
Время на прочтение
9 мин
Количество просмотров 59K
Зачем эта статья?
Об обработке текстов на естественном языке сейчас знают все. Все хоть раз пробовали задавать вопрос Сири или Алисе, пользовались Grammarly (это не реклама), пробовали генераторы стихов, текстов… или просто вводили запрос в Google. Да, вот так просто. На самом деле Google понимает, что вы от него хотите, благодаря штукам, которые умеют обрабатывать и анализировать естественную речь в вашем запросе.
При анализе текста мы можем столкнуться с ситуациями, когда текст содержит специфические символы, которые необходимо проанализировать наравне с «простым текстом» (взять даже наши горячо любимые вставки на французском из «Война и мир») или формулы, например. В таком случае обработка текста может усложниться.
Вы можете заметить, что если ввести в поисковую строку запрос с символами с ударением (так называемый модифицирующий акут), к примеру «ó», поисковая система может показать результаты, содержащие слова из вашего запроса, символы с ударением уже выглядят как обычные символы.
Обратите внимание на следующий запрос:

Запрос содержит символ с модифицирующим акутом, однако во втором результате мы можем заметить, что выделено найденное слово из запроса, только вот оно не содержит вышеупомянутый символ, просто букву «о».
Конечно, уже есть много готовых инструментов, которые довольно неплохо справляются с обработкой текстов и могут делать разные крутые вещи, но я не об этом хочу вам поведать. Я не буду рассказывать про nltk, стемминг, лемматизацию и т.п. Я хочу опуститься на несколько ступенек ниже и обсудить некоторые тонкости кодировок, байтов, их обработки.
Откуда взялась статья?
Одним из важных составляющих в области ИИ является обработка текстов на естественном языке. В процессе изучения данной тематики я начал задавать себе вопросы, которые в конечном итоге привели меня к изучению кодировок, представлению текстов в памяти, как они преобразуются, приводятся к нормальной форме. Я плохо понимал эту тему в начале, потребовалось немало времени и мозгового ресурса, чтобы понять, принять и запомнить некоторые вещи. Написанием данной статьи я хочу облегчить жизнь людям, которые столкнутся с необходимостью чтения и обработки текстов на Python и самому закрепить изученное. А некоторыми полезными поинтами своего изучения я постараюсь поделиться в данной статье.
Важная ремарка: я не являюсь специалистом в области обработки текстов. Изложенный материал является результатом исключительно любительского изучения.
Проблема чтения файлов
Допустим, у нас есть файл с текстом. Нам нужно этот текст прочитать. Казалось бы, пиши себе такой вот скрипт для чтения из файла да и радуйся:
with open("some_text.txt", "r") as file:
content = file.read()
print(content)В файле содержится вот такое вот изречение:
pitónчто переводится с испанского как питон. Однако консоль OC Windows 10 покажет нам немного другой результат:
C:myhabrTextsInPython> python .script1.py
pitónСейчас мы разберёмся, что именно пошло не так и по какой причине.
Кодировка
Думаю, это не будет сюрпризом, если я скажу, что любой символ, который заносится в память компьютера, хранится в виде числа, а не в виде литерала. Это число определяется как идентификатор или кодовая позиция символа. Кодировка определяет, какое именно число будет ассоциировано с символом.
Предположим, у нас есть некоторый файл с неизвестным содержимым, и нам нужно его прочитать, однако мы не знаем, какая у файла кодировка. Попробуем декодировать содержимое файла.
with open("simple_text.txt", "r") as file:
text = file.read()
print(text)Посмотрим на результат:
C:myhabrTextsInPython> python .script2.py
ÿþ<♦8♦@♦Очень интересно, ничего непонятно. По умолчанию Python использует кодировку utf-8, но видимо запись в файл происходила не с её помощью. Здесь нам придёт на помощь дополнительный параметр функции open — параметр encoding, который позволяет указать конкретную кодировку, в которой следует прочитать файл (или записывать в него). Попробуем перебрать несколько кодировок и найти подходящую.
codecs = ["cp1252", "cp437", "utf-16be", "utf-16"]
for codec in codecs:
with open("simple_text.txt", "r", encoding=codec) as file:
text = file.read()
print(codec.rjust(12), "|", text)Результат:
C:myhabrTextsInPython> python .script3.py
cp1252 | ÿþ<8@
cp437 | ■<8@
utf-16be | 㰄㠄䀄
utf-16 | мирРазные кодировки расшифровывают байты из файла по-разному, то есть разным кодовым позициям могут соотвествовать разные символы. Пример примитивный, несложно догадаться, что истинная кодировка файла — это utf-16.
