данных.
TxRxData Rate – выбор битовой скорости передачи (500 или 1000 Ksps, по умолчанию TxRxDataRate=0, 1000 Ksps).
TxRxMod System — выбор способа модуляции (двоичная или четверичная, по умолчанию TxRxModSystem=0, двоичная).
Receive FEC Single Bit Error Count (адреса 0х57 и 0х58 — регистры, в которых содержится число единичных ошибок, исправленных в предыдущем принятом кадре).
0x57:
![]()
0x57:
![]()
RxFec1BitErr — 15-разрядное число единичных ошибок, встретившихся в предыдущем принятом кадре. Этот регистр содержит корректную информацию только в случае, если бит TxRxFwdEc в регистре 0х39 выставлен в значение 1).
Регулирование амплитуды выходного сигнала
Для сбора статистики по функционированию режима FEC использовалась возможность управления силой выходного сигнала в трансиверах nanoPAN. Для этого перед стартом передачи необходимо было занести число от 0 до 63 в младшие шесть байтов регистров RfTxOutputPower с адресами 0x2A и 0x2B (первый соответствует управлению силой сигнала для кадров с данными, второй предназначен для служебных кадров). В документации на NA1TR8 [4] приводится зависимость выходной мощности сигнала от значения, записанного в указанном регистре (рис. 2).

Рис. 2. Зависимость мощности выходного сигнала от значения, записанного в регистр RfTxOutputPower
Таким образом, трансиверы поддерживают 19 градаций мощности сигнала, которые соответствуют значениям (0, 1, 2, 3, 4, 5, 21, 22, 23, 39, 40, 41, 57, 58, 59, 60, 61, 62, 63) в регистре RfTxOutputPower.
Порядок проведения экспериментов
В предыдущих статьях авторов [5, 6] было описано некоторое количество экспериментов по определению условий и качества радиосвязи с использованием трансиверов nanoNET. На основе программного обеспечения, использовавшегося ранее, для изучения условий применения коррекции ошибок FEC была создана новая версия программы. Она загружалась и исполнялась в микроконтроллерах ATmega32L и управляла работой двух радиомодулей nanoNET по интерфейсу SPI. Также с ее помощью результаты измерений отсылались по com-порту в персональный компьютер.
В начале цикла измерений узел-мастер в течение 10 секунд посылал узлу-слейву кадры длиной 128 байт на максимальной выходной мощности. В журнал работы заносилось как значение общего количества отосланных кадров, так и количество кадров, на которые удаленный узел прислал подтверждение о приеме. Каждый кадр передавался не более чем c тремя ретрансмиссиями, которые автоматически осуществлялись в случае неуспешного приема.
После 10-секундного периода узел-мастер последовательно посылал узлу-слейву кадры, постепенно уменьшая амплитуду сигнала со значения 63 до 0, и фиксировал количество ретрансмиссий. Если счетчик попыток передачи пакета для текущей мощности сигнала равнялся трем, это означало, что пакет так и не был доставлен адресату (узлу-слейву). Пакеты подтверждения о приеме посылались всегда на максимальной мощности (63).
Типичная запись в журнале эксперимента выглядела следующим образом.
FEC off и FEC on — выключение и включение режима коррекции ошибок соответственно.
SENT=3973 — количество отправленных за 10 секунд кадров по 128 байтов (на максимальной мощности сигнала).
OK=3973 — количество переданных пакетов, на которые было получено подтверждение о приеме.
RTC: 000004395914 — временная метка регистрации данных (аппаратная поддержка в трансиверах Nanonet).
Строчка, обозначенная синим цветом на рис. 3, содержит набор цифр, каждая из которых обозначает уровень мощности отправленного информационного кадра. Всего 19 градаций — от 18 (написана только восьмерка, а единица для компактности в записи в журнале опущена) до 0.

Рис. 3. Пример записей в журнале о двух последовательных измерениях
Следующие три (для увеличения достоверности) строки соответствуют сериям отправки кадров с уменьшающейся силой сигнала.
Каждый символ в этих строчках обозначает количество ретрансмиссий, которое потребовалось для подтвержденной передачи. Если их не было, то есть кадр был передан с первой попытки, вставлялся пробел.
Например, в первой серии кадры с уровнем мощности 18, 17, 16 и т. д. до 9 отсылались с первой попытки. А вот при уровне сигнала в 9 условных единиц потребовалась одна дополнительная ретрансмиссия; далее на восьмом уровне мощности две ретрансмиссии, а затем вообще не было зарегистрировано безошибочных передач.
Другими словами, пока сигнал узла-мастера был достаточно сильным (соответствующие значения регистра RfTxOutputPower лежали в диапазоне от 63 до 39), узел-слейв подтверждал прием каждого пакета. Как только уровень мощности стал равным 9, начали появляться проблемы с приемом. А для уровней сигнала от 7 до 0 вообще не было зарегистрировано ни одной успешной передачи.
То есть чем хуже были условия приема-передачи, тем ближе к началу третьей строки возникали цифры 1, 2 и 3.
Пользуясь таким журналом, можно ввести некий новый параметр, характеризующий необходимую (минимальную) амплитуду выходного сигнала, достаточную для успешной передачи в конкретных условиях. Его можно назвать пороговой мощностью между безошибочным и ошибочным приемом. Для приведенного выше примера (первая серия) таким порогом было 9. Чем ниже порог, тем более стабильная была передача при неизменной мощности радиосигнала.
Таким образом, качество радиосвязи в проведенных экспериментах контролировалось двумя параметрами: процентом безошибочных передач для кадров, отосланных на максимальной мощности, и усредненной по трем значениям пороговой мощностью успешной передачи.