Важный поинт: при записи и чтении из файлов следует указывать конкретную кодировку, это позволит избежать путаницы в дальнейшем.
Ошибки, связанные с кодировками
При возникновении ошибки, связанной с кодировками, интерпретатор выдаст одно из следующих исключений:
-
UnicodeError. Это общее исключение для ошибок кодировки. -
UnicodeDecodeError. Данное исключение возбуждается, если встречается кодовая позиция, которая отсутствует в кодировке. -
UnicodeEncodeError. А это исключение возбуждается, когда символ, который необходимо закодировать, незнаком для кодировки.
Попытка выполнения вот такого кода (в файле всё ещё содержится испанский питон):
with open("some_text.txt", "r", encoding="ascii") as file:
file.read()даст нам следующий результат:
UnicodeDecodeError: 'ascii' codec can't decode byte 0xc3 in position 3: ordinal not in range(128)Кодировка ASCII не поддерживает никакой алфавит, кроме английского. Поэтому декодирование символа «ó» вызывает у ASCII сложности. Однако Python всемогущ и есть механизм, который позволяет обработать ошибки кодировок. Это дополнительный параметр методов encode и decode — параметр errors. Он может принимать следующие значения:
Для обеих функций:
|
Обозначение |
Суть |
|
|
Значение по умолчанию. Несоотвествующие кодировке символы возбуждают исключения |
|
|
Несоответсвующие символы пропускаются без возбуждения исключений. |
Только для метода encode:
|
Обозначение |
Суть |
|---|---|
|
|
Несоотвествующие символы заменяются на символ |
|
|
Несоответствующие символы заменяются на соответсвующие значения XML. |
|
|
Несоответствующие символы заменяются на определённые последовательности с обратным слэшем. |
|
|
Несоответствующие символы заменяются на имена этих символов, которые берутся из базы данных Unicode. |
Также отдельно выделены значения surrogatepass и surrogateescape.
Приведём пример использования таких обработчиков:
>>> text = "pitón"
>>> text.encode("ascii", errors="ignore")
b'pitn'
>>> text.encode("ascii", errors="replace")
b'pit?n'
>>> text.encode("ascii", errors="xmlcharrefreplace")
b'pitón'
>>> text.encode("ascii", errors="backslashreplace")
b'pit\xf3n'
>>> text.encode("ascii", errors="namereplace")
b'pit\N{LATIN SMALL LETTER O WITH ACUTE}n'Важный поинт: если в текстах могут встретиться неожиданные для кодировки символы, во избежание возбуждения исключений можно использовать обработчики.
Cворачивание регистра
Сворачивание регистра — это попытка унифицировать текст любого представления к канонической форме. Например, приведение всего текста в нижний регистр. Также над текстом производятся некоторые преобразования (например, немецкая «эсцет» — «ß» — преобразуется в «ss»). В Python 3.3 появился метод str.casefold(), который как раз выполняет сворачивание регистра. Если текст содержит только символы кодировки latin1, результат применения этого метода будет аналогичен методу str.lower().
И по классике приведём пример:
>>> text = "Die größte Stadt der Welt liegt in China"
>>> text.casefold()
'die grösste stadt der welt liegt in china'В результате применённый метод не только привёл весь текст к нижнему регистру, но и преобразовал специфический немецкий символ.
Важный поинт: привести текст можно не только методом str.lower(), но и методом str.casefold(), который может выполнить дополнительные преобразования текста.
Нормализация
Нормализация — это полноценное приведение текста к единому представлению.
Чтобы обозначить важность нормализации, приведём простой пример:
letter1 = "µ"
letter2 = "μ"Внешне два этих символа выглядят абсолютно одинаково. Однако если мы попытаемся вывести имена этих символов, как их видит интерпретатор Python’a, результат нас порядком удивит.
В Python есть отличный встроенный модуль, который содержит данные о символах Unicode, их имена, являются ли они цифрамии и т.п. (методы по типу str.isdigit() берут информацию из этих данных). Воспользуемся данным модулем, чтобы вывести имена символов, исходя из информации, которая содержится в базе данных Unicode.
import unicodedata
letter1 = "µ"
letter2 = "μ"
print(unicodedata.name(letter1))
print(unicodedata.name(letter2))Результат выполнения данного кода:
C:myhabrTextsInPython> python .script7.py
MICRO SIGN
GREEK SMALL LETTER MUИтак, интерпретатор Python’a видит эти символы как два разных, но в стандарте Unicode они имеют одинаковое отображение.Такие символы называют каноническими эквивалентами. Приложения будут считать два этих символа одинаковыми, но не интерпретатор.
Посмотрим на ещё один пример:
>>> s1 = 'café'
>>> s2 = 'cafeu0301'
>>> s1, s2
('café', 'café')
>>> s1 == s2
False
>>> len(s1), len(s2)
(4, 5)
Данные символы также будут являться каноническими эквивалентами. Из примера мы видим, что символ «é» в стандарте Unicodeможет быть представлен двумя способами, которые к тому же имеют разную длину. Символ «é» может быть представлен одним или двумя байтами.
Решением таких конфликтов занимается нормализация. Она реализована в Python в функции unicodedata.normalize.Первым аргумент является так называемая форма нормализации — нормализации строк Unicode, которые позволяют определить, эквивалентны ли какие-либо две строки Unicode друг другу. Всего предлагается четыре формы:
|
Форма |
Описание |
|---|---|
|
Normalization Form D (NFD) |
Canonical Decomposition |
|
Normalization Form C (NFC) |
Canonical Decomposition, следующая за Canonical Composition |
|
Normalization Form KD (NFKD) |
Compatibility Decomposition |
|
Normalization Form KC (NFKC) |
Compatibility Decomposition, следующая за Canonical Composition |
Разберём каждую форму немного подробнее.
-
NFC
При указании данной формы нормализации происходит каноническая композиция (как, собственно, и гласит название) кодовых позиций с целью получения самой короткой эквивалентной строки.
>>> unicodedata.normalize("NFC", s1), unicodedata.normalize("NFC", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFC", s1)), len(unicodedata.normalize("NFC", s2))
(4, 4)
>>> unicodedata.normalize("NFC", s1) == unicodedata.normalize("NFC", s2)
True
>>> len(unicodedata.normalize("NFC", s1)) == len(unicodedata.normalize("NFC", s2))
TrueИтак, нормализация обеих строк внешне их не изменила, однако длина строки s2 стала равной 4 (т.е. на один байт меньше). Была произведена композиция байтов eu0301, которые являлись отображением «é». Данная последовательность была заменена на минимальное представление символа, т.е. теперь представление этого символа для интерпретатора выглядит как в строке s1. Как результат, мы видим, что длина нормализованных строк стала равной, и сами строки также стали равны.
-
NFD
С этой формой ситуация аналогичная, только происходит декомпозиция байтов, т.е. разложение символа на несколько байт.
>>> unicodedata.normalize("NFD", s1), unicodedata.normalize("NFD", s2)
('café', 'café')
>>> len(unicodedata.normalize("NFD", s1)), len(unicodedata.normalize("NFD", s2))
(5, 5)
>>> unicodedata.normalize("NFD", s1) == unicodedata.normalize("NFD", s2)
True
>>> len(unicodedata.normalize("NFD", s1)) == len(unicodedata.normalize("NFD", s2))
TrueЗдесь мы видим, что длина строки s1 увеличилась на один байт. Думаю, уже несложно догадаться, почему.
На данном этапе настал момент ввести понятие символа совместимости. Символы совместимости (compatibility characters) были введены в Unicode ради совместимости с другими стандартами, в частности, стандарты, которые предшествовали Unicode. Это означает, что некоторые символы могут встречаться в стандарте несколько раз. Мы уже могли наблюдать это явление в начале этого раздела на примере с символом «мю». Он считается символом совместимости.
-
NFKC и NFKD
При данных формах нормализации символы совместимости заменяются на его более предпочтительное представление, что также называется совместимой декомпозицией. Однако при данных формах нормализации может быть потеряно форматирование.
Немного модифицируем наш пример из начала раздела. Выведем кодовые позиции символов до и после нормализации:
import unicodedata
letter1 = "µ"
letter2 = "μ"
print("Before normalizing:", ord(letter1), ord(letter2))
letter1 = unicodedata.normalize("NFKC", letter1)
letter2 = unicodedata.normalize("NFKC", letter2)
print("After normalizing:", ord(letter1), ord(letter2))И результат выполнения кода:
Before normalizing: 181 956
After normalizing: 956 956Итак, мы видим, что первый символ (который являлся знаком «микро») был заменён на греческую «мю», т.е. более предпочтительное представление символа. Таким образом, если необходимо, например, провести частотный анализ текста, формы нормализации, которые затрагивают символы совместимости, могут помочь с этим, приводя символы совместимости к единому представлению.
Важный поинт: нормализация может очень помочь для поиска валидных документов или индексирования текста. Если вы занимаетесь разработкой таких систем, не стоит сбрасывать алгоритмы нормализации со счетов.