Результаты экспериментов
-
- Сравнивая последовательные серии посылок с включенной (FEC on) и выключенной (FEC off, рис. 3) коррекцией ошибок, можно сразу заметить, что включение коррекции ошибок позволяет повысить надежность передачи при неизменном уровне мощности сигнала на стороне передатчика.
- На рис. 4 отражена диаграмма распределений процента успешных передач (отношение OK/SENT для кадров, отправленных на максимальной мощности) от пороговой мощности между безошибочным и ошибочным приемом (пороговая мощность выступает в качестве параметра условий радиопередачи «хорошо-плохо»). Данный график не имеет прямого отношения к коррекции данных, однако очень важен в практическом плане.

Рис. 4. Процент безошибочных передач кадров длиной 128 байтов в зависимости от порогового уровня выходного сигнала на передающей стороне и включения или выключения коррекции ошибок FEC

При построении сетей датчиков и других распределенных систем одним из актуальных вопросов оказывается управление энергопотреблением. Главным инструментом в этом случае является варьирование мощности выходного сигнала (чем больше его амплитуда и потребляемый ток, тем больше зона уверенного приема). Кроме этого, намеренное уменьшение мощности иногда используется для снижения вероятности возникновения коллизий и сетевых проблем типа «скрытый узел».
Для организации надежной радиосвязи по возможности без ретрансмиссий необходимо обеспечить уровень потерь не выше 5–10%. Тогда для осуществления передачи потребуется максимум одна ретрансмиссия.
Поэтому можно утверждать, что после тестирования канала радиосвязи и оценки пороговой мощности независимо от того, включена коррекция FEC или нет, если трансиверы связываются между собой в условиях с пороговыми уровнями сигнала не выше 10 в условных единицах, это почти гарантирует малоошибочную передачу. В случаях осуществления связи с уровнями сигнала 15–17 процент успешных передач резко падает, а при уровне 18 связь крайне нестабильная (рис. 4).
Использование тестирования линий таким способом может помочь при проектировании маршрутов в сложных радиосетях типа mesh (ячеистая).
-
- На рис. 5 представлены данные 64 измерений. Для каждой точки в обоих режимах (FEC on и FEC off) собиралась информация о количестве безошибочных передач и пороговом (минимальном) уровне мощности сигнала на передающей стороне, необходимом для успешной доставки кадра по назначению. Разница между измерениями заключалась в подборе внешних условий прохождения радиосигналов путем отключения антенн и изменения расстояния между источником и приемником кадров.
Рис. 5. Количество безошибочных передач кадров за 10 секунд (левая ось) и соответствующий ему пороговый уровень выходного сигнала на передающей стороне (правая ось) при включенной и выключенной коррекции ошибок FEC для 64 точек измерений
- На рис. 5 представлены данные 64 измерений. Для каждой точки в обоих режимах (FEC on и FEC off) собиралась информация о количестве безошибочных передач и пороговом (минимальном) уровне мощности сигнала на передающей стороне, необходимом для успешной доставки кадра по назначению. Разница между измерениями заключалась в подборе внешних условий прохождения радиосигналов путем отключения антенн и изменения расстояния между источником и приемником кадров.

После набора данных они были отсортированы по убыванию значений количества безошибочно переданных кадров для режима с выключенной коррекцией ошибок FEC (монотонно убывающая кривая из сплошных квадратов на рис. 5, левая ось). Ей соответствует почти монотонно возрастающая линия с полыми квадратами. При пороговых уровнях мощности до 10 (правая ось для полых квадратов), уровень безошибочных передач достаточно высок, а уже после 13-й точки по горизонтальной оси начинает снижаться.
Подобная картина наблюдается и для кривых с ромбами (включенный FEC). До 33-й точки количество успешных передач максимально, тогда как с увеличением пороговой мощности выше 10 процент потерь также увеличивается. Разница в максимальных значениях количества отосланных кадров за 10 секунд для включенного и выключенного режима коррекции ошибок составляет примерно 40%, что объясняется увеличением времени передачи из-за введенных в поток дополнительных битов, обеспечивающих избыточность. Другими словами, при включении опции FEC скорость передачи падает примерно в 1,4 раза, что, однако, резко повышает надежность связи и, соответственно, увеличивает зону уверенного приема. При сравнении значений двух кривых с полыми квадратами и ромбами можно отметить, что при одних и тех же условиях (для одной точки на графике) кривая с квадратами находится выше, в среднем, примерно на 4 деления по правой шкале. Это говорит о том, что благодаря коррекции ошибок можно из более слабого физического входного сигнала «добыть» информационную составляющую без использования дополнительных аппаратных усилителей и средств радиочастотной фильтрации.
Приняв во внимание график (рис. 6), полученный в ходе экспериментов [6], можно заметить, что уменьшение пороговой мощности, достаточной для установления связи, на 4 единицы примерно соответствует 60 метрам увеличения максимального расстояния между узлами, что предс тавляется очень серьезной цифрой.

Рис. 6. Зависимость минимального уровня мощности (в соответствии со значением регистра RfTxOutputPower)
Заключение
Как уже было показано, введение аппаратной коррекции ошибок практически всегда позволяет достичь более устойчивой связи. «Платой» за это является уменьшение пропускной способности радиоканала.
В заключение необходимо отметить, что включение опции FEС не избавляет от ошибок, оно лишь помогает некоторые из них исправить. Даже если FEC-декодер вследствие случайности помех не определит наличие ошибки (например, строенная, счетверенная), то это почти наверняка будет определено на приемной стороне при CRC-декодировании.
Авторы благодарят Д. А. Екимова (Петрозаводский государственный университет) за высказанные критические замечания.
Данное исследование проведено в рамках проекта «Научно-образовательный центр по фундаментальным проблемам приложений физики низкотемпературной плазмы» (RUX0-013-PZ-06), поддерживаемого Министерством образования и науки РФ, Американским фондом гражданских исследований и развития (CRDF) и Правительством Республики Карелия, а также частично финансировалось Техническим Научно-исследовательским Центром Финляндии (VTT) в рамках договорных работ.
Литература
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- RFC 2354. Options for Repair of Streaming Media. June 1998.
- NanoNET PHY and MAC System Specifi cations, ver.1.04. Nanotron Technologies GmbH, Alt-Moabit 60, 10555 Berlin, Germany. NA-03-0101-0230-1.04.
- NanoNET TRX (NA1TR8) Transceiver Datasheet, ver. 2.07. Nanotron Technologies GmbH, Alt-Moabit 60, 10555 Berlin, Germany. NA-03-0111-0239-2.07.
- Мощевикин А. П. Исследование скорости передачи данных в беспроводных сетях Nanonet // Беспроводные технологии. 2006, № 3.
- Жиганов Е. Д., Красков С. Е., Мощевикин А. П. Исследование условий применимости приемопередатчиков стандарта Nanonet в беспроводных сетях датчиков // Беспроводные технологии. 2007, № 1, 2.
- Nanonet TRX (NA1TR8) Transceiver Register Description, ver. 1.06. Nanotron Technologies GmbH, Alt-Moabit 60, 10555 Berlin, Germany. NA-03-0100-0246-1.06.
Методы, обеспечивающие надежную доставку цифровых данных по ненадежным каналам связи  Устранение ошибок передачи, вызванных атмосферой Земли ( слева), ученые Годдарда применили исправление ошибок Рида – Соломона (справа), которое обычно используется в компакт-дисках и DVD. Типичные ошибки включают отсутствие пикселей (белые) и ложные сигналы (черные). Белая полоса указывает на короткий период, когда передача была приостановлена.
Устранение ошибок передачи, вызванных атмосферой Земли ( слева), ученые Годдарда применили исправление ошибок Рида – Соломона (справа), которое обычно используется в компакт-дисках и DVD. Типичные ошибки включают отсутствие пикселей (белые) и ложные сигналы (черные). Белая полоса указывает на короткий период, когда передача была приостановлена.
В теории информации и теории кодирования с приложениями в информатике и телекоммуникациях, обнаружение и исправление ошибок или контроль ошибок — это методы, которые обеспечивают надежную доставку цифровых данных по ненадежным каналам связи. Многие каналы связи подвержены канальному шуму, и поэтому во время передачи от источника к приемнику могут возникать ошибки. Методы обнаружения ошибок позволяют обнаруживать такие ошибки, а исправление ошибок во многих случаях позволяет восстановить исходные данные.
Содержание
- 1 Определения
- 2 История
- 3 Введение
- 4 Типы исправления ошибок
- 4.1 Автоматический повторный запрос (ARQ)
- 4.2 Прямое исправление ошибок
- 4.3 Гибридные схемы
- 5 Схемы обнаружения ошибок
- 5.1 Кодирование на минимальном расстоянии
- 5.2 Коды повторения
- 5.3 Бит четности
- 5.4 Контрольная сумма
- 5.5 Циклическая проверка избыточности
- 5.6 Криптографическая хеш-функция
- 5.7 Ошибка код исправления
- 6 Приложения
- 6.1 Интернет
- 6.2 Связь в дальнем космосе
- 6.3 Спутниковое вещание
- 6.4 Хранение данных
- 6.5 Память с исправлением ошибок
- 7 См. также
- 8 Ссылки
- 9 Дополнительная литература
- 10 Внешние ссылки
Определения
Обнаружение ошибок — это обнаружение ошибок, вызванных шумом или другими помехами во время передачи от передатчика к приемнику. Исправление ошибок — это обнаружение ошибок и восстановление исходных безошибочных данных.
История
Современная разработка кодов исправления ошибок приписывается Ричарду Хэммингу в 1947 году. Описание кода Хэмминга появилось в Математической теории коммуникации Клода Шеннона и было быстро обобщено Марселем Дж. Э. Голэем.
Введение
Все схемы обнаружения и исправления ошибок добавляют некоторые избыточность (т. е. некоторые дополнительные данные) сообщения, которые получатели могут использовать для проверки согласованности доставленного сообщения и для восстановления данных, которые были определены как поврежденные. Схемы обнаружения и исправления ошибок могут быть систематическими или несистематическими. В систематической схеме передатчик отправляет исходные данные и присоединяет фиксированное количество контрольных битов (или данных четности), которые выводятся из битов данных некоторым детерминированным алгоритмом. Если требуется только обнаружение ошибок, приемник может просто применить тот же алгоритм к полученным битам данных и сравнить свой вывод с полученными контрольными битами; если значения не совпадают, в какой-то момент во время передачи произошла ошибка. В системе, которая использует несистематический код, исходное сообщение преобразуется в закодированное сообщение, несущее ту же информацию и имеющее по крайней мере такое же количество битов, как и исходное сообщение.
Хорошие характеристики контроля ошибок требуют, чтобы схема была выбрана на основе характеристик канала связи. Распространенные модели каналов включают в себя модели без памяти, в которых ошибки возникают случайно и с определенной вероятностью, и динамические модели, в которых ошибки возникают в основном в пакетах . Следовательно, коды обнаружения и исправления ошибок можно в целом различать между обнаружением / исправлением случайных ошибок и обнаружением / исправлением пакетов ошибок. Некоторые коды также могут подходить для сочетания случайных ошибок и пакетных ошибок.
Если характеристики канала не могут быть определены или сильно изменяются, схема обнаружения ошибок может быть объединена с системой для повторных передач ошибочных данных. Это известно как автоматический запрос на повторение (ARQ) и наиболее широко используется в Интернете. Альтернативный подход для контроля ошибок — это гибридный автоматический запрос на повторение (HARQ), который представляет собой комбинацию ARQ и кодирования с исправлением ошибок.