Дополнительные материалы: что использовалось в статье и что почитать по теме
«Fluent Python», Лучано Ромальо
В этой книге целая глава посвящена изучению строк, байтов и Unicode (Глава 4. Тексты и байты). Она есть на русском и английском языках, но в русском переводе допущено немало ошибок, так что открывайте русский вариант на свой страх и риск. Материал статьи в большей степени опирается на данную книгу. Некоторые примеры также взяты оттуда.
Документация для Unicode на официальном сайте Python
Куда ж без неё, родимой. Там тоже можно найти немало полезной информации, если вам понадобится работать с текстами и делать больше, чем просто считывание из файла. Хотя в некоторых случаях и на этом можно споткнуться.
Unicode® Standard Annex
Это части стандарта Unicode, которые выложены в открытый доступ в виде отдельных статей. Почитать их можно вот здесь.
Во время работы с компьютером пользователи часто сталкиваются с ошибкой енкодинга. Эта ошибка возникает при неправильном преобразовании символов текста в последовательность байтов и обратно. В результате текст может отображаться некорректно или выглядеть искаженным. Проблема часто возникает при работе с файлами, содержащими текст на разных языках или символах.
Ошибка енкодинга может привести к проблемам при написании кода, обработке текстовой информации, работе с базами данных и передаче данных через интернет. Для ее исправления необходимо понимать, какое кодирование используется в файле и как правильно преобразовать символы текста. В статье мы расскажем о наиболее распространенных видов енкодинга, ошибок, связанных с ними, и способах их решения.
Если вы столкнулись с ошибкой енкодинга, не стоит беспокоиться: проблему можно решить самостоятельно или обратиться за помощью к специалисту. Важно понимать, что важность правильной обработки текстовой информации и передачи данных в интернете растет с каждым годом. Наши рекомендации помогут вам избежать проблем с кодированием и сделают работу с текстом более удобной и эффективной.
Содержание
- Ошибка енкодинга
- Что это значит?
- Как обнаружить ошибку?
- Какие причины могут вызывать ошибку енкодинга?
- Как исправить ошибку енкодинга?
- Какие меры предпринять, чтобы избежать ошибки енкодинга в будущем?
- Какие последствия могут быть, если не исправлять ошибку енкодинга?
- Можно ли избежать ошибки енкодинга при написании кода?
- Вопрос-ответ
- Как определить, что у меня ошибка енкодинга?
- Какие методы исправления ошибки енкодинга существуют?
- Почему возникает ошибка енкодинга и как ее избежать?
Ошибка енкодинга
Ошибка енкодинга — это проблема, возникающая при попытке открыть или отобразить содержимое файла или веб-страницы, который содержит специальные символы, непонятные компьютеру.
В большинстве случаев это связано с несоответствием формата кодировки текста, поэтому символы не могут быть интерпретированы правильным образом.
Ошибка енкодинга может изображаться на экране в виде знаков вопросов, иероглифов или других неожиданных символов.
Чтобы исправить ошибку енкодинга, необходимо установить соответствующий формат кодировки для текста. Также можно использовать специальные инструменты и программы, которые автоматически определяют формат кодировки текста и исправляют ошибку.
Ошибка енкодинга может стать серьезной проблемой для веб-разработчиков и владельцев сайтов, так как может привести к потере данных и ухудшению пользовательского опыта. Поэтому важно уделить внимание правильному формату кодировки текста при создании веб-страниц и обновлении контента.
Что это значит?
Ошибка енкодинга – это проблема, связанная с неправильным преобразованием символов в текстовом файле. Часто такая ошибка возникает, когда в документе используется неподдерживаемая кодировка или когда файл был сохранен в неправильной кодировке.
Результатом ошибки енкодинга может быть неправильное отображение текста на веб-странице или в программе, причем глюки могут возникать на любых этапах обработки документа. Это может привести к тому, что текст становится нечитабельным и теряет свой смысл.
Чтобы избежать таких ошибок, необходимо быть внимательным при работе с кодировками и стараться использовать широко поддерживаемые стандарты. Также можно использовать специальные программы и сервисы, которые помогают определить и исправить ошибки енкодинга.
- Рекомендации по исправлению ошибок енкодинга:
- Убедитесь, что вы используете правильную кодировку для текущего документа.
- Перекодируйте документ в правильную кодировку, если он был сохранен в неправильной кодировке.
- Используйте дополнительные инструменты и сервисы для определения и исправления ошибок енкодинга.
Как обнаружить ошибку?
Проверьте кодировку страницы
Чтобы убедиться, что кодировка страницы соответствует той, которую вы планировали использовать, проверьте кодировку в заголовке HTML-документа. В наиболее распространенных текстовых редакторах можно также проверить кодировку и в настройках файла.