Типы исправления ошибок
Существует три основных типа исправления ошибок.
Автоматический повторный запрос (ARQ)
Автоматический повторный запрос (ARQ) — это метод контроля ошибок для передачи данных, который использует коды обнаружения ошибок, сообщения подтверждения и / или отрицательного подтверждения и тайм-ауты для обеспечения надежной передачи данных. Подтверждение — это сообщение, отправленное получателем, чтобы указать, что он правильно получил кадр данных.
Обычно, когда передатчик не получает подтверждения до истечения тайм-аута (т. Е. В течение разумного периода времени после отправки фрейм данных), он повторно передает фрейм до тех пор, пока он либо не будет правильно принят, либо пока ошибка не останется сверх заранее определенного количества повторных передач.
Три типа протоколов ARQ: Stop-and-wait ARQ, Go-Back-N ARQ и Selective Repeat ARQ.
ARQ is подходит, если канал связи имеет переменную или неизвестную пропускную способность, например, в случае с Интернетом. Однако ARQ требует наличия обратного канала, что приводит к возможному увеличению задержки из-за повторных передач и требует обслуживания буферов и таймеров для повторных передач, что в случае перегрузка сети может вызвать нагрузку на сервер и общую пропускную способность сети.
Например, ARQ используется на коротковолновых радиоканалах в форме ARQ-E, или в сочетании с мультиплексированием как ARQ-M.
Прямое исправление ошибок
Прямое исправление ошибок (FEC) — это процесс добавления избыточных данных, таких как исправление ошибок code (ECC) в сообщение, чтобы оно могло быть восстановлено получателем, даже если в процессе передачи или при хранении был внесен ряд ошибок (в зависимости от возможностей используемого кода). Так как получатель не должен запрашивать у отправителя повторную передачу данных, обратный канал не требуется при прямом исправлении ошибок, и поэтому он подходит для симплексной связи, например вещание. Коды с исправлением ошибок часто используются в нижнем уровне связи, а также для надежного хранения на таких носителях, как CD, DVD, жесткие диски и RAM.
Коды с исправлением ошибок обычно различают между сверточными кодами и блочными кодами. :
- Сверточные коды обрабатываются побитно. Они особенно подходят для аппаратной реализации, а декодер Витерби обеспечивает оптимальное декодирование.
- Блочные коды обрабатываются на поблочной основе. Ранними примерами блочных кодов являются коды повторения, коды Хэмминга и многомерные коды контроля четности. За ними последовал ряд эффективных кодов, из которых коды Рида – Соломона являются наиболее известными из-за их широкого распространения в настоящее время. Турбокоды и коды с низкой плотностью проверки четности (LDPC) — это относительно новые конструкции, которые могут обеспечить почти оптимальную эффективность.
Теорема Шеннона — важная теорема при прямом исправлении ошибок и описывает максимальную информационную скорость, на которой возможна надежная связь по каналу, имеющему определенную вероятность ошибки или отношение сигнал / шум (SNR). Этот строгий верхний предел выражается в единицах пропускной способности канала . Более конкретно, в теореме говорится, что существуют такие коды, что с увеличением длины кодирования вероятность ошибки на дискретном канале без памяти может быть сделана сколь угодно малой при условии, что кодовая скорость меньше чем емкость канала. Кодовая скорость определяется как доля k / n из k исходных символов и n кодированных символов.
Фактическая максимальная разрешенная кодовая скорость зависит от используемого кода исправления ошибок и может быть ниже. Это связано с тем, что доказательство Шеннона носило только экзистенциальный характер и не показало, как создавать коды, которые одновременно являются оптимальными и имеют эффективные алгоритмы кодирования и декодирования.
Гибридные схемы
Гибридный ARQ — это комбинация ARQ и прямого исправления ошибок. Существует два основных подхода:
- Сообщения всегда передаются с данными четности FEC (и избыточностью для обнаружения ошибок). Получатель декодирует сообщение, используя информацию о четности, и запрашивает повторную передачу с использованием ARQ только в том случае, если данных четности было недостаточно для успешного декодирования (идентифицировано посредством неудачной проверки целостности).
- Сообщения передаются без данных четности (только с информация об обнаружении ошибок). Если приемник обнаруживает ошибку, он запрашивает информацию FEC от передатчика с помощью ARQ и использует ее для восстановления исходного сообщения.
Последний подход особенно привлекателен для канала стирания при использовании код бесскоростного стирания.
.
Схемы обнаружения ошибок
Обнаружение ошибок чаще всего реализуется с использованием подходящей хэш-функции (или, в частности, контрольной суммы, циклической проверка избыточности или другой алгоритм). Хеш-функция добавляет к сообщению тег фиксированной длины, который позволяет получателям проверять доставленное сообщение, повторно вычисляя тег и сравнивая его с предоставленным.
Существует огромное количество различных конструкций хеш-функций. Однако некоторые из них имеют особенно широкое распространение из-за их простоты или их пригодности для обнаружения определенных видов ошибок (например, производительности циклического контроля избыточности при обнаружении пакетных ошибок ).
Кодирование с минимальным расстоянием
Код с исправлением случайных ошибок на основе кодирования с минимальным расстоянием может обеспечить строгую гарантию количества обнаруживаемых ошибок, но может не защитить против атаки прообразом.
Коды повторения
A код повторения — это схема кодирования, которая повторяет биты по каналу для достижения безошибочной связи. Учитывая поток данных, которые необходимо передать, данные делятся на блоки битов. Каждый блок передается определенное количество раз. Например, чтобы отправить битовую комбинацию «1011», четырехбитовый блок можно повторить три раза, таким образом получая «1011 1011 1011». Если этот двенадцатибитовый шаблон был получен как «1010 1011 1011» — где первый блок не похож на два других, — произошла ошибка.