Проверьте содержимое страницы
Если вы заметили, что на странице есть посторонние символы, либо неправильно отображаются определенные буквы или слова, то, скорее всего, проблема с кодировкой.
Используйте инструменты для проверки
Существует множество инструментов, которые могут помочь выявить ошибку енкодинга на вашей странице. Вы можете воспользоваться, например, браузерными дополнениями или онлайн-сервисами для проверки кодировки вашей страницы.
Свяжитесь с разработчиками
Если вы не можете самостоятельно исправить ошибку енкодинга, свяжитесь с разработчиками своего сайта или обратитесь в техническую поддержку. Возможно, они смогут оказать вам помощь и исправить проблему.
Какие причины могут вызывать ошибку енкодинга?
1. Неверная настройка сервера. Если сервер настроен не правильно, возможно некорректное отображение символов в кодировке, отличной от той, которая была указана в HTML.
2. Отсутствие заданной кодировки на странице. Если на странице нет указания на используемую кодировку, то браузер должен угадывать, какая кодировка была использована, что может привести к некорректному отображению.
3. Разные кодировки в файле HTML и файле CSS. Если файл HTML и файл CSS имеют разную кодировку, то передача информации будет проходить некорректно и отображение будет неверным.
4. Некорректное использование специальных символов. Использование специальных символов, не являющихся частью используемой кодировки, может привести к отображению их как непонятных символов вместо оригинала.
5. Ошибки при выгрузке текста из базы данных. Некорректная выгрузка текста из базы данных может привести к ошибке енкодинга и неверной отображению символов на странице.
Как исправить ошибку енкодинга?
Ошибки енкодинга могут возникать в результате отсутствия соответствия кодировок в тексте и на сервере, либо при использовании неверных настроек браузера. При этом вместо ожидаемых символов могут появляться кракозябры или иероглифы, что затрудняет правильное чтение контента.
Для исправления ошибки енкодинга необходимо сначала определить тип кодировки используемого текста. Для этого можно воспользоваться специальными сервисами проверки кодировок, такими как «Notepad++» или «Sublime Text».
Далее, если кодировки не совпадают, нужно преобразовать текст в нужную кодировку. Это можно сделать, например, через программу «WinMerge», которая позволяет сравнивать тексты в разных кодировках и переводить их в нужный формат.
Если ошибка енкодинга связана с браузером, то можно попробовать изменить настройки языковых предпочтений. Для этого нужно перейти в настройки браузера и выбрать нужную кодировку в параметрах языковых настроек.
В любом случае, для исправления ошибки енкодинга нужно тщательно изучить причину возникновения проблемы и подходящим образом изменить настройки соответствующих программ и устройств.
Какие меры предпринять, чтобы избежать ошибки енкодинга в будущем?
Предупредить ошибку енкодинга можно, в первую очередь, тщательно проводя подготовительную работу:
- Следите за кодировкой файлов, которые используете в своей работе. Для создания новых файлов рекомендуется использовать UTF-8 — наиболее распространенную кодировку в Интернете;
- Проверяйте настройки сервера — задайте нужную кодировку в конфигурационных файлах Вашего веб-сайта;
- При загрузке данных через HTML-формы убедитесь, что задана нужная кодировка;
- Удачно выбирайте библиотеки и инструменты для работы с текстом и базами данных — они должны поддерживать нужную кодировку.
Далее, рекомендуется регулярно проверять свой веб-сайт на наличие ошибок енкодинга. Существуют специальные онлайн-сервисы, которые помогут быстро определить наличие ошибок и помогут их исправить.
Также, если Вы владеете веб-сайтом, то лучше сообщать посетителям Вашего ресурса, какую кодировку предпочитаете использовать. Для этого можно добавить информацию в файл htaccess на сервере.
Будьте внимательны при работе с различными языками и инструментами — не забывайте про проверку кодировки!
Какие последствия могут быть, если не исправлять ошибку енкодинга?
Ошибка енкодинга может привести к некорректному отображению текста на сайте или в приложении. Вместо букв и символов могут появляться кракозябры, что затрудняет восприятие информации и создает плохое впечатление о вашем сайте или продукте в целом.
Если ошибки енкодинга не исправлять, то это может отразиться на рейтинге сайта в поисковых системах, так как некоторые поисковые системы не смогут правильно считать содержимое страницы и, соответственно, не будут рекомендовать ее в выдаче.
Кроме того, если пользователи не смогут правильно прочитать информацию на вашем сайте, это может привести к уменьшению пользовательской активности и ухудшению конверсии. Многие пользователи могут просто закрыть страницу, не решившись приобрести ваш продукт или воспользоваться услугой.
Итак, исправление ошибок енкодинга является неотъемлемой частью разработки и поддержки веб-сайтов и приложений, поскольку это влияет на качество предоставляемой информации и удобство пользования продуктом.
Можно ли избежать ошибки енкодинга при написании кода?
Для того, чтобы избежать ошибки енкодинга при написании кода, необходимо убедиться, что все используемые символы соответствуют выбранной кодировке. Рекомендуется использовать UTF-8 — наиболее распространенную кодировку в сети.
Кроме того, при работе с базами данных необходимо убедиться, что они используют ту же самую кодировку, что и ваш код. Если база данных использует другую кодировку, это может привести к ошибкам при сохранении и отображении данных.
Еще одним важным моментом является использование правильных заголовков страницы. Необходимо убедиться, что в теле документа присутствует элемент <meta charset=»utf-8″>, который указывает браузеру на то, что страницу необходимо отображать в определенной кодировке.
Важно также никогда не копировать текст из других источников, если вы не уверены в его кодировке. Если вы все же используете копированный текст, то необходимо убедиться в корректности его кодировки и, при необходимости, преобразовать его в нужную кодировку с помощью соответствующих инструментов.
Вопрос-ответ
Как определить, что у меня ошибка енкодинга?
Ошибка енкодинга проявляется в виде непонятных символов или кракозябр вместо ожидаемых букв и знаков препинания. Проверить ее наличие можно, открыв страницу в браузере или просмотрев текстовый файл.
Какие методы исправления ошибки енкодинга существуют?
Существует несколько методов исправления ошибки енкодинга в зависимости от ее причины. Например, можно попробовать изменить кодировку файла, либо воспользоваться специальными программами для его автоматической корректировки. Также может помочь пересохранение файла в другом формате или замена неправильных символов на правильные вручную.
Почему возникает ошибка енкодинга и как ее избежать?
Ошибка енкодинга может возникать по разным причинам, например, при работе с файлами, сохраненными в неправильной кодировке, либо при попытке открыть файл, содержащий символы из другой кодировки. Чтобы избежать такой ошибки стоит следить за правильным выбором кодировки при сохранении файлов, а также использовать универсальные кодировки, поддерживающие символы всех языков мира.
![]() Официальный сертифицированный
Официальный сертифицированный
хостинг для продуктов 1С Битрикс
Ошибка кодировки таблиц без возможности автоматического исправления
19.04.2023
В случае появления ошибки при проверке системы (тестирование конфигурации): «Ошибка! Кодировки таблиц имеют ошибки, общее число ошибок N, из них автоматически могут быть исправлены: 0» требуется:
- Выполнить резервное копирование базы данных сайта перед началом проведения процедуры во избежание получения неисправимых ошибок в случае неверных действий.
- Кликнуть на иконку вопросительного знака в правой части строки с вышеуказанной ошибкой.
- В открывшемся окне кликнуть по ссылке «Подробности в журнале проверки системы».
- На экране будет отображен список ошибок по каждой таблице и полям с неверной кодировкой. Скопируйте все строки с ошибками кодировки.
- Вставьте текст с ошибками в расширенный текстовый редактор, например Notepad++ (Windows) или Sublime Text (Mac).
- Удалите все строки, где указаны ошибки кодировки в полях. Оставьте только строки с ошибками таблиц.
Например, из текста ошибок:
Кодировка таблицы «b_b24connector_button_site» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «SITE_ID» таблицы «b_b24connector_button_site» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VENDOR_EVENT_ID» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «SYNC_STATUS» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «ENTITY_TAG» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VERSION» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VENDOR_VERSION_ID» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «RECURRENCE_ID» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «DATA» таблицы «b_calendar_event_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VENDOR_SECTION_ID» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «SYNC_TOKEN» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «PAGE_TOKEN» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «ACTIVE» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «LAST_SYNC_STATUS» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «VERSION_ID» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «IS_PRIMARY» таблицы «b_calendar_section_connection» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы «b_catalog_exported_product» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «SERVICE_ID» таблицы «b_catalog_exported_product» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка поля «ERROR» таблицы «b_catalog_exported_product» (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы «b_catalog_exported_product_queue» (utf8mb4) отличается от кодировки базы (utf8)
Должен получиться следующий текст:
Кодировка таблицы b_b24connector_button_site (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы b_calendar_event_connection (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы b_calendar_section_connection (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы b_catalog_exported_product (utf8mb4) отличается от кодировки базы (utf8)
Кодировка таблицы b_catalog_exported_product_queue (utf8mb4) отличается от кодировки базы (utf8)
Затем требуется оставить только названия таблиц. Должно получиться:
b_b24connector_button_site
b_calendar_event_connection
b_calendar_section_connection
b_catalog_exported_product
b_catalog_exported_product_queue
После необходимо добавить следующие запросы в начало строк и после названия таблиц: ALTER TABLE — CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
Должен получиться следующий текст:
ALTER TABLE b_b24connector_button_site CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE b_calendar_event_connection CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE b_calendar_section_connection CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE b_catalog_exported_product CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
ALTER TABLE b_catalog_exported_product_queue CONVERT TO CHARACTER SET utf8 COLLATE utf8_unicode_ci;
Копируем получившийся результат. Затем переходим в раздел администраторской части сайта «SQL запрос» и в текстовое поле вставляем ранее скопированный текст результата. Нажать кнопку «Выполнить запрос».