Код повторения очень неэффективен и может быть подвержен проблемам, если ошибка возникает в одном и том же месте для каждой группы (например, «1010 1010 1010» в предыдущем примере будет определено как правильное). Преимущество кодов повторения состоит в том, что они чрезвычайно просты и фактически используются в некоторых передачах номеров станций.
Бит четности
Бит четности — это бит, который добавляется к группе исходные биты, чтобы гарантировать, что количество установленных битов (т. е. битов со значением 1) в результате будет четным или нечетным. Это очень простая схема, которую можно использовать для обнаружения одного или любого другого нечетного числа (т. Е. Трех, пяти и т. Д.) Ошибок в выводе. Четное количество перевернутых битов сделает бит четности правильным, даже если данные ошибочны.
Расширениями и вариантами механизма битов четности являются проверки с продольным избыточным кодом, проверки с поперечным избыточным кодом и аналогичные методы группирования битов.
Контрольная сумма
Контрольная сумма сообщения — это модульная арифметическая сумма кодовых слов сообщения фиксированной длины слова (например, байтовых значений). Сумма может быть инвертирована посредством операции дополнения до единиц перед передачей для обнаружения непреднамеренных сообщений с нулевым значением.
Схемы контрольных сумм включают биты четности, контрольные цифры и проверки продольным избыточным кодом. Некоторые схемы контрольных сумм, такие как алгоритм Дамма, алгоритм Луна и алгоритм Верхоффа, специально разработаны для обнаружения ошибок, обычно вносимых людьми при записи или запоминание идентификационных номеров.
Проверка циклическим избыточным кодом
Проверка циклическим избыточным кодом (CRC) — это незащищенная хэш-функция, предназначенная для обнаружения случайных изменений цифровых данных в компьютерных сетях. Он не подходит для обнаружения злонамеренно внесенных ошибок. Он характеризуется указанием порождающего полинома, который используется в качестве делителя в полиномиальном делении над конечным полем, принимая входные данные в качестве дивиденд. остаток становится результатом.
CRC имеет свойства, которые делают его хорошо подходящим для обнаружения пакетных ошибок. CRC особенно легко реализовать на оборудовании и поэтому обычно используются в компьютерных сетях и устройствах хранения, таких как жесткие диски.
. Бит четности может рассматриваться как 1-битный частный случай. CRC.
Криптографическая хеш-функция
Выходные данные криптографической хеш-функции, также известные как дайджест сообщения, могут обеспечить надежную гарантию целостности данных, независимо от того, происходят ли изменения данных случайно (например, из-за ошибок передачи) или злонамеренно. Любая модификация данных, скорее всего, будет обнаружена по несоответствию хеш-значения. Кроме того, с учетом некоторого хэш-значения, как правило, невозможно найти некоторые входные данные (кроме заданных), которые дадут такое же хеш-значение. Если злоумышленник может изменить не только сообщение, но и значение хеш-функции, то для дополнительной безопасности можно использовать хэш-код с ключом или код аутентификации сообщения (MAC). Не зная ключа, злоумышленник не может легко или удобно вычислить правильное ключевое значение хеш-функции для измененного сообщения.
Код исправления ошибок
Для обнаружения ошибок можно использовать любой код исправления ошибок. Код с минимальным расстоянием Хэмминга, d, может обнаруживать до d — 1 ошибок в кодовом слове. Использование кодов с коррекцией ошибок на основе минимального расстояния для обнаружения ошибок может быть подходящим, если требуется строгое ограничение на минимальное количество обнаруживаемых ошибок.
Коды с минимальным расстоянием Хэмминга d = 2 являются вырожденными случаями кодов с исправлением ошибок и могут использоваться для обнаружения одиночных ошибок. Бит четности является примером кода обнаружения одиночной ошибки.
Приложения
Приложения, которым требуется низкая задержка (например, телефонные разговоры), не могут использовать автоматический запрос на повторение (ARQ); они должны использовать прямое исправление ошибок (FEC). К тому времени, когда система ARQ обнаружит ошибку и повторно передаст ее, повторно отправленные данные прибудут слишком поздно, чтобы их можно было использовать.
Приложения, в которых передатчик сразу же забывает информацию, как только она отправляется (например, большинство телекамер), не могут использовать ARQ; они должны использовать FEC, потому что при возникновении ошибки исходные данные больше не доступны.
Приложения, использующие ARQ, должны иметь канал возврата ; приложения, не имеющие обратного канала, не могут использовать ARQ.
Приложения, требующие чрезвычайно низкого уровня ошибок (например, цифровые денежные переводы), должны использовать ARQ из-за возможности неисправимых ошибок с помощью FEC.
Надежность и инженерная проверка также используют теорию кодов исправления ошибок.
Интернет
В типичном стеке TCP / IP ошибка управление осуществляется на нескольких уровнях:
- Каждый кадр Ethernet использует CRC-32 обнаружение ошибок. Фреймы с обнаруженными ошибками отбрасываются оборудованием приемника.
- Заголовок IPv4 содержит контрольную сумму , защищающую содержимое заголовка. Пакеты с неверными контрольными суммами отбрасываются в сети или на приемнике.
- Контрольная сумма не указана в заголовке IPv6, чтобы минимизировать затраты на обработку в сетевой маршрутизации и поскольку предполагается, что текущая технология канального уровня обеспечивает достаточное обнаружение ошибок (см. также RFC 3819 ).
- UDP, имеет дополнительную контрольную сумму, покрывающую полезную нагрузку и информацию об адресации в заголовки UDP и IP. Пакеты с неверными контрольными суммами отбрасываются сетевым стеком . Контрольная сумма не является обязательной для IPv4 и требуется для IPv6. Если не указано, предполагается, что уровень канала передачи данных обеспечивает желаемый уровень защиты от ошибок.