Таким образом одновременно выполняется множество запросов по изменению кодировки таблиц базы данных для исправления ошибки.
Концепция и все материалы с сайта btrxboost.com включающие в себя текстовую, графическую, видео, аудио и маркетинговую информацию, защищены российским и международным законодательством. В соответствии с соглашением об охране авторских прав и интеллектуальной собственности (ст. №1259, №1260, гл. 70 “Авторское право” ГК РФ от 18.12.2006 № 230-ФЗ) и согласно сертификату собственности авторских прав на информационные материалы RID 07N-4M-48 от 12.08.2012, а также сертификата DMCA id: f25cb914-aba8-4988-a116-13afb399bba2 от 21.06.2019.
В случае нарушений данных правил, применяются следующие меры: подача официального заявления в судебные органы в т.ч. с эскалацией запроса хостинг-провайдеру на котором расположен сайт-нарушитель, а также подача запроса на исключение сайта-нарушителя из поисковых систем согласно “Online Copyright Infringement Liability Limitation Act” по ч. II, раздел 512 к закону об авторском праве по DMCA.
На чтение 2 мин Просмотров 677 Опубликовано 8 октября, 2013

Иногда открыв файл, созданный при помощи Microsoft Word и присланный нам по почте, скайпу или другим способом, мы вместо привычных русских слов видим какие-то странные иероглифы. Мы недоумеваем, что же такое нам прислали, связываемся с отправителем, а он говорит, что у него все нормально открывается. Суть данной проблемы скорее всего состоит в том, что файл был сохранен не в той кодировке, что стоит по умолчанию в вашей программе. Чтобы исправить ситуацию необходимо всего лишь поменять кодировку файла и сейчас мы узнаем, как это сделать.
В данном примере будет использоваться Microsoft Word 2010 но принцип решения нашей задачи будет таким же и во всех остальных версиях программы. Итак, открываем наш «проблемный» документ, переходим в меню Файл и нажимаем на пункте Параметры.
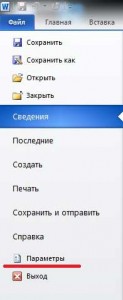
Далее переходим во вкладку Дополнительно и в разделе Общие ставим галочку напротив пункта Подтверждать преобразование формата файла при открытии.
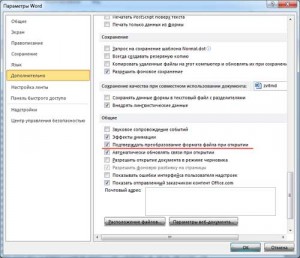
Нажимаем Ок и закрываем наш документ. Затем снова открываем его и перед нами должно появится окошко Преобразование файла, в нем нам нужно выбрать пункт Кодированный текст.
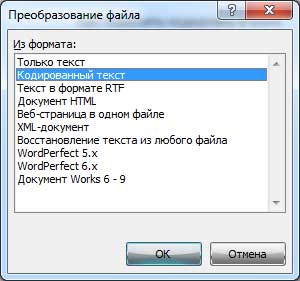
После этого появится другое окно, в котором нам нужно будет выбрать кодировку для своего файла. Ставим галочку на пункте Другая и в поле выбора пробуем методом перебора различные кодировки, до тех пор пока не получим результат. В окне Результат вы можете увидеть, как меняется текст в зависимости от выбранной вами кодировки.
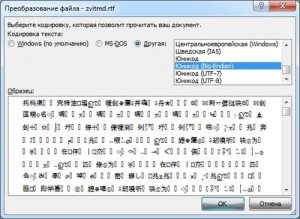
Если вышеописанный метод не помог исправить проблему, то возможно она кроется не в неправильной кодировке, а в отсутствии на вашем компьютере шрифта, с использованием которого создавался данный документ. В таком случае вам придется уточнить у отправителя документа название шрифта и установить нужный шрифт на свой компьютер.