- TCP обеспечивает контрольную сумму для защиты полезной нагрузки и адресной информации в заголовках TCP и IP. Пакеты с неверными контрольными суммами отбрасываются сетевым стеком и в конечном итоге повторно передаются с использованием ARQ либо явно (например, как через тройное подтверждение ) или неявно из-за тайм-аута .
Телекоммуникации в дальнем космосе
Разработка кодов исправления ошибок была тесно связана с историей полетов в дальний космос из-за сильного ослабления мощности сигнала на межпланетных расстояниях и ограниченной мощности на борту космических зондов. В то время как ранние миссии отправляли свои данные в незашифрованном виде, начиная с 1968 года, цифровая коррекция ошибок была реализована в форме (субоптимально декодированных) сверточных кодов и кодов Рида – Маллера. Код Рида-Мюллера хорошо подходил к шуму, которому подвергался космический корабль (примерно соответствуя кривой ), и был реализован для космического корабля Mariner и использовался в миссиях между 1969 и 1977 годами.
Миссии «Вояджер-1 » и «Вояджер-2 «, начатые в 1977 году, были разработаны для доставки цветных изображений и научной информации с Юпитера и Сатурна. Это привело к повышенным требованиям к кодированию, и, таким образом, космический аппарат поддерживался (оптимально Витерби-декодированный ) сверточными кодами, которые могли быть сцеплены с внешним Голеем (24,12,  код. Корабль «Вояджер-2» дополнительно поддерживал реализацию кода Рида-Соломона. Конкатенированный код Рида – Соломона – Витерби (RSV) позволил произвести очень мощную коррекцию ошибок и позволил космическому кораблю совершить длительное путешествие к Урану и Нептуну. После модернизации системы ECC в 1989 году оба корабля использовали кодирование V2 RSV.
код. Корабль «Вояджер-2» дополнительно поддерживал реализацию кода Рида-Соломона. Конкатенированный код Рида – Соломона – Витерби (RSV) позволил произвести очень мощную коррекцию ошибок и позволил космическому кораблю совершить длительное путешествие к Урану и Нептуну. После модернизации системы ECC в 1989 году оба корабля использовали кодирование V2 RSV.
Консультативный комитет по космическим информационным системам в настоящее время рекомендует использовать коды исправления ошибок, как минимум, аналогичные RSV-коду Voyager 2. Составные коды все больше теряют популярность в космических миссиях и заменяются более мощными кодами, такими как Турбо-коды или LDPC-коды.
Различные виды выполняемых космических и орбитальных миссий. предполагают, что попытки найти универсальную систему исправления ошибок будут постоянной проблемой. Для полетов вблизи Земли характер шума в канале связи отличается от того, который испытывает космический корабль в межпланетной миссии. Кроме того, по мере того как космический корабль удаляется от Земли, проблема коррекции шума становится все более сложной.
Спутниковое вещание
Спрос на пропускную способность спутникового транспондера продолжает расти, чему способствует желание предоставлять телевидение (включая новые каналы и телевидение высокой четкости ) и данные IP. Доступность транспондеров и ограничения полосы пропускания ограничили этот рост. Емкость транспондера определяется выбранной схемой модуляции и долей мощности, потребляемой FEC.
Хранение данных
Коды обнаружения и исправления ошибок часто используются для повышения надежности носителей данных. «Дорожка четности» присутствовала на первом устройстве хранения данных на магнитной ленте в 1951 году. «Оптимальный прямоугольный код», используемый в записи с групповым кодированием, не только обнаруживает, но и корректирует однобитовые записи. ошибки. Некоторые форматы файлов, особенно архивные форматы, включают контрольную сумму (чаще всего CRC32 ) для обнаружения повреждений и усечения и могут использовать избыточность и / или четность files для восстановления поврежденных данных. Коды Рида-Соломона используются в компакт-дисках для исправления ошибок, вызванных царапинами.
Современные жесткие диски используют коды CRC для обнаружения и коды Рида – Соломона для исправления незначительных ошибок при чтении секторов, а также для восстановления данных из секторов, которые «испортились», и сохранения этих данных в резервных секторах. Системы RAID используют различные методы исправления ошибок для исправления ошибок, когда жесткий диск полностью выходит из строя. Файловые системы, такие как ZFS или Btrfs, а также некоторые реализации RAID, поддерживают очистку данных и восстановление обновлений, что позволяет удалять поврежденные блоки. обнаружены и (надеюсь) восстановлены, прежде чем они будут использованы. Восстановленные данные могут быть перезаписаны точно в том же физическом месте, чтобы освободить блоки в другом месте на том же оборудовании, или данные могут быть перезаписаны на заменяющее оборудование.
Память с исправлением ошибок
Память DRAM может обеспечить более надежную защиту от программных ошибок, полагаясь на коды исправления ошибок. Такая память с исправлением ошибок, известная как память с защитой ECC или EDAC, особенно желательна для критически важных приложений, таких как научные вычисления, финансы, медицина и т. Д., А также для приложений дальнего космоса из-за повышенное излучение в космосе.
Контроллеры памяти с исправлением ошибок традиционно используют коды Хэмминга, хотя некоторые используют тройную модульную избыточность.
Чередование позволяет распределить эффект одного космического луча, потенциально нарушающего множество физически соседние биты в нескольких словах путем связывания соседних битов с разными словами. До тех пор, пока нарушение единичного события (SEU) не превышает пороговое значение ошибки (например, одиночная ошибка) в любом конкретном слове между доступами, оно может быть исправлено (например, путем исправления однобитовой ошибки code), и может сохраняться иллюзия безошибочной системы памяти.
Помимо оборудования, обеспечивающего функции, необходимые для работы памяти ECC, операционные системы обычно содержат соответствующие средства отчетности, которые используются для предоставления уведомлений при прозрачном восстановлении программных ошибок. Увеличение количества программных ошибок может указывать на то, что модуль DIMM нуждается в замене, и такая обратная связь не была бы легко доступна без соответствующих возможностей отчетности. Одним из примеров является подсистема EDAC ядра Linux (ранее известная как Bluesmoke), которая собирает данные из компонентов компьютерной системы, поддерживающих проверку ошибок; Помимо сбора и отправки отчетов о событиях, связанных с памятью ECC, он также поддерживает другие ошибки контрольного суммирования, в том числе обнаруженные на шине PCI.
Некоторые системы также поддерживают очистку памяти.
См. также
Ссылки
Дополнительная литература
- Шу Линь; Дэниел Дж. Костелло младший (1983). Кодирование с контролем ошибок: основы и приложения. Прентис Холл. ISBN 0-13-283796-X.
Внешние ссылки

FEC: Полное имя Forward Erro Correction, которая является кодом исправления ошибок.
1. Повторите код
Отправляйте те же данные неоднократно, это повторный код.
Приемный терминал использует декодирование на основе принципа нескольких послушаний. Например: отправка от 0 до 000 закодирована. Если вы получите 001, 010 и 100, она считается 0; отправляющий терминал будет отправлен с 111 по 111. 1.
Существует большая проблема с дубликатом кода: эффективность передачи очень низкая, а эффективность передачи составляет всего 1/3.
Во -вторых, групповой код
K BITS делятся на группу, добавляя небольшое количество избыточного кода, в общей сложности N BIT. Это код залива, который обычно записывается как (n, k) Код группы.
2.1, Код школьного контроля QIQI
Самый простой отдельный код — код школьного контроля QIQI, а его код надзора — только одна цифра. Принцип состоит в том, что количество «1» в цифровом »1, передаваемом в группе двоичных кодов, подтверждено. Нечетное число называется странной проверкой, озвученной и напротив, оно называется проверкой марионеток.
Пункт: Получите 1 кодовое слово, сделайте все из них, если оно 0, правильно; если это 1, неправильно.
Странная проверка: получите 1 кодовое слово, сделайте все из них, если оно 1, правильно; если это 0, неправильно.
Код для чековой школьной школы может обнаружить только несколько ошибок. Когда возникает несколько ошибок, их нельзя обнаружить правильно.
2.2, Код Ханминга
Наиболее часто используемый (7, 4) код Hanming, информационный код составляет 4 цифры, а код надзора составляет 3.
Надзор кода надзора и элемента информационного кода выглядит следующим образом:
A2 — код испытаний марионеток A6, A5 и A4, так: A6⊕A5⊕A4⊕A2 = 0
A1 — код испытаний марионеток A6, A5 и A3, SO: A6⊕A5⊕A3⊕A1 = 0
A0 — код испытаний марионеток A6, A4 и A3, SO: A6⊕A4⊕A3⊕A0 = 0
Пройдя весь информационный код юань (4 цифры), вы можете получить 16 кодовых слов:

Принцип неправильного теста заключается в следующем:
Разное или S2, S1, S0: S2, S1, S0: S2, S1, S0:
s2=a6⊕a5⊕a4⊕a2
s1=a6⊕a5⊕a3⊕a1
s0=a6⊕a4⊕a3⊕a0
Если ошибки нет, то s2s1s0 = 000;
Если информационный код неверен:
Ошибка A6, тогда: S2S1S0 = 111;
Ошибка A5, тогда: S2S1S0 = 110;
Ошибка A4, тогда: S2S1S0 = 101;
A3 ошибка, тогда: S2S1S0 = 011.
Если элемент кода супервизора неверен:
Ошибка A2, тогда: S2S1S0 = 100;
Ошибка A1, то: S2S1S0 = 010;
Ошибка A0, тогда: S2S1S0 = 001.

После того, как биты ошибки обнаружены, пока соответствующий бит перевернут: от 0 до 1, от 1 до 0, коррекция ошибки завершена.
В -третьих, код свертки
Отдельный кодовый кодировщик вводит в k информационный код Yuan каждый раз, и вывод N -кода yuan. Код для каждого вывода связан только с введенным элементом информационного кода, и он не имеет ничего общего с информационным кодом Yuan ранее вводится Полем В дополнение к информационному коду для ввода входного ввода вывод кодекса кода напряжения также связан с информационным кодом Yuan ранее вводится. (n , k , K) , : : n : ; k : , k = 1 k : Длина ограничения, в случае k = 1, указывает на то, что выходной сигнал кодера связан с элементом кода K, введенным в этот и ранее ввод.
3.1, принцип кодирования
(N, 1, k) Обычно используется энкодер сверточного кода (K-1) для достижения уровня.
Например: (2, 1, 3) Кодировщик сверточного кода требует реестра смещения уровня 2, как показано ниже:

Ввод кода: MI, вывод: U1 и U2.
u1=mi⊕mi-1⊕mi-2
u2=mi⊕mi-2
Первоначальное состояние двух регистров смены: 00; при условии, что входная последовательность: 11011, левые данные вводятся первыми;

3.2, Диаграмма сетки Encoder
Существует 4 возможных состояния выхода двух регистров: 00, 10, 01, 11, расположенных вдоль продольной оси и используйте время в качестве горизонтальной оси.
Существует 4 возможных состояния выхода двух регистров: 00, 10, 01, 11, расположенных вдоль продольной оси и используйте время в качестве горизонтальной оси.

Реальная линия представляет вход 0, а пунктирная линия указывает вход 1.
Числа рядом с твердой и пунктирной линией указывают на выход кодера.
T1 Moment: статус регистра 00.
Время T2: если вход равен 0, состояние регистра является 00, а выходной выход равен 00; если вход составляет 1, состояние регистра — 10, а вывод Encoder 11.