В обслуживание компьютеров юридических лиц входит: посещение специалиста в ваш офис, тест оборудования, монтаж оборудования, регулировка ОС оборудования и многое другое.
А если возникла повреждение нетбука, мы занимаемся ремонтом ноутбуков.
Back to top
Toggle table of contents sidebar
Ошибки при конвертации#
При конвертации между строками и байтами очень важно точно знать, какая
кодировка используется, а также знать о возможностях разных кодировок.
Например, кодировка ASCII не может преобразовать в байты кириллицу:
In [32]: hi_unicode = 'привет' In [33]: hi_unicode.encode('ascii') --------------------------------------------------------------------------- UnicodeEncodeError Traceback (most recent call last) <ipython-input-33-ec69c9fd2dae> in <module>() ----> 1 hi_unicode.encode('ascii') UnicodeEncodeError: 'ascii' codec can't encode characters in position 0-5: ordinal not in range(128)
Аналогично, если строка «привет» преобразована в байты, и попробовать
преобразовать ее в строку с помощью ascii, тоже получим ошибку:
In [34]: hi_unicode = 'привет' In [35]: hi_bytes = hi_unicode.encode('utf-8') In [36]: hi_bytes.decode('ascii') --------------------------------------------------------------------------- UnicodeDecodeError Traceback (most recent call last) <ipython-input-36-aa0ada5e44e9> in <module>() ----> 1 hi_bytes.decode('ascii') UnicodeDecodeError: 'ascii' codec can't decode byte 0xd0 in position 0: ordinal not in range(128)
Еще один вариант ошибки, когда используются разные кодировки для
преобразований:
In [37]: de_hi_unicode = 'grüezi' In [38]: utf_16 = de_hi_unicode.encode('utf-16') In [39]: utf_16.decode('utf-8') --------------------------------------------------------------------------- UnicodeDecodeError Traceback (most recent call last) <ipython-input-39-4b4c731e69e4> in <module>() ----> 1 utf_16.decode('utf-8') UnicodeDecodeError: 'utf-8' codec can't decode byte 0xff in position 0: invalid start byte
Наличие ошибок — это хорошо. Они явно говорят, в чем проблема.
Хуже, когда получается так:
In [40]: hi_unicode = 'привет' In [41]: hi_bytes = hi_unicode.encode('utf-8') In [42]: hi_bytes Out[42]: b'xd0xbfxd1x80xd0xb8xd0xb2xd0xb5xd1x82' In [43]: hi_bytes.decode('utf-16') Out[43]: '뿐胑룐닐뗐苑'
Обработка ошибок#
У методов encode и decode есть режимы обработки ошибок, которые
указывают, как реагировать на ошибку преобразования.
Параметр errors в encode#
По умолчанию encode использует режим strict — при возникновении ошибок
кодировки генерируется исключение UnicodeError. Примеры такого поведения
были выше.
Вместо этого режима можно использовать replace, чтобы заменить символ
знаком вопроса:
In [44]: de_hi_unicode = 'grüezi' In [45]: de_hi_unicode.encode('ascii', 'replace') Out[45]: b'gr?ezi'
Или namereplace, чтобы заменить символ именем:
In [46]: de_hi_unicode = 'grüezi' In [47]: de_hi_unicode.encode('ascii', 'namereplace') Out[47]: b'gr\N{LATIN SMALL LETTER U WITH DIAERESIS}ezi'
Кроме того, можно полностью игнорировать символы, которые нельзя
закодировать:
In [48]: de_hi_unicode = 'grüezi' In [49]: de_hi_unicode.encode('ascii', 'ignore') Out[49]: b'grezi'
Параметр errors в decode#
В методе decode по умолчанию тоже используется режим strict и
генерируется исключение UnicodeDecodeError.
Если изменить режим на ignore, как и в encode, символы будут просто
игнорироваться:
In [50]: de_hi_unicode = 'grüezi' In [51]: de_hi_utf8 = de_hi_unicode.encode('utf-8') In [52]: de_hi_utf8 Out[52]: b'grxc3xbcezi' In [53]: de_hi_utf8.decode('ascii', 'ignore') Out[53]: 'grezi'
Режим replace заменит символы:
In [54]: de_hi_unicode = 'grüezi' In [55]: de_hi_utf8 = de_hi_unicode.encode('utf-8') In [56]: de_hi_utf8.decode('ascii', 'replace') Out[56]: 'gr��ezi'