T3 ВРЕМЯ: Если статус регистра 00 в предыдущий момент: если ввод равен 0, статус регистра сохраняется 00, а вывод энкодера составляет 00; если ввод равен 1, состояние регистра становится 10, а также Вывод энкодера 11. Если статус регистра в настоящее время составляет 10: если вход равен 0, состояние регистра становится 01, а энкодер выводит 10; если вход — 1, состояние регистра становится 11, а вывод энкодера 01.
T4 ВРЕМЯ: Если статус регистра 00 в предыдущий момент: если ввод равен 0, статус регистра сохраняется 00, а вывод энкодера — 00; если ввод равен 1, состояние регистра становится 10, а Вывод энкодера 11. Если статус регистра в настоящее время составляет 10: если вход равен 0, состояние регистра становится 01, а энкодер выводит 10; если вход — 1, состояние регистра становится 11, а вывод энкодера 01. Если статус регистра в настоящее время 01: если вход равен 0, состояние регистра становится 00, а энкодер выводит 11; Если вход составляет 1, состояние регистра становится 10, а вывод энкодера 00. Если состояние регистра составляет 11: если вход равен 0, состояние регистра становится 01, а энкодер выводит 01; если вход — 1, состояние регистра содержится 11, а вывод энкодера 00.
T5 Time: та же ситуация, что и T4.
T6 Moment: та же ситуация, что и T4. Возьмите входную последовательность 11011 в качестве примера. С диаграммой сетки Encoder легко получить выходную последовательность, полученную входной последовательности 11011 Кодирование: 11 01 01 00 01.

3.3, принцип декодирования
Код декодирования кода свертки обычно используется для использования максимального декодирования правдоподобия.
3.3.1 максимальное декодирование правдоподобия
Предположим, что скорость кода канала — PE, а PE <0,5. Длина последовательности входной информации энкодера равен L, а последовательность выходного кода имеет 2L возможностей: AI = (i = 1, 2, …, 2L).
После получения кодовой последовательности B декодер пересекает AI (i = 1, 2, …, 2L), вычисляет вероятность отправки последовательности кода в качестве AI и последовательности приема кода B. Последовательность отправки информации, соответствующая последовательности кода используется в результате декодирования.
Возьмите L = 5 в качестве примера. В последовательности вывода кодекса есть 32 возможности:
Если последовательность отправляющей информации составляет 11011, последовательность кодового слова из выхода кодера: 11 01 01 01 01, вся передача юаня является правильной, а вероятность этой ситуации: (1-PE) 10.
Если последовательность отправляющей информации составляет 10011, последовательность кода из выхода кодера: 11 1011 11 01, 5 Ошибки мета-трансмиссии кода. Вероятность этой ситуации: PE5 (1-PE) 5.
Если последовательность отправляющей информации составляет 11010, последовательность кодового слова из вывода энкодера: 11 01 01 00 10, 2 Ошибки передачи элемента кода, вероятность этой ситуации: PE2 (1-PE) 8.
Другие ситуации немного.
Очевидно, что вероятность отправки информационных последовательностей является самой высокой вероятностью 11011, поэтому используется результат декодирования, когда используется максимум модного мода: 11011.
Принимая l = 5 в качестве примера, предполагая, что последовательность приемного кода указана как: 11 01 01 01 01 01 Последовательность выходного кода кода в общей сложности: 32 Возможности:
Если последовательность отправляющей информации составляет 11011, последовательность кода из выхода кодера: 11 01 01 00 01, 1 Мета-трансмиссия кода, вероятность этой ситуации: PE (1-PE) 9.
Если последовательность отправляющей информации составляет 10011, последовательность кода из выхода кодера: 11 1011 11 01, 4 Ошибки мета-трансмиссии кода, вероятность этой ситуации: PE4 (1-PE) 6.
Если последовательность отправляющей информации составляет 11010, последовательность кодового слова из вывода кодера: 11 01 01 00 10, 3 Ошибки мета-трансмиссии кода, вероятность этой ситуации: PE3 (1-PE) 7.
Другие ситуации немного.
Очевидно, что вероятность отправки информационных последовательностей как 11011 является самой высокой, поэтому вывод кода декодирования с максимальным измененным декодированием: 11011.
Из двух вышеупомянутых примеров можно увидеть, что чем меньше не неправильный элемент кода, тем выше вероятность возникновения. Чтобы найти последовательность отправки с самой высокой вероятностью, просто найдите последовательность последовательности минимального количества номеров ошибок. Общее количество различных бит между двумя кодовыми символами называется расстоянием HANING, так как вы найдете последовательность последовательности минимума расстояния HANING. Например, расстояние между расстоянием расстояния между 01 и 10 составляет 2,00 и 01.
Декодирование максимального правдоподобия должно пройти через вероятность 2L -последовательности кодового слова для завершения кода декодирования. Расчет процесса декодирования увеличивается с увеличением L и увеличения индекса, чего трудно достичь. Витби обнаружил метод, который может значительно уменьшить расчет кода декодирования и подтолкнуть максимум, как мод, на практику. Это знаменитый алгоритм декодирования Витиби.
3.3.2 Witby Decoding
Принцип декодирования Витби может быть понят в сочетании с диаграммой сетки декодера.
Диаграмма сетки декодера аналогична диаграмме сетки энкодера. Единственное отличие состоит в том, что число реальной линии и пунктирной линии больше не указывает вывод энкодера, но вместо этого указывает, что последовательность слова Han и выходной код кодера энкодера последовательность яркого расстояния. Затем предыдущим примером является то, что последовательность приемного кода составляет 11 01 01 01 10 01 (ошибка 1 ярда), и нарисована диаграмма сетки декодера.
Больше контента обращает внимание на приобретение общественного счета.